关于深度学习中的batch_size
5.4.1 关于深度学习中的batch_size
举个例子:
例如,假设您有1050个训练样本,并且您希望设置batch_size等于100.该算法从训练数据集中获取前100个样本(从第1到第100个)并训练网络。接下来,它需要第二个100个样本(从第101到第200)并再次训练网络。我们可以继续执行此过程,直到我们通过网络传播所有样本。最后一组样本可能会出现问题。在我们的例子中,我们使用了1050,它不能被100整除,没有余数。最简单的解决方案是获取最终的50个样本并训练网络。
最终目的:
通过一批又一批的样本去优化参数
使用批量大小的优点<所有样本的数量:
它需要更少的内存。由于您使用较少的样本训练网络,因此整体训练过程需要较少的内存。如果您无法将整个数据集放入机器的内存中,那么这一点尤为重要。
通常,网络通过小批量训练更快。那是因为我们在每次传播后更新权重。在我们的例子中,我们已经传播了11批(其中10个有100个样本,1个有50个样本),在每个批次之后我们更新了网络的参数。
如果我们在传播过程中使用了所有样本,我们只会对网络参数进行1次更新。
使用批量大小的缺点<所有样本的数量:
- 批次越小,梯度的估计就越不准确。在下图中,您可以看到小批量渐变(绿色)的方向与完整批次渐变(蓝色)的方向相比波动更大。
batch_size可以理解为批处理参数,它的极限值为训练集样本总数,当数据量比较少时,可以将batch_size值设置为全数据集(Full batch cearning)。
实际上,在深度学习中所涉及到的数据都是比较多的,一般都采用小批量数据处理原则。
小批量训练网络的优点:
- 相对海量的的数据集和内存容量,小批量处理需要更少的内存就可以训练网络。
- 通常小批量训练网络速度更快,例如我们将一个大样本分成11小样本(每个样本100个数据),采用小批量训练网络时,每次传播后更新权重,就传播了11批,在每批次后我们均更新了网络的(权重)参数;如果在传播过程中使用了一个大样本,我们只会对训练网络的权重参数进行1次更新。
- 全数据集确定的方向能够更好地代表样本总体,从而能够更准确地朝着极值所在的方向;但是不同权值的梯度值差别较大,因此选取一个全局的学习率很困难。
小批量训练网络的缺点:
- 批次越小,梯度的估值就越不准确,在下图中,我们可以看到,与完整批次渐变(蓝色)方向相比,小批量渐变(绿色)的方向波动更大。
- 极端特例batch_size = 1,也成为在线学习(online learning);线性神经元在均方误差代价函数的错误面是一个抛物面,横截面是椭圆,对于多层神经元、非线性网络,在局部依然近似是抛物面,使用online learning,每次修正方向以各自样本的梯度方向修正,这就造成了波动较大,难以达到收敛效果。
如下图所示
stochastic(红色)表示在线学习,batch_size = 1;
mini_batch(绿色)表示批梯度下降法,batch_size = 100;
batch(蓝色)表示全数据集梯度下降法,batch_size = 1100;
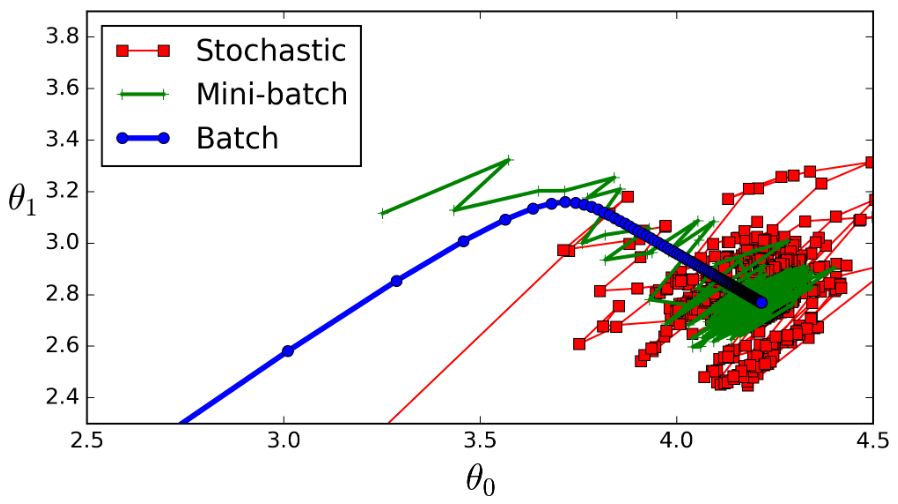
从图上可以发现,batch_szie=1 较 batch_size=100 的波动性更大。
设置mini_batch大小是一种艺术,太小时可能会使学习过于随机,虽然训练速率很快,但会收敛到不可靠的模型;mini_batch过小时,网络训练需要很长时间,更重要的是它不适合记忆。
如何选择合适的batch_size值:
采用批梯度下降法mini batch learning时,如果数据集足够充分,用一半(甚至少的多)的数据训练算出来的梯度与全数据集训练full batch learning出来的梯度几乎一样。
- 在合理的范围内,增大batch_size可以提高内存利用率,大矩阵乘法的并行化效率提高;跑完一次epoch(全数据集)所需的迭代次数减少,对于相同数据量的处理速度进一步加快;在适当的范围内,batch_size越大,其确定的下降方向越准,引起训练波动越小。注意,当batch_size增大到一定程度,其确定的下降方向基本不会变化。
batch_size值增大到超过合理范围时,和全数据训练full batch learning就会表现出相近的症候;内存容量占有率增加,跑完一次epoch(全数据集)所需的迭代次数减少,达到相同的精度所耗损的时间增加,从而对参数的修正也就显得更加缓慢。
调节 Batch_Size 对训练效果影响到底如何?
这里跑一个 LeNet 在 MNIST 数据集上的效果。MNIST 是一个手写体标准库
运行结果如上图所示,其中绝对时间做了标准化处理。运行结果与上文分析相印证:
- batch_size 太小,算法在 200 epoches 内不收敛。
- 随着 batch_size 增大,处理相同数据量的速度越快。
- 随着 batch_size 增大,达到相同精度所需要的 epoch 数量越来越多。
- 由于上述两种因素的矛盾,batch_size 增大到某个时候,达到时间上的最优。
- 由于最终收敛精度会陷入不同的局部极值,因此batch_size 增大到某些时候,达到最终收敛精度上的最优。
关于深度学习中的batch_size的更多相关文章
- 深度学习中的batch_size,iterations,epochs等概念的理解
在自己完成的几个有关深度学习的Demo中,几乎都出现了batch_size,iterations,epochs这些字眼,刚开始我也没在意,觉得Demo能运行就OK了,但随着学习的深入,我就觉得不弄懂这 ...
- 2.深度学习中的batch_size的理解
Batch_Size(批尺寸)是机器学习中一个重要参数,涉及诸多矛盾,下面逐一展开. 首先,为什么需要有 Batch_Size 这个参数? Batch 的选择,首先决定的是下降的方向.如果数据集比较小 ...
- 深度学习中的Data Augmentation方法(转)基于keras
在深度学习中,当数据量不够大时候,常常采用下面4中方法: 1. 人工增加训练集的大小. 通过平移, 翻转, 加噪声等方法从已有数据中创造出一批"新"的数据.也就是Data Augm ...
- 深度学习中GPU和显存分析
刚入门深度学习时,没有显存的概念,后来在实验中才渐渐建立了这个意识. 下面这篇文章很好的对GPU和显存总结了一番,于是我转载了过来. 作者:陈云 链接:https://zhuanlan.zhihu. ...
- 深度学习中优化【Normalization】
深度学习中优化操作: dropout l1, l2正则化 momentum normalization 1.为什么Normalization? 深度神经网络模型的训练为什么会很困难?其中一个重 ...
- 深度学习中dropout策略的理解
现在有空整理一下关于深度学习中怎么加入dropout方法来防止测试过程的过拟合现象. 首先了解一下dropout的实现原理: 这些理论的解释在百度上有很多.... 这里重点记录一下怎么实现这一技术 参 ...
- 深度学习中交叉熵和KL散度和最大似然估计之间的关系
机器学习的面试题中经常会被问到交叉熵(cross entropy)和最大似然估计(MLE)或者KL散度有什么关系,查了一些资料发现优化这3个东西其实是等价的. 熵和交叉熵 提到交叉熵就需要了解下信息论 ...
- 深度学习中Dropout原理解析
1. Dropout简介 1.1 Dropout出现的原因 在机器学习的模型中,如果模型的参数太多,而训练样本又太少,训练出来的模型很容易产生过拟合的现象. 在训练神经网络的时候经常会遇到过拟合的问题 ...
- 卷积在深度学习中的作用(转自http://timdettmers.com/2015/03/26/convolution-deep-learning/)
卷积可能是现在深入学习中最重要的概念.卷积网络和卷积网络将深度学习推向了几乎所有机器学习任务的最前沿.但是,卷积如此强大呢?它是如何工作的?在这篇博客文章中,我将解释卷积并将其与其他概念联系起来,以帮 ...
随机推荐
- Web服务器之Nginx详解(操作部分)
大纲 一.前言 二.Nginx 安装与配置 三.Nginx 配置文件详解 四.Nginx 命令参数 五.配置Nginx提供Web服务 六.配置Nginx的虚拟主机 七.配置Nginx的用户认证 八.配 ...
- 《C语言程序设计》编程总结汇总
<C语言程序设计>编程总结汇总 院系: 专业年级: 班级名称: 学号: 姓名: 指导教师: 完成时间: 自我评价: 计算机科学与技术专业教研室 2018 年秋季学期 第四周编程总结 题目4 ...
- 使外部主机可访问Django服务
欲让外部主机可访问Django的服务器,需使用如下命令开启服务 python manage.py runserver 0.0.0.0:8000
- Java String对象的问题 String s="a"+"b"+"c"+"d"
1, String s="a"+"b"+"c"+"d"创建了几个对象(假设之前串池是空的) 2,StringBuilde ...
- time&datetime
关于time模块的代码部分 1 #_*_coding:utf-8_*_ 2 __author__ = 'Alex Li' 3 4 import time 5 6 7 # print(time.cloc ...
- access数据库编号转换成统一3位数长度方法,不足3位前面补零
select C_CUN+Format(Val(NZ(C_LB)),"000") from LBM 这条SQL只能在access数据库中执行,因为sql不支持NZ函数,而且c_lb ...
- WebHttpRequest在sharepoint文档库中的使用
写在前面 由于sharepoint服务器上的站点采用的域用户windows认证的方式登陆,而app项目虽然能够提供用户名和密码,但客户是不愿意在网络上这样传输的.所以给提供了使用ssl证书认证的方式. ...
- Linux常用命令大全(分类)
首先按ESC键回到命令模式: vi保存文件有不同的选项,对应于不同的命令,你可以从下面的命令中选择一个需要的::w 保存文件但不退出vi :w file 将修改另外保存到file中,不退出vi:w! ...
- BZOJ 4584 luogu P3643: [Apio2016]赛艇
4584: [Apio2016]赛艇 Time Limit: 70 Sec Memory Limit: 256 MB[Submit][Status][Discuss] Description 在首尔 ...
- ORA-00911: invalid character 包含中文报错
SQL在pl下正常执行在vs里报错ORA-00911: invalid character. 1.检查SQL末尾是否含有";" 去掉 2.sql包含中文报错 string sql ...