Scrapy爬虫框架第一讲(Linux环境)
1、What is Scrapy?

答:Scrapy是一个使用python语言(基于Twistec框架)编写的开源网络爬虫框架,其结构清晰、模块之间的耦合程度低,具有较强的扩张性,能满足各种需求。(前面我们介绍了使用requests、beautifulsoup、selenium等相当于你写作文题,主要针对的是个人爬虫;而Scrapy框架的出现给了我们一个方便灵活爬虫程序架构,我们只需针对其中的组件做更改,即可实现一个完美的网络爬虫,相当于你做填空题!)
基于Scrapy的使用方便性,下面所有的Scrapy程序我们都会在Linux系统下运行
2、Scrapy框架的安装(这里我使用的是vmware虚拟机+ubuntu16.04镜像环境)
打开终端:sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev(安装一些依赖包)
如果你没安装python3请执行:sudo apt-get install python3 python3-dev
这里小伙伴们可以先创建一个虚拟环境:pip3 install virtualenv 再进行scrapy 的安装(之后你写的所有程序都会在虚拟环境中运行)
基于我使用的是ubuntu16.04版本,系统自带了python2.7.14 和python3.5.2两个版本
下面小伙们让我们先来解决一个多版本的共存问题吧
当你输入python时系统会自动指向python2,而我们的所有程序是基于python3 的,这也是以后的主流。(我们要的是输入python,系统直接链接到python3)

下面我们来解决这个问题:sudo su (输入你设置等待用户密码进入超级用户权限)---接着请看图:
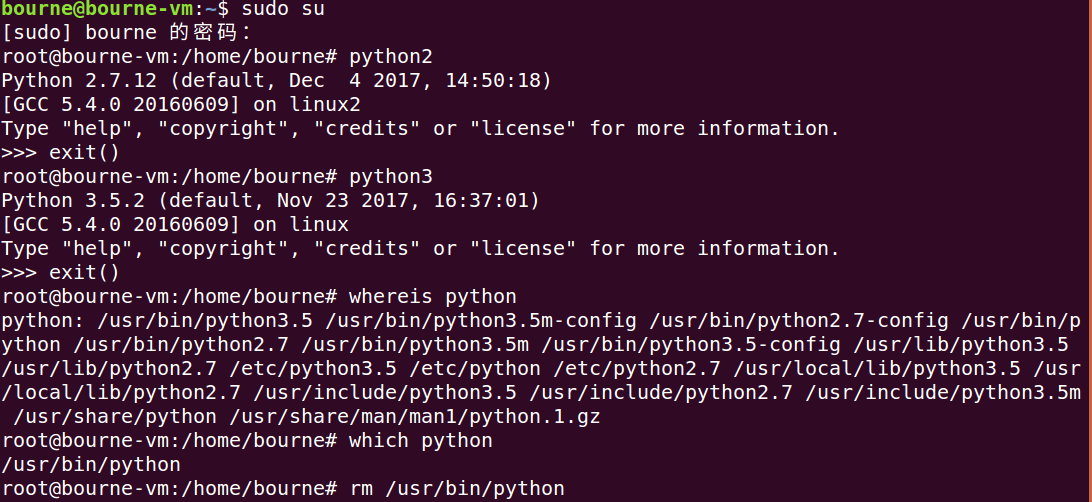
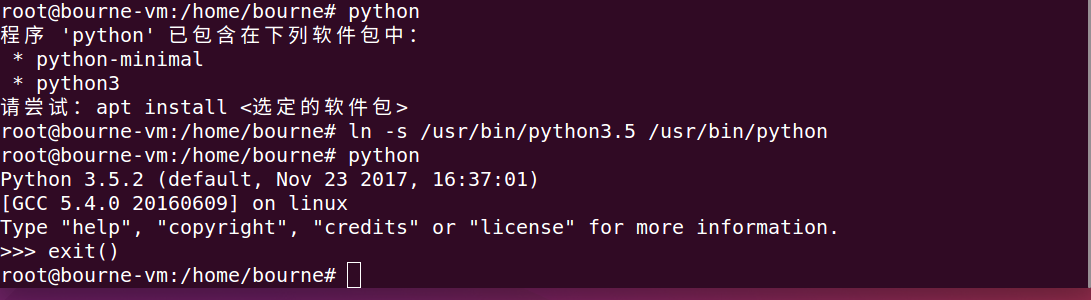
分析:(linux命令小伙伴们我们以后再谈)
当我们键入python2 系统自动指向python2环境,python3同样如此
whereis python 找出了python的所有可执行文件的路径
which python 找出了当我们键入python时执行的文件路径
我们使用rm 首先删除了该路径,接着使用 ln -s 参数1 参数2 (将参数1 指向 参数2 这里相当于生成了软链接原理和超链接一样,当你键入python时系统自动指向了软连接 python3的可执行文件的路径并执行文件),这样我们成功的达到了预想目的
3、如何解决同时使用多个python版本和同时使用多个库版本的问题
答:安装virtualenv虚拟环境
打开终端:sudo pip3 install virtualenv
如果出现以下错误请使用 vi /usr/bin/pip3 更改配置文件(这是因为原来我们是python2的pip当你升级后系统没改配置文件,小伙伴们不要紧张,我们自己修改即可)

这里涉及到linux下强大的文本编辑器vim的使用我们下次专门讲解
更改配置文件如下:
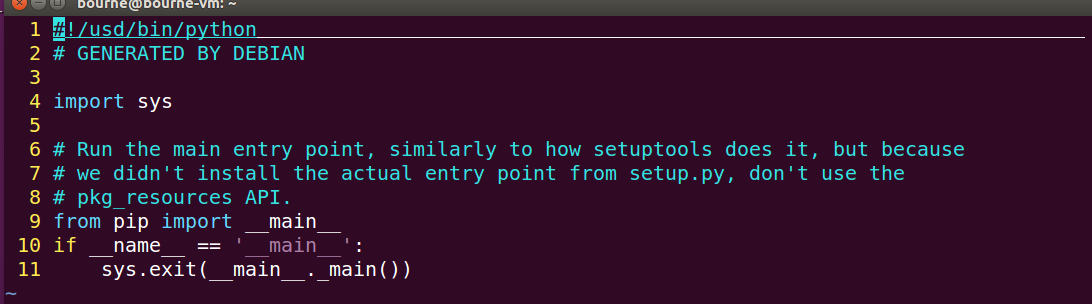
再次键入:sudo pip3 install virtualenv (成功)
接着:

创建名叫course-python3.5-env 的python3.5虚拟环境:如上图
激活与推出虚拟环境 source 与 deactivate 命令

最后我们按照前述,首先激活虚拟环境,然后安装Scrapy即可
验证:终端键入:scrapy --version查看安装的scapy版本,不报错即可!
以后我们所有的scrapy爬虫项目都在虚拟环境下运行了!
Scrapy爬虫框架第一讲(Linux环境)的更多相关文章
- 手把手教你如何新建scrapy爬虫框架的第一个项目(上)
前几天给大家分享了如何在Windows下创建网络爬虫虚拟环境及如何安装Scrapy,还有Scrapy安装过程中常见的问题总结及其对应的解决方法,感兴趣的小伙伴可以戳链接进去查看.关于Scrapy的介绍 ...
- Python之Scrapy爬虫框架安装及简单使用
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- Python爬虫教程-31-创建 Scrapy 爬虫框架项目
本篇是介绍在 Anaconda 环境下,创建 Scrapy 爬虫框架项目的步骤,且介绍比较详细 Python爬虫教程-31-创建 Scrapy 爬虫框架项目 首先说一下,本篇是在 Anaconda 环 ...
- Python-S9-Day126——Scrapy爬虫框架
01 今日内容概要 02 内容回顾和补充:scrapy 03 内容回顾和补充:网络和并发编程 04 Scrapy爬虫框架:pipeline做持久化(一) 05 Scrapy爬虫框架:pipeline做 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影
前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大家讲解一个完整爬虫的流程. 工具和环境 语言:python 2 ...
- Scrapy爬虫框架(实战篇)【Scrapy框架对接Splash抓取javaScript动态渲染页面】
(1).前言 动态页面:HTML文档中的部分是由客户端运行JS脚本生成的,即服务器生成部分HTML文档内容,其余的再由客户端生成 静态页面:整个HTML文档是在服务器端生成的,即服务器生成好了,再发送 ...
- python3.7.1安装Scrapy爬虫框架
python3.7.1安装Scrapy爬虫框架 环境:win7(64位), Python3.7.1(64位) 一.安装pyhthon 详见Python环境搭建:http://www.runoob.co ...
- 安装scrapy 爬虫框架
安装scrapy 爬虫框架 个人根据学习需要,在Windows搭建scrapy爬虫框架,搭建过程种遇到个别问题,共享出来作为记录. 1.安装python 2.7 1.1下载 下载地址 1.2配置环境变 ...
随机推荐
- 【Unity Shaders】概述及Diffuse Shading介绍
本系列主要参考<Unity Shaders and Effects Cookbook>一书(感谢原书作者),同时会加上一点个人理解或拓展. 这里是本书所有的插图.这里是本书所需的代码和资源 ...
- C语言实现的猜数字小游戏(主要是对于自定义函数的运用)
#include <stdio.h> #include <stdlib.h> #include<time.h>//加上此头文件的作用是什么?另外不加的话有什么影响? ...
- 高通 MSM8K bootloader 之四: ramdump
前面说过高通平台,系统crash发生时,抓取crash ramdump非常重要,否则很难定位crash原因. 平台默认抓取ramdump的方法都有很强的局限性,如下: 1.PC端工具QPST提供的 M ...
- UVa - 102 - Ecological Bin Packing
Background Bin packing, or the placement of objects of certain weights into different bins subject t ...
- mysql进阶(二十一)删除表数据
MySQL删除表数据 在MySQL中有两种方法可以删除数据,一种是DELETE语句,另一种是TRUNCATE TABLE语句.DELETE语句可以通过WHERE对要删除的记录进行选择.而使用TRUNC ...
- 《java入门第一季》之面向对象(重头戏继承来了)
java特性封装.继承.多态.之前对封装做了简单描述(见http://blog.csdn.net/qq_32059827/article/details/51312116),今天分析另一个特性继承性: ...
- Gradle 1.12用户指南翻译——第二十五章. Scala 插件
其他章节的翻译请参见: http://blog.csdn.net/column/details/gradle-translation.html 翻译项目请关注Github上的地址: https://g ...
- PS图层混合算法之六(差值,溶解, 排除)
差值模式: 查看每个通道中的颜色信息,比较底色和绘图色,用较亮的像素点的像素值减去较暗的像素点的像素值.与白色混合将使底色反相:与黑色混合则不产生变化. 排除模式可生成和差值模式相似的效果,但比差值模 ...
- Struts2技术内幕 读书笔记二 web开发的基本模式
最佳实践 在讨论基本模式之前,我们先说说一个词:最佳实践 任何程序的编写都得遵循一个特定的规范.这种规范有约定俗称的例如:包名全小写,类名每个单词第一个字母大写等等等等;另外还有一些需要我们严格遵守的 ...
- C++模板总结
在编写含有模板的程序的时候,我还是按照一个头文件声明,一个源文件的方法来组织,结果编译的时候总出现一些很奇怪的语法问题,但程序明明是没有问题的.后来经过查阅才知道原来是因为C++编译器不支持对模板的分 ...