Spark应用_PageView_UserView_HotChannel
Spark应用_PageView_UserView_HotChannel
一、PV
对某一个页面的访问量,在页面中进行刷新一次就是一次pv
PV {p1, (u1,u2,u3,u1,u2,u4…)} 对同一个页面的浏览量进行统计,用户可以重复
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
public class PV_ANA {
public static void main(String[] args) {
SparkConf conf = new SparkConf()
.setAppName("PV_ANA")
.setMaster("local")
.set("spark.testing.memory", "2147480000");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> logRDD = sc.textFile("f:/userLog");
String str = "View";
final Broadcast<String> broadcast = sc.broadcast(str);
pvAnalyze(logRDD, broadcast);
}
private static void pvAnalyze(JavaRDD<String> logRDD,
final Broadcast<String> broadcast) {
JavaRDD<String> filteredLogRDD = logRDD.filter
(new Function<String, Boolean>() {
private static final long serialVersionUID = 1L;
@Override
public Boolean call(String s) throws Exception {
String actionParam = broadcast.value();
String action = s.split("\t")[5];
return actionParam.equals(action);
}
});
JavaPairRDD<String, String> pariLogRDD = filteredLogRDD.mapToPair
(new PairFunction<String, String, String>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, String> call(String s)
throws Exception {
String pageId = s.split("\t")[3];
return new Tuple2<String, String>(pageId, null);
}
});
pariLogRDD.groupByKey().foreach(new VoidFunction
<Tuple2<String, Iterable<String>>>() {
private static final long serialVersionUID = 1L;
@Override
public void call(Tuple2<String, Iterable<String>> tuple)
throws Exception {
String pageId = tuple._1;
Iterator<String> iterator = tuple._2.iterator();
long count = 0L;
while (iterator.hasNext()) {
iterator.next();
count++;
}
System.out.println("PAGEID:" + pageId + "\t PV_COUNT:" + count);
}
});
}
}
|
二、UV
UV {p1, (u1,u2,u3,u4,u5…)} 对一个页面有多少用户访问,用户不可以重复
【方式一】
【流程图】

|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
public class UV_ANA {
public static void main(String[] args) {
SparkConf conf = new SparkConf()
.setAppName("UV_ANA")
.setMaster("local")
.set("spark.testing.memory", "2147480000");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> logRDD = sc.textFile("f:/userLog");
String str = "View";
final Broadcast<String> broadcast = sc.broadcast(str);
uvAnalyze(logRDD, broadcast);
}
private static void uvAnalyze(JavaRDD<String> logRDD,
final Broadcast<String> broadcast) {
JavaRDD<String> filteredLogRDD = logRDD.filter
(new Function<String, Boolean>() {
private static final long serialVersionUID = 1L;
@Override
public Boolean call(String s) throws Exception {
String actionParam = broadcast.value();
String action = s.split("\t")[5];
return actionParam.equals(action);
}
});
JavaPairRDD<String, String> pairLogRDD = filteredLogRDD.mapToPair
(new PairFunction<String, String, String>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, String> call(String s) throws Exception {
String pageId = s.split("\t")[3];
String userId = s.split("\t")[2];
return new Tuple2<String, String>(pageId, userId);
}
});
pairLogRDD.groupByKey().foreach(new VoidFunction
<Tuple2<String, Iterable<String>>>() {
private static final long serialVersionUID = 1L;
@Override
public void call(Tuple2<String, Iterable<String>> tuple)
throws Exception {
String pageId = tuple._1;
Iterator<String> iterator = tuple._2.iterator();
Set<String> userSets = new HashSet<>();
while (iterator.hasNext()) {
String userId = iterator.next();
userSets.add(userId);
}
System.out.println("PAGEID:" + pageId + "\t " +
"UV_COUNT:" + userSets.size());
}
});
}
}
|
【方式二】
【流程图】

|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
|
public class UV_ANAoptz {
public static void main(String[] args) {
SparkConf conf = new SparkConf()
.setAppName("UV_ANAoptz")
.setMaster("local")
.set("spark.testing.memory", "2147480000");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> logRDD = sc.textFile("f:/userLog");
String str = "View";
final Broadcast<String> broadcast = sc.broadcast(str);
uvAnalyzeOptz(logRDD, broadcast);
}
private static void uvAnalyzeOptz(JavaRDD<String> logRDD,
final Broadcast<String> broadcast) {
JavaRDD<String> filteredLogRDD = logRDD.filter
(new Function<String, Boolean>() {
private static final long serialVersionUID = 1L;
@Override
public Boolean call(String s) throws Exception {
String actionParam = broadcast.value();
String action = s.split("\t")[5];
return actionParam.equals(action);
}
});
JavaPairRDD<String, String> pairRDD = filteredLogRDD.mapToPair
(new PairFunction<String, String, String>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, String> call(String s)
throws Exception {
String pageId = s.split("\t")[3];
String userId = s.split("\t")[2];
return new Tuple2<String, String>(pageId + "_" +
userId, null);
}
});
JavaPairRDD<String, Iterable<String>> groupUp2LogRDD = pairRDD.groupByKey();
Map<String, Object> countByKey = groupUp2LogRDD.mapToPair
(new PairFunction<Tuple2<String, Iterable<String>>,
String, String>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, String> call(Tuple2<String,
Iterable<String>> tuple)
throws Exception {
String pu = tuple._1;
String[] spilted = pu.split("_");
String pageId = spilted[0];
return new Tuple2<String, String>(pageId, null);
}
}).countByKey();
Set<String> keySet = countByKey.keySet();
for (String key : keySet) {
System.out.println("PAGEID:" + key + "\tUV_COUNT:" +
countByKey.get(key));
}
}
}
|
三、热门版块下用户访问的数量
统计出热门版块中最活跃的top3用户。
【方式一】
【流程图】

|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
|
public class HotChannel {
public static void main(String[] args) {
SparkConf conf = new SparkConf()
.setAppName("HotChannel")
.setMaster("local")
.set("spark.testing.memory", "2147480000");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> logRDD = sc.textFile("f:/userLog");
String str = "View";
final Broadcast<String> broadcast = sc.broadcast(str);
hotChannel(sc, logRDD, broadcast);
}
private static void hotChannel(JavaSparkContext sc, JavaRDD<String> logRDD,
final Broadcast<String> broadcast) {
JavaRDD<String> filteredLogRDD = logRDD.filter
(new Function<String, Boolean>() {
private static final long serialVersionUID = 1L;
@Override
public Boolean call(String v1) throws Exception {
String actionParam = broadcast.value();
String action = v1.split("\t")[5];
return actionParam.equals(action);
}
});
JavaPairRDD<String, String> channel2nullRDD = filteredLogRDD.mapToPair
(new PairFunction<String, String, String>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, String> call(String s) throws Exception {
String channel = s.split("\t")[4];
return new Tuple2<String, String>(channel, null);
}
});
Map<String, Object> channelPVMap = channel2nullRDD.countByKey();
Set<String> keySet = channelPVMap.keySet();
List<SortObj> channels = new ArrayList<>();
for (String channel : keySet) {
channels.add(new SortObj(channel, Integer.valueOf
(channelPVMap.get(channel) + "")));
}
Collections.sort(channels, new Comparator<SortObj>() {
@Override
public int compare(SortObj o1, SortObj o2) {
return o2.getValue() - o1.getValue();
}
});
List<String> hotChannelList = new ArrayList<>();
for (int i = 0; i < 3; i++) {
hotChannelList.add(channels.get(i).getKey());
}
for (String channel : hotChannelList) {
System.out.println("channel:" + channel);
}
final Broadcast<List<String>> hotChannelListBroadcast =
sc.broadcast(hotChannelList);
JavaRDD<String> filterRDD = logRDD.filter(new Function<String, Boolean>() {
@Override
public Boolean call(String s) throws Exception {
List<String> hostChannels = hotChannelListBroadcast.value();
String channel = s.split("\t")[4];
String userId = s.split("\t")[2];
return hostChannels.contains(channel) && !"null".equals(userId);
}
});
JavaPairRDD<String, String> channel2UserRDD = filterRDD.mapToPair
(new PairFunction<String, String, String>() {
@Override
public Tuple2<String, String> call(String s)
throws Exception {
String[] splited = s.split("\t");
String channel = splited[4];
String userId = splited[2];
return new Tuple2<String, String>(channel, userId);
}
});
channel2UserRDD.groupByKey().foreach(new VoidFunction
<Tuple2<String, Iterable<String>>>() {
@Override
public void call(Tuple2<String, Iterable<String>> tuple)
throws Exception {
String channel = tuple._1;
Iterator<String> iterator = tuple._2.iterator();
Map<String, Integer> userNumMap = new HashMap<>();
while (iterator.hasNext()) {
String userId = iterator.next();
Integer count = userNumMap.get(userId);
if (count == null) {
count = 1;
} else {
count++;
}
userNumMap.put(userId, count);
}
List<SortObj> lists = new ArrayList<>();
Set<String> keys = userNumMap.keySet();
for (String key : keys) {
lists.add(new SortObj(key, userNumMap.get(key)));
}
Collections.sort(lists, new Comparator<SortObj>() {
@Override
public int compare(SortObj O1, SortObj O2) {
return O2.getValue() - O1.getValue();
}
});
System.out.println("HOT_CHANNEL:" + channel);
for (int i = 0; i < 3; i++) {
SortObj sortObj = lists.get(i);
System.out.println(sortObj.getKey() + "=="
+ sortObj.getValue());
}
}
});
}
}
|
【方式二】
【流程图】
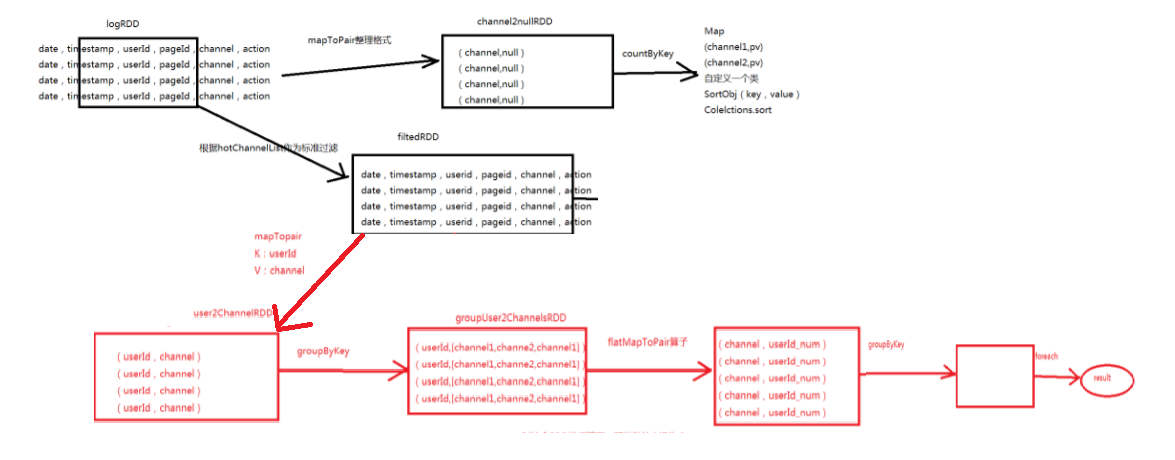
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
|
public class HotChannelOpz {
public static void main(String[] args) {
SparkConf conf = new SparkConf()
.setAppName("hotChannelOpz")
.setMaster("local")
.set("spark.testing.memory", "2147480000");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> logRDD = sc.textFile("f:/userLog");
String str = "View";
final Broadcast<String> broadcast = sc.broadcast(str);
hotChannelOpz(sc, logRDD, broadcast);
}
private static void hotChannelOpz(JavaSparkContext sc, JavaRDD<String> logRDD,
final Broadcast<String> broadcast) {
JavaRDD<String> filteredLogRDD = logRDD.filter
(new Function<String, Boolean>() {
private static final long serialVersionUID = 1L;
@Override
public Boolean call(String v1) throws Exception {
String actionParam = broadcast.value();
String action = v1.split("\t")[5];
return actionParam.equals(action);
}
});
JavaPairRDD<String, String> channel2nullRDD = filteredLogRDD.mapToPair
(new PairFunction<String, String, String>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, String> call(String val)
throws Exception {
String channel = val.split("\t")[4];
return new Tuple2<String, String>(channel, null);
}
});
Map<String, Object> channelPVMap = channel2nullRDD.countByKey();
Set<String> keySet = channelPVMap.keySet();
List<SortObj> channels = new ArrayList<>();
for (String channel : keySet) {
channels.add(new SortObj(channel, Integer.valueOf
(channelPVMap.get(channel) + "")));
}
Collections.sort(channels, new Comparator<SortObj>() {
@Override
public int compare(SortObj o1, SortObj o2) {
return o2.getValue() - o1.getValue();
}
});
List<String> hotChannelList = new ArrayList<>();
for (int i = 0; i < 3; i++) {
hotChannelList.add(channels.get(i).getKey());
}
final Broadcast<List<String>> hotChannelListBroadcast =
sc.broadcast(hotChannelList);
JavaRDD<String> filtedRDD = logRDD.filter
(new Function<String, Boolean>() {
@Override
public Boolean call(String v1) throws Exception {
List<String> hostChannels = hotChannelListBroadcast.value();
String channel = v1.split("\t")[4];
String userId = v1.split("\t")[2];
return hostChannels.contains(channel) &&
!"null".equals(userId);
}
});
JavaPairRDD<String, String> user2ChannelRDD = filtedRDD.mapToPair
(new PairFunction<String, String, String>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, String> call(String val)
throws Exception {
String[] splited = val.split("\t");
String userId = splited[2];
String channel = splited[4];
return new Tuple2<String, String>(userId, channel);
}
});
JavaPairRDD<String, String> userVistChannelsRDD =
user2ChannelRDD.groupByKey().
flatMapToPair(new PairFlatMapFunction
<Tuple2<String, Iterable<String>>, String, String>() {
private static final long serialVersionUID = 1L;
@Override
public Iterable<Tuple2<String, String>> call
(Tuple2<String, Iterable<String>> tuple)
throws Exception {
String userId = tuple._1;
Iterator<String> iterator = tuple._2.iterator();
Map<String, Integer> channelMap = new HashMap<>();
while (iterator.hasNext()) {
String channel = iterator.next();
Integer count = channelMap.get(channel);
if (count == null)
count = 1;
else
count++;
channelMap.put(channel, count);
}
List<Tuple2<String, String>> list = new ArrayList<>();
Set<String> keys = channelMap.keySet();
for (String channel : keys) {
Integer channelNum = channelMap.get(channel);
list.add(new Tuple2<String, String>(channel,
userId + "_" + channelNum));
}
return list;
}
});
userVistChannelsRDD.groupByKey().foreach(new VoidFunction
<Tuple2<String, Iterable<String>>>() {
@Override
public void call(Tuple2<String, Iterable<String>> tuple)
throws Exception {
String channel = tuple._1;
Iterator<String> iterator = tuple._2.iterator();
List<SortObj> list = new ArrayList<>();
while (iterator.hasNext()) {
String ucs = iterator.next();
String[] splited = ucs.split("_");
String userId = splited[0];
Integer num = Integer.valueOf(splited[1]);
list.add(new SortObj(userId, num));
}
Collections.sort(list, new Comparator<SortObj>() {
@Override
public int compare(SortObj o1, SortObj o2) {
return o2.getValue() - o1.getValue();
}
});
System.out.println("HOT_CHANNLE:" + channel);
for (int i = 0; i < 3; i++) {
SortObj sortObj = list.get(i);
System.out.println(sortObj.getKey() + "==="
+ sortObj.getValue());
}
}
});
}
}
|
Spark应用_PageView_UserView_HotChannel的更多相关文章
- Spark踩坑记——Spark Streaming+Kafka
[TOC] 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark strea ...
- Spark RDD 核心总结
摘要: 1.RDD的五大属性 1.1 partitions(分区) 1.2 partitioner(分区方法) 1.3 dependencies(依赖关系) 1.4 compute(获取分区迭代列表) ...
- spark处理大规模语料库统计词汇
最近迷上了spark,写一个专门处理语料库生成词库的项目拿来练练手, github地址:https://github.com/LiuRoy/spark_splitter.代码实现参考wordmaker ...
- Hive on Spark安装配置详解(都是坑啊)
个人主页:http://www.linbingdong.com 简书地址:http://www.jianshu.com/p/a7f75b868568 简介 本文主要记录如何安装配置Hive on Sp ...
- Spark踩坑记——数据库(Hbase+Mysql)
[TOC] 前言 在使用Spark Streaming的过程中对于计算产生结果的进行持久化时,我们往往需要操作数据库,去统计或者改变一些值.最近一个实时消费者处理任务,在使用spark streami ...
- Spark踩坑记——初试
[TOC] Spark简介 整体认识 Apache Spark是一个围绕速度.易用性和复杂分析构建的大数据处理框架.最初在2009年由加州大学伯克利分校的AMPLab开发,并于2010年成为Apach ...
- Spark读写Hbase的二种方式对比
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处 一.传统方式 这种方式就是常用的TableInputFormat和TableOutputForm ...
- (资源整理)带你入门Spark
一.Spark简介: 以下是百度百科对Spark的介绍: Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方 ...
- Spark的StandAlone模式原理和安装、Spark-on-YARN的理解
Spark是一个内存迭代式运算框架,通过RDD来描述数据从哪里来,数据用那个算子计算,计算完的数据保存到哪里,RDD之间的依赖关系.他只是一个运算框架,和storm一样只做运算,不做存储. Spark ...
随机推荐
- c#加密解密源码,md5、des、rsa
从网上找来的代码,顺手改改,用起来更方便. 配置文件 using System; using System.Collections.Generic; using System.Text; using ...
- JVM 运行时的内存分配
首先我们必须要知道的是 Java 是跨平台的.而它之所以跨平台就是因为 JVM 不是跨平台的.JVM 建立了 Java 程序和操作系统之间的桥梁,JVM 是用 C 语言编写,而 C 语言不具备跨平台的 ...
- JAVA NIO学习四:Path&Paths&Files 学习
今天我们将学习NIO 的最后一章,前面大部分涉及IO 和 NIO 的知识都已经讲过了,那么本章将要讲解的是关于Path 以及Paths 和 Files 相关的知识点,以对前面知识点的补充,好了言归正传 ...
- ${param.name}和${name}的区别
${param.name} == request.getParam("name") ${name} == request.getAttribute("name" ...
- RobotFrame连接MySql数据库
RobotFrame连接MySql数据库这类的教程网上并不多,就算有,也是很多坑.小编今天为大家提供一个靠谱的教程,但是具体的包需要大家自己下载.废话不多说,看疗效~~~ 1.pip install ...
- sqlserver资源
1.数据库“高可用性”和“灾难恢复”技术 参考: niyi0318的专栏
- WPF自定义Window样式(2)
1. 引言 在上一篇中,介绍了如何建立自定义窗体.接下来,我们需要考虑将该自定义窗体基类放到类库中去,只有放到类库中,我们才能在其他地方去方便的引用该基类. 2. 创建类库 接上一篇的项目,先添加一个 ...
- Appium python
1.运行报错:FAILED_ALREADY_EXISTS: Attempt to re-install io.appium.android.ime without first uninstalling ...
- 三种ajax上传文件方法
1. XMLHttpRequest(原生ajax) <input class="file" type="file" id="fafafa&qu ...
- JavaScript(二)基本概念
JS区分大小写 html/css 中 标签选择器不区分大小写 id class 选择器区分大小写 其中属性名 属性名 属性值 不区分大小写 行间事件 onclick 等 不区分大小写 而 执 ...