神经网络优化篇:详解Batch Norm 为什么奏效?(Why does Batch Norm work?)
Batch Norm 为什么奏效?
为什么Batch归一化会起作用呢?
一个原因是,已经看到如何归一化输入特征值\(x\),使其均值为0,方差1,它又是怎样加速学习的,有一些从0到1而不是从1到1000的特征值,通过归一化所有的输入特征值\(x\),以获得类似范围的值,可以加速学习。所以Batch归一化起的作用的原因,直观的一点就是,它在做类似的工作,但不仅仅对于这里的输入值,还有隐藏单元的值,这只是Batch归一化作用的冰山一角,还有些深层的原理,它会有助于对Batch归一化的作用有更深的理解,让一起来看看吧。
Batch归一化有效的第二个原因是,它可以使权重比的网络更滞后或更深层,比如,第10层的权重更能经受得住变化,相比于神经网络中前层的权重,比如第1层,为了解释的意思,让来看看这个最生动形象的例子。

这是一个网络的训练,也许是个浅层网络,比如logistic回归或是一个神经网络,也许是个浅层网络,像这个回归函数。或一个深层网络,建立在著名的猫脸识别检测上,但假设已经在所有黑猫的图像上训练了数据集,如果现在要把此网络应用于有色猫,这种情况下,正面的例子不只是左边的黑猫,还有右边其它颜色的猫,那么的cosfa可能适用的不会很好。

如果图像中,训练集是这个样子的,的正面例子在这儿,反面例子在那儿(左图),但试图把它们都统一于一个数据集,也许正面例子在这,反面例子在那儿(右图)。也许无法期待,在左边训练得很好的模块,同样在右边也运行得很好,即使存在运行都很好的同一个函数,但不会希望的学习算法去发现绿色的决策边界,如果只看左边数据的话。

所以使数据改变分布的这个想法,有个有点怪的名字“Covariate shift”,想法是这样的,如果已经学习了\(x\)到\(y\) 的映射,如果\(x\) 的分布改变了,那么可能需要重新训练的学习算法。这种做法同样适用于,如果真实函数由\(x\) 到\(y\) 映射保持不变,正如此例中,因为真实函数是此图片是否是一只猫,训练的函数的需要变得更加迫切,如果真实函数也改变,情况就更糟了。
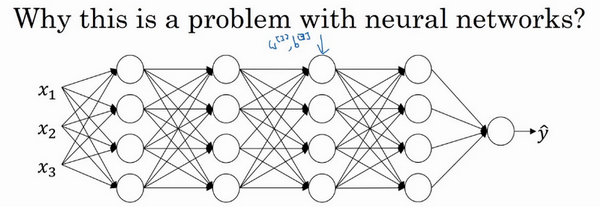
“Covariate shift”的问题怎么应用于神经网络呢?试想一个像这样的深度网络,让从这层(第三层)来看看学习过程。此网络已经学习了参数\(w^{[3]}\)和\(b^{[3]}\),从第三隐藏层的角度来看,它从前层中取得一些值,接着它需要做些什么,使希望输出值\(\hat y\)接近真实值\(y\)。
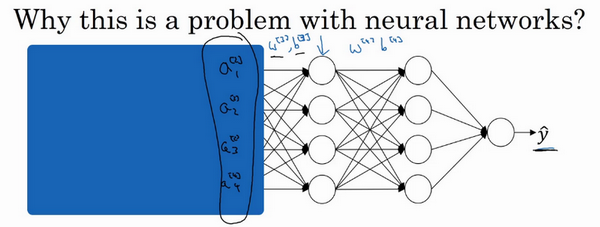
让先遮住左边的部分,从第三隐藏层的角度来看,它得到一些值,称为\(a_{1}^{[2]}\),\(a_{2}^{[2]}\),\(a_{3}^{[2]}\),\(a_{4}^{[2]}\),但这些值也可以是特征值\(x_{1}\),\(x_{2}\),\(x_{3}\),\(x_{4}\),第三层隐藏层的工作是找到一种方式,使这些值映射到\(\hat y\),可以想象做一些截断,所以这些参数\(w^{[3]}\)和\(b^{[3]}\)或\(w^{[4]}\)和\(b^{[4]}\)或\(w^{[5]}\)和\(b^{[5]}\),也许是学习这些参数,所以网络做的不错,从左边用黑色笔写的映射到输出值\(\hat y\)。
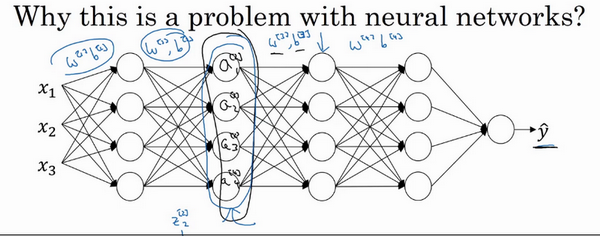
现在把网络的左边揭开,这个网络还有参数\(w^{[2]}\),\(b^{[2]}\)和\(w^{[1]}\),\(b^{[1]}\),如果这些参数改变,这些\(a^{[2]}\)的值也会改变。所以从第三层隐藏层的角度来看,这些隐藏单元的值在不断地改变,所以它就有了“Covariate shift”的问题。
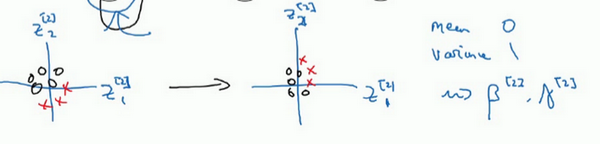
Batch归一化做的,是它减少了这些隐藏值分布变化的数量。如果是绘制这些隐藏的单元值的分布,也许这是重整值\(z\),这其实是\(z_{1}^{[2]}\),\(z_{2}^{[2]}\),要绘制两个值而不是四个值,以便设想为2D,Batch归一化讲的是\(z_{1}^{[2]}\),\(z_{2}^{[2]}\)的值可以改变,它们的确会改变,当神经网络在之前层中更新参数,Batch归一化可以确保无论其怎样变化\(z_{1}^{[2]}\),\(z_{2}^{[2]}\)的均值和方差保持不变,所以即使\(z_{1}^{[2]}\),\(z_{2}^{[2]}\)的值改变,至少他们的均值和方差也会是均值0,方差1,或不一定必须是均值0,方差1,而是由\({\beta}^{[2]}\)和\(\gamma^{[2]}\)决定的值。如果神经网络选择的话,可强制其为均值0,方差1,或其他任何均值和方差。但它做的是,它限制了在前层的参数更新,会影响数值分布的程度,第三层看到的这种情况,因此得到学习。
Batch归一化减少了输入值改变的问题,它的确使这些值变得更稳定,神经网络的之后层就会有更坚实的基础。即使使输入分布改变了一些,它会改变得更少。它做的是当前层保持学习,当改变时,迫使后层适应的程度减小了,可以这样想,它减弱了前层参数的作用与后层参数的作用之间的联系,它使得网络每层都可以自己学习,稍稍独立于其它层,这有助于加速整个网络的学习。

所以,希望这能带给更好的直觉,重点是Batch归一化的意思是,尤其从神经网络后层之一的角度而言,前层不会左右移动的那么多,因为它们被同样的均值和方差所限制,所以,这会使得后层的学习工作变得更容易些。
Batch归一化还有一个作用,它有轻微的正则化效果,Batch归一化中非直观的一件事是,每个mini-batch,会说mini-batch\(X^{\{ t \}}\)的值为\(z^{\lbrack t\rbrack}\),\(z^{[l]}\),在mini-batch计算中,由均值和方差缩放的,因为在mini-batch上计算的均值和方差,而不是在整个数据集上,均值和方差有一些小的噪声,因为它只在的mini-batch上计算,比如64或128或256或更大的训练例子。因为均值和方差有一点小噪音,因为它只是由一小部分数据估计得出的。缩放过程从\(z^{[l]}\)到\({\tilde{z}}^{[l]}\),过程也有一些噪音,因为它是用有些噪音的均值和方差计算得出的。

所以和dropout相似,它往每个隐藏层的激活值上增加了噪音,dropout有增加噪音的方式,它使一个隐藏的单元,以一定的概率乘以0,以一定的概率乘以1,所以的dropout含几重噪音,因为它乘以0或1。
对比而言,Batch归一化含几重噪音,因为标准偏差的缩放和减去均值带来的额外噪音。这里的均值和标准差的估计值也是有噪音的,所以类似于dropout,Batch归一化有轻微的正则化效果,因为给隐藏单元添加了噪音,这迫使后部单元不过分依赖任何一个隐藏单元,类似于dropout,它给隐藏层增加了噪音,因此有轻微的正则化效果。因为添加的噪音很微小,所以并不是巨大的正则化效果,可以将Batch归一化和dropout一起使用,如果想得到dropout更强大的正则化效果。
也许另一个轻微非直观的效果是,如果应用了较大的mini-batch,对,比如说,用了512而不是64,通过应用较大的min-batch,减少了噪音,因此减少了正则化效果,这是dropout的一个奇怪的性质,就是应用较大的mini-batch可以减少正则化效果。
说到这儿,会把Batch归一化当成一种正则化,这确实不是其目的,但有时它会对的算法有额外的期望效应或非期望效应。但是不要把Batch归一化当作正则化,把它当作将归一化隐藏单元激活值并加速学习的方式,认为正则化几乎是一个意想不到的副作用。
所以希望这能让更理解Batch归一化的工作,在结束Batch归一化的讨论之前,想确保还知道一个细节。Batch归一化一次只能处理一个mini-batch数据,它在mini-batch上计算均值和方差。所以测试时,试图做出预测,试着评估神经网络,也许没有mini-batch的例子,也许一次只能进行一个简单的例子,所以测试时,需要做一些不同的东西以确保的预测有意义。
神经网络优化篇:详解Batch Norm 为什么奏效?(Why does Batch Norm work?)的更多相关文章
- PHP函数篇详解十进制、二进制、八进制和十六进制转换函数说明
PHP函数篇详解十进制.二进制.八进制和十六进制转换函数说明 作者: 字体:[增加 减小] 类型:转载 中文字符编码研究系列第一期,PHP函数篇详解十进制.二进制.八进制和十六进制互相转换函数说明 ...
- 走向DBA[MSSQL篇] 详解游标
原文:走向DBA[MSSQL篇] 详解游标 前篇回顾:上一篇虫子介绍了一些不常用的数据过滤方式,本篇详细介绍下游标. 概念 简单点说游标的作用就是存储一个结果集,并根据语法将这个结果集的数据逐条处理. ...
- Scala进阶之路-Scala函数篇详解
Scala进阶之路-Scala函数篇详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.传值调用和传名调用 /* @author :yinzhengjie Blog:http: ...
- Canal:同步mysql增量数据工具,一篇详解核心知识点
老刘是一名即将找工作的研二学生,写博客一方面是总结大数据开发的知识点,一方面是希望能够帮助伙伴让自学从此不求人.由于老刘是自学大数据开发,博客中肯定会存在一些不足,还希望大家能够批评指正,让我们一起进 ...
- CentOS 7 下编译安装lnmp之PHP篇详解
一.安装环境 宿主机=> win7,虚拟机 centos => 系统版本:centos-release-7-5.1804.el7.centos.x86_64 二.PHP下载 官网 http ...
- CentOS 7 下编译安装lnmp之MySQL篇详解
一.安装环境 宿主机=> win7,虚拟机 centos => 系统版本:centos-release-7-5.1804.el7.centos.x86_64 二.MySQL下载 MySQL ...
- CentOS 7 下编译安装lnmp之nginx篇详解
一.安装环境 宿主机=> win7,虚拟机 centos => 系统版本:CentOS Linux release 7.5.1804 (Core),ip地址 192.168.1.168 ...
- java提高篇-----详解java的四舍五入与保留位
转载:http://blog.csdn.net/chenssy/article/details/12719811 四舍五入是我们小学的数学问题,这个问题对于我们程序猿来说就类似于1到10的加减乘除那么 ...
- 组件--Fragment(碎片)第二篇详解
感觉之前看的还是不清楚,重新再研究了一次 Fragment常用的三个类: android.app.Fragment 主要用于定义Fragment android.app.FragmentManager ...
- JavaScript基础篇详解
全部的数据类型: 基本数据类型: undefined Number Boolean null String 复杂数据类型: object ①Undefined: >>>声明但未初始化 ...
随机推荐
- CodeForces-339B-Xenia and Ringroad (循环队列,水题)
Xenia lives in a city that has n houses built along the main ringroad. The ringroad houses are numbe ...
- vivo 互联网业务就近路由技术实战
一.问题背景 在vivo互联网业务高速发展的同时,支撑的服务实例规模也越来越大,然而单个机房能承载的机器容量是有限的,于是同城多机房甚至多地域部署就成为了业务在实际部署过程中不得不面临的场景. 一般情 ...
- 清洁低碳环保新能源,3D 光伏与光热发电站可视化
前言 碳达峰.碳中和成为今年两会"热词",在国家政府工作报告中指出,扎实做好碳达峰.碳中和各项工作,制定 2030 年前碳排放达峰行动方案,优化产业结构和能源结构,实现低碳环保节能 ...
- NSSCTF Round#13 web专项
rank:3 flask?jwt? 简单的注册个账号,在/changePassword 下查看页面源代码发现密钥<!-- secretkey: th3f1askisfunny --> ,很 ...
- 【调试】kdump原理及其使用方法
kdump机制 简介 Kdump是在系统崩溃.死锁或死机时用来转储内存运行参数的一个工具和服务,是一种新的crash dump捕获机制,用来捕获kernel crash(内核崩溃)的时候产生的cras ...
- DOCKER本地仓库
概述 随着docker的应用越来越多,安装部署越来越方便,批量自动化的镜像生成和发布都需要docker仓库的本地化应用. 试用了docker的本地仓库功能,简单易上手,记录下来以备后用. 环境 cen ...
- 人人都会Kubernetes(二):使用KRM实现快速部署服务,并且通过域名发布
1. 上节回顾 上一小节<人人都会Kubernetes(一):告别手写K8s yaml,运维效率提升500%>介绍了KRM的一些常用功能,并且使用KRM的DEMO环境,无需安装就可以很方便 ...
- 一文搞清楚Java中的方法、常量、变量、参数
写在开头 在上一篇文章:一文搞清楚Java中的包.类.接口 中我们讲了Java中的包.类和接口,今天继续将剩下的方法.常量.变量以及参数梳理完. Java中的变量与常量 在JVM的运转中,承载的是数据 ...
- mysql之力扣数据库题目620有趣的电影优化记录
闲着没事儿刷刷力扣的数据库题目,题目编号620:有趣的电影,下面是题目描述: 优化前的sql及执行时间: 优化后的sql及执行时间: 这里对筛选条件进行了优化: 1.select * 的查找效率要比逐 ...
- C++模板显示指定类型时使用引用遇到的问题
1.问题 这里我想让模板函数接收int和char类型的参数,并进行相加,显示指定参数类型为int. 第一个调用理论上会自动将char类型强转成int类型,后进行相加: 第二个调用理论上会自动将int类 ...