hadoop学习笔记(八):hadoop2.x的高可用环境搭建
本文原创,转载请注明作者及原文链接
高可用集群的搭建:
几个集群的启动顺序问题:
1、先启动zookeeper --->zkServer.sh start
2、启动journalNodes集群 --->hadoop-daemon.sh start journalnode

也就是主结点nameNode的纵向扩展,为了克服单点故障灯问题,(要和联邦区分开,联邦是nameNode的横向扩展,为了克服一个从结点太多,一个主结点管理不过来的问题)
- 配置集群唯一的服务名称nameserverce ID ,整个集群的唯一标识符
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
- 配置HA集群中的两个NameNode
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
#特别的注意的是其中的nn1、nn2只是逻辑名称,而不是你的主机节点名,通过这个逻辑名称,是找不到具体的主机位置的
- 配置的两个主结点的逻辑名称到物理结点的映射 端口默认是8020
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>node01:</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>node02:</value>
</property> 其中的node01和node02是高可用集群中打算配置成两个主结点的两个结点
- 配置浏览器访问集群所访问的主机和port,端口默认是50070
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>node01:</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>node02:</value>
</property>
- 配置JournalNode集群中的各个结点所放置的物理位置
对于journalNodes这个集群,在每一个hdfs集群中的hdfs.site.xml文件中的配置项的作用解释
这个位置,可以随便的去写,这就是为了在journalNode集群中,新建一个目录去存储当前的所更改的hdfs.site.xml文件所在的集群的所有的edits log文件,因为对于这个日志集群可以存储多个集群的日志文件,对于每一个集群的话,都设置一个单独的文件,更好的去分清楚某一个集群的日志文件具体的存储于哪里!!
下面的
mycluster是一个hdfs集群的唯一的nameservice ID
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node01:8485;node2:8485;node3:8485/mycluster</value> #上面的解释是指的这句话中的mycluster的作用,且mycluster是一个hdfs集群的唯一的nameservice ID
</property>
- 配置 NameNode的故障转移所需要的那个类(java代码)
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
- 配置出问题的那个NameNode状态隔离的一个方式
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value> #指定的是以ssh远程登录的形式来隔离down掉的NameNode结点
</property> <property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_dsa</value> #配置那个曾经的active NameNode结点自己的私钥的存放路径
</property>

配置了这个之后,就可以实现当一个主结点出现问题的时候,立刻的将他阻塞隔离,而将另一个变成Active的主结点,就不会存在当当前的那个主结点出现问题了之后仍然还会继续的接收client发过来的 指令了,也就是当一个主结点坏掉之后,立马的被隔离掉,另一个steady的主结点变成Active状态
配置私钥的时候注意点:
注意这里是为了告诉那个standy NameNode结点想要登录另一个Active结点的话,另一个结点的私钥文件的位置
为什么这里设置成/root/.ssh/id_dsa因为,~/.ssh/id_dsa也就是说~就是指的是root用户的根目录
- 配置journalNode中的日志文件存放的位置
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/var/sxt/hadoop/ha/journalnode</value>
</property>
到此位置,%95的完成了高可用集群的搭建,只是现在的故障切换只能手工去做,如果想要自动故障转移的完成的话,需要一个zookper集群的辅助
下面配置zookeeper集群
zookeeper集群是怎么和主结点交互的
zookeeper集群的功能:1、故障检测(Failure detection):检测已经在当前已经在zookeeper中注册的结点是否正常,具体NameNode的注册是通过进行注册的
2、主结点注册, Active NameNode election 通过这个进程其中一个主结点来注册成Active NameNode
3、函数回调 调用的是zookeeper在两个namenode中启动JKFC进程中的函数(The ZKFailoverController)
官方介绍:
- Failure detection - each of the NameNode machines in the cluster maintains a persistent session in ZooKeeper. If the machine crashes, the ZooKeeper session will expire, notifying the other NameNode that a failover should be triggered.
- Active NameNode election - ZooKeeper provides a simple mechanism to exclusively elect a node as active. If the current active NameNode crashes, another node may take a special exclusive lock in ZooKeeper indicating that it should become the next active.
The ZKFailoverController (ZKFC) is a new component which is a ZooKeeper client which also monitors and manages the state of the NameNode. Each of the machines which runs a NameNode also runs a ZKFC, and that ZKFC is responsible for:
- Health monitoring (健康监控,如果不健康了就向zookeeper汇报,)- the ZKFC pings its local NameNode on a periodic basis with a health-check command. So long as the NameNode responds in a timely fashion with a healthy status, the ZKFC considers the node healthy. If the node has crashed, frozen, or otherwise entered an unhealthy state, the health monitor will mark it as unhealthy.
- ZooKeeper session management - when the local NameNode is healthy, the ZKFC holds a session open in ZooKeeper. If the local NameNode is active, it also holds a special "lock" znode. This lock uses ZooKeeper's support for "ephemeral" nodes; if the session expires, the lock node will be automatically deleted.
- ZooKeeper-based election(zookeeper的Active结点的参选机制) - if the local NameNode is healthy, and the ZKFC sees that no other node currently holds the lock znode, it will itself try to acquire the lock. If it succeeds, then it has "won the election", and is responsible for running a failover to make its local NameNode active. The failover process is similar to the manual failover
在相应的文件中进行配置
- 集群结点的zookeeper的配置
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property> <property>
<name>ha.zookeeper.quorum</name>
<value>zk1.example.com:,zk2.example.com:,zk3.example.com:</value>
</property>
所有的配置项完成之后,进行分发其他的几个未配置这两个文件的结点之上
[root@node01 hadoop]# scp hdfs-site.xml core-site.xml node02:`pwd`
hdfs-site.xml
core-site.xml
[root@node01 hadoop]# scp hdfs-site.xml core-site.xml node03:`pwd`
hdfs-site.xml
core-site.xml
[root@node01 hadoop]# scp hdfs-site.xml core-site.xml node04:`pwd`
下面真正在要搭建zookeeper集群的结点上上传解压安装配置zookeeper
- 上传zookeeper压缩包
- 解压安装

- 配置:重命名文件
vi zoo.cfg
[root@node02 conf]# mv zoo_sample.cfg zoo.cfg
[root@node02 conf]# vi zoo.cfg
在这个配置文件中还需要告诉zookeeper有几个结点参与集群的搭建,这是zookeeper的特殊点,搭建之前必须配置告诉有多少台参与
2888端口号是zookeeper服务之间通信的端口。
3888端口是zookeeper与其他应用程序通信的端口。
2181端口是zookeeper客户端请求接口。
server.=node02::3888 #2888和3888分别是通信端口
server.=node03::
server.=node04::
- 将zookeeper集群中配置好配置文件的Node02中的zookeeper。。。文件夹分发到其他的两个结点
[root@node02 sxt]# scp -r zookeeper-3.4./ node03:`pwd`
- 创建目录(是在zookeeper的conf的zoo.cfg中设置的位置),设置服务器编号,必须是数字,不能是字母!!!
结点node02中设置ID为1
,zoo.cfg配置文件里dataDir指定的那个目录下创建myid文件,并且指定id,改id为你zoo.cfg文件中server.1=ip:2888:3888中的1.只要在myid头部写入1即可.同理其它两台机器的id对应上
[root@node02 ~]# echo 1 > /var/sxt/zk/myid
结点node03中设置ID为2
[root@node03 sxt]# echo > /var/sxt/zk/myid
结点node04中设置ID为3
[root@node04 sxt]# echo 3 > /var/sxt/zk/myid
- 配置环境变量
#myadd export JAVA_HOME=/opt/soft/jdk1..0_144
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
export HADOOP_HOME=/opt/sxt/hadoop-2.6.
export ZOOKEEPER_HOME=/opt/sxt/zookeeper-3.4.6
PATH=$PATH:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${ZOOKEEPER_HOME}/bin
之后source /etc/profile 重新的读一下环境变量的配置文件
zookeeper集群搭建完毕!
启动zookeeper
[root@node03 bin]# zkServer.sh start
jps查询启动情况

出现问题
JMX enabled by default
Using config: /opt/sxt/zookeeper-3.4.6/bin/../conf/zoo.cfg
Error contacting service. It is probably not running.
解决问题 :因自己粗心将zoo.cfg文件和每一台结点中myid中配置的id匹配错误,结果导致zkServer.sh start 这个命令无法去启动zk集群
到此zk 集群正常的启动
没有format namenode前集群的启动:分步骤启动:
1、先启动zk集群:分别的去启动三个zk结点 :zkServer.sh start,用zkServer.sh status查看启动状态
2、启动journalnode 集群 ,分别去启动日志集群 :hadoop-daemon.sh start journalnode
3、hdfs namenode -format ,格式化namenode,
4、之后启动 namenode :hadoop-daemon.sh start namenode
5、另一个standy 的主结点执行:hdfs namenode -bootstrapStandby。去同步Active的主结点的数据。
6、 hdfs zkfc -formatZK,,在zk集群中注册主结点的信息
6、第一次HA集群启动,
7、对于之后,在启动集群的话,直接start-dfs.sh
具体的过程见:
2.启动hdfs ha集群
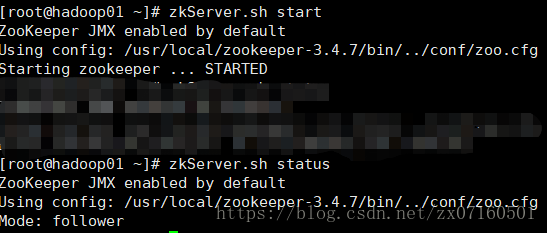
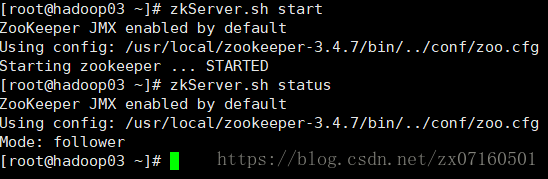
(1)启动zookeeper
启动 (每个节点都要执行)zkServer.sh start
验证 是否启动成功(每个节点都要执行)zkServer.sh status

(2)启动journalnode服务(单个启动、多个进程启动)
./sbin/hadoop-daemon.sh start journalnode
hadoop01 ./sbin/hadoop-daemons.sh start journalnode
(3)挑选两个namenode之中的一台来格式化,然后并且启动
hadoop01 hdfs namenode -format
hadoop-daemon.sh start namenode
(4)在另外一台namenode的机子上拉取元数据(也可以使用复制)
hadoop02 hdfs namenode -bootstrapStandby
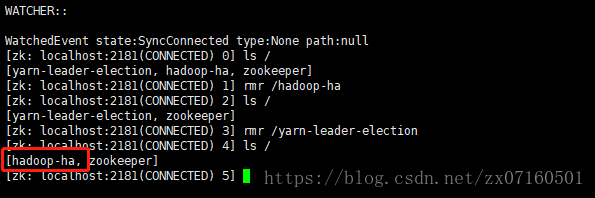
(5)格式化zkfc
hadoop01 hdfs zkfc -formatZK
(6)hadoop01上执行start-dfs.sh

(7)验证
①对应进程是否启动
hadoop01:

hadoop02:

hadoop03:

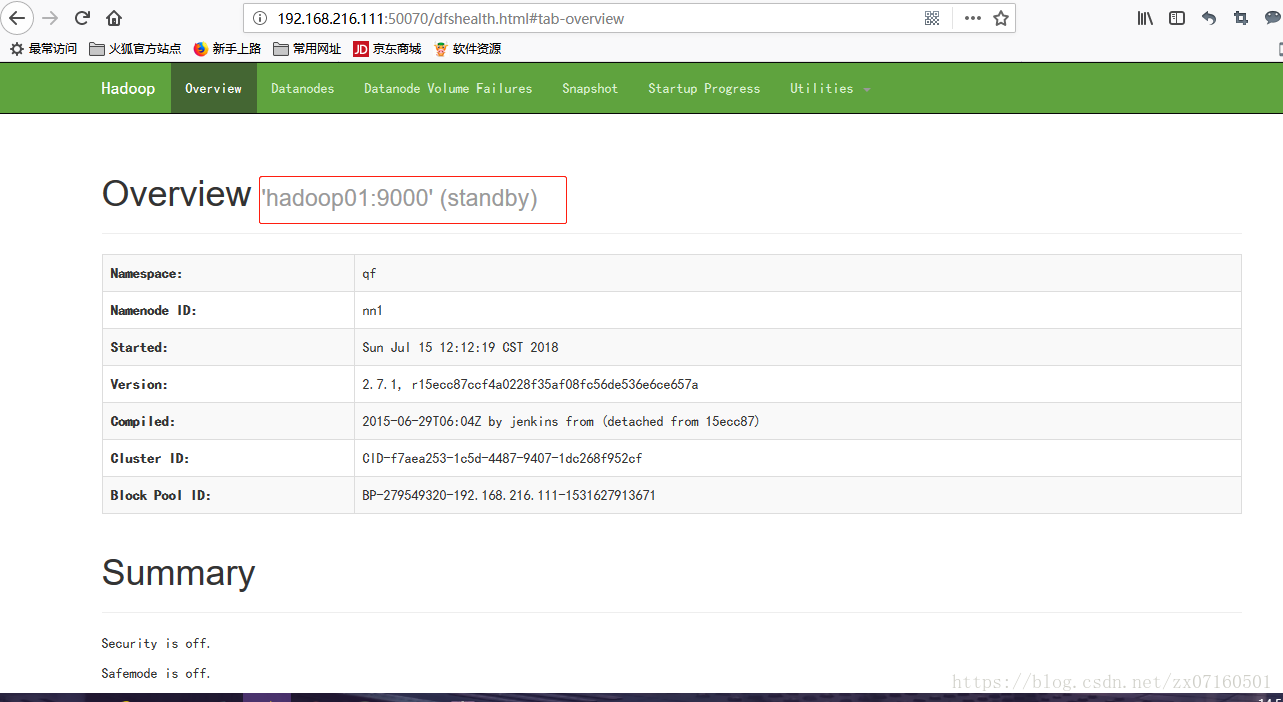
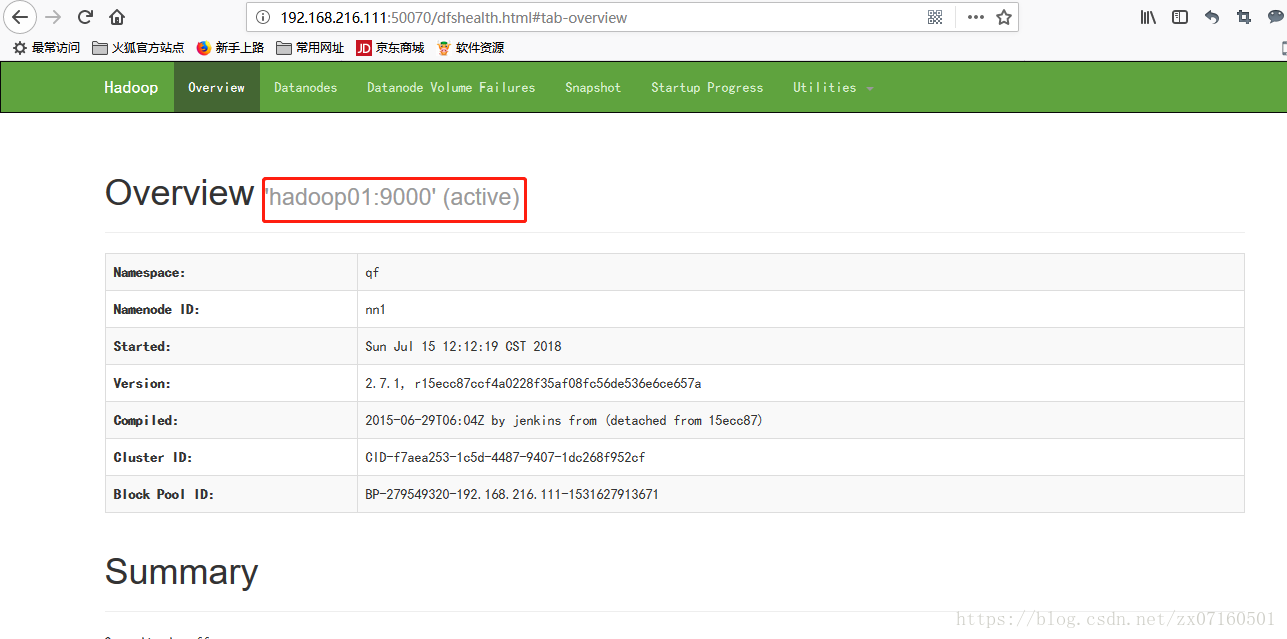
②web ui是否正常
hadoop02节点处于工作状态

hadoop01节点处于standby状态
③hdfs读文件(必须在工作状态的节点上)
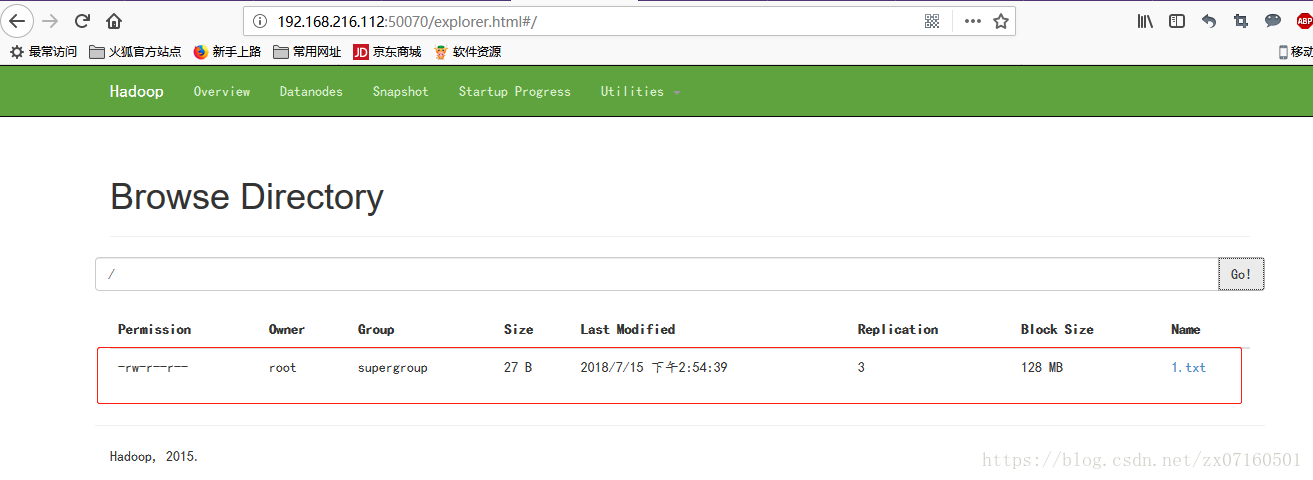
④关闭active的节点,测试standby节点是否正常
hadoop02节点:
hadoop01节点
参考:https://blog.csdn.net/wyqwilliam/article/details/81988103
hadoop学习笔记(八):hadoop2.x的高可用环境搭建的更多相关文章
- 大数据学习(07)——Hadoop3.3高可用环境搭建
前面用了五篇文章来介绍Hadoop的相关模块,理论学完还得操作一把才能加深理解.这一篇我会花相当长的时间从环境搭建开始,到怎么在使用Hadoop,逐步介绍Hadoop的使用. 本篇分这么几段内容: 规 ...
- Quartz学习笔记:集群部署&高可用
Quartz学习笔记:集群部署&高可用 集群部署 一个Quartz集群中的每个节点是一个独立的Quartz应用,它又管理着其他的节点.这就意味着你必须对每个节点分别启动或停止.Quartz集群 ...
- Hadoop学习笔记—22.Hadoop2.x环境搭建与配置
自从2015年花了2个多月时间把Hadoop1.x的学习教程学习了一遍,对Hadoop这个神奇的小象有了一个初步的了解,还对每次学习的内容进行了总结,也形成了我的一个博文系列<Hadoop学习笔 ...
- hadoop学习笔记(九):mr2HA高可用环境搭建及处步使用
本文原创,如需转载,请注明原文链接和作者 所用到的命令的总结: yarn:启动start-yarn.sh 停止stop-yarn.sh zk :zkServer.start ;:zkServer. ...
- k8s学习笔记(3)- kubectl高可用部署,扩容,升级,回滚springboot应用
前言:上一篇通过rancher管理k8s,部署服务应用扩容,高可用,本篇介绍kubectl命令行部署高可用集群节点,测试升级.扩容等 1.测试环境:3节点k3s,使用其中2节点(ubuntunode1 ...
- HTML5学习笔记<五>: HTML表单和PHP环境搭建
HTML表单 1. 表单用于不同类型的用户输入 2. 常用的表单标签: 标签 说明 <form> 表单 <input> 输入域 <textarea> 文本域 < ...
- Kafka高可用环境搭建
Apache Kafka是分布式发布-订阅消息系统,在 kafka官网上对 kafka 的定义:一个分布式发布-订阅消息传递系统. 它最初由LinkedIn公司开发,Linkedin于2010年贡献给 ...
- haproxy + rabbitmq + keepalived的高可用环境搭建
一.rabbitmq的搭建:参考rabbimq的安装及集群设置 二.安装和配置haproxy 1.安装haproxyyum install haproxy 2.安装rsysloga. 检查rsyslo ...
- Eureka高可用环境搭建
1.创建govern-center 子工程 包结构:com.dehigher.govern.center 2.pom文件 (1)父工程pom,用于依赖版本管理 <dependencyManage ...
随机推荐
- (一)Python模块化编程简介
1 引言 众所周知,模块化编程具备很多优点,尤其在复杂项目上体现更为明显.Python模块化编程有助于开发者统筹兼顾和分工协作,并提升代码灵活性和可维护性,是编程开发者不可或缺的一项重要工具. 2 P ...
- jQuery---城市选择案例
城市选择案例 <!DOCTYPE html> <html> <head lang="en"> <meta charset="UT ...
- HTML连载64-a标签伪类选择器的注意点与练习
一.a标签的伪类选择器注意点 (1)a标签的伪类选择器可以单独出现,也可以一起出现.也就是可以设置多个状态的样式. (2) a标签的伪类选择器如果一起出现,那么有严格的顺序要求,编写的顺序必须要遵守原 ...
- 【Unity|C#】基础篇(12)——反射(Reflection)(核心类:Type、Assembly)
[学习资料] <C#图解教程>(第24章):https://www.cnblogs.com/moonache/p/7687551.html 电子书下载:https://pan.baidu. ...
- 2017-9-15Opencv 杂
Mat::at()的具体含义.指的是三通道.(0),(1),(2)分别表示BGR: Vector<Mat>结构的使用.将Mat类型的数据转化成了具有多个单通道的容器? 灰度图的具体含义.和 ...
- Scrum简介
1. 什么是Scrum Scrum是一种轻量级的框架,适合于小型的.结合紧密的团队开发复杂的产品.Scrum是二十世纪后期一些软件工程师协同努力的脑力劳动的成果,现已成为技术领域最具魅力的方法.但Sc ...
- gulp-css-spriter 雪碧图合并
相信做前端的同学都做过这样的事情,为优化图片,减少请求会把拿到切好的图标图片,通过ps(或者其他工具)把图片合并到一张图里面,再通过css定位把对于的样式写出来引用的html里面.gulp-css-s ...
- 10.3 c++ STL 初步
#include<Windows.h>#include<iostream>#include<algorithm> // sort swap min ma ...
- wx: wx.showModal 回调函数中调用自定义方法
一.在回调函数中调用自定义方法: 回调函数中不能直接使用this,需要在外面定义 var that = this 然后 that.自定义的方法.如下: //删除 onDelete: function ...
- 题解 CF409A 【The Great Game】
题目传送门. 思路: 首先我们定义\(2\)个字符串,分别存放 TEAM 1 与 TEAM 2 的出招顺序.接着再定义\(2\)个变量,存放 TEAM 1 与 TEAM 2 的分数. string s ...