pytorch 实战教程之 SPP(SPPNet---Spatial Pyramid Pooling)空间金字塔池化网络代码实现 和 SPPF (Spatial Pyramid Pooling Fast)详解
原文作者:aircraft
学习YOLOv5前的准备就是学习DarkNet53网络,FPN特征金字塔网络,PANet路径聚合网络结构,(从SPP到SPPF)SPPF空间金字塔池化等。本篇讲从SPP到SPPF网络结构。。。(其他几篇已经发布在历史博客里------基本YOLO网络的前置学习就在这篇讲的差不多了,后面应该写YOLO目标检测了。。。。)
SPPNet(空间金字塔池化网络)详解
SPPNet(Spatial Pyramid Pooling Network)是何凯明团队在2014年提出的创新架构,核心是空间金字塔池化(SPP)层,解决了传统卷积神经网络必须固定输入尺寸的限制。以下从技术原理到实践应用进行详解:
一、SPPNet的诞生背景
传统CNN的痛点:
- 全连接层需固定输入维度(如AlexNet强制缩放到227×227的图像大小)
- 图像裁剪/变形导致信息丢失(如长宽比失真)---- 想象一下你的小仙女女朋友拍了很多美美哒的照片,这些照片的构图都不同,最后都要缩放到一个固定尺寸,那么每张照片还好看吗???
- 多尺度特征难以有效融合
SPP的核心突破:
- 允许卷积层输出任意尺寸的特征图
- 通过SPP层将动态尺寸特征转换为固定维度向量
- 全连接层无需修改即可处理不同输入尺寸
二、空间金字塔池化(SPP)层原理
1. 结构设计
- 多级空间分箱(Spatial Bins):
- 预设金字塔层级:如
[4×4, 2×2, 1×1]三级网格 - 每级网格将特征图划分为
n×n个子区域
- 预设金字塔层级:如
- 自适应最大池化:
- 每个子区域执行最大池化,输出1个值
- 池化窗口尺寸自动计算:
win_size = ⌈输入尺寸/n⌉ - 步长(stride)自动计算:
stride = ⌊输入尺寸/n⌋
2. 数学形式
- 输入特征图尺寸:
W×H×C(宽×高×通道) - 第k级金字塔输出维度:
n_k × n_k × C - 总输出维度:
(Σ n_k²) × C(固定长度)
示例:
- 三级金字塔
[4×4, 2×2, 1×1] - 输出维度:
(16 + 4 + 1) × C = 21C
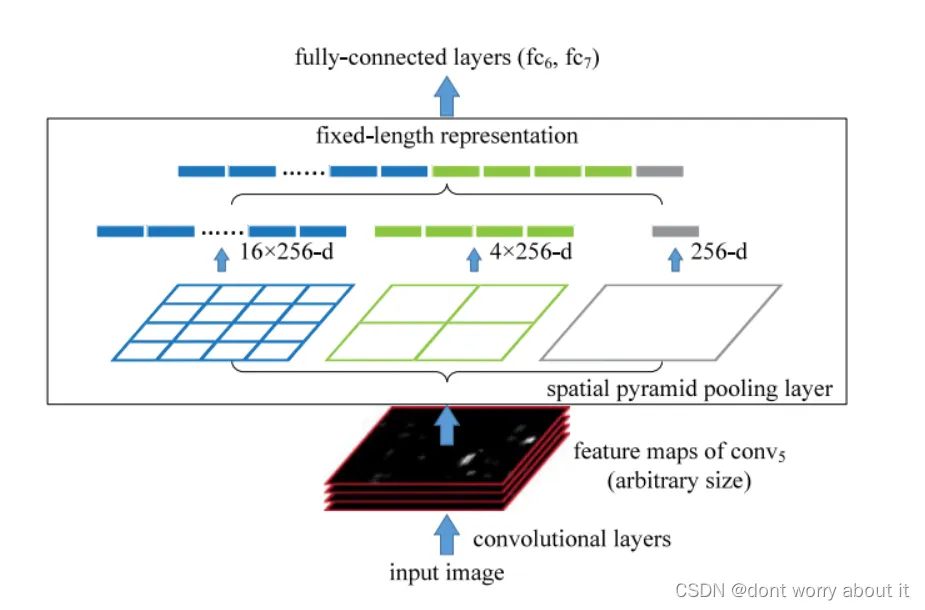
具体流程:
1、特征图分割:SPP 层将输入的特征图分割成多个不同大小的网格,这些网格的大小通常是 1x1、2x2、4x4 、8x8 等等,形成一个金字塔结构,每个网格的大小决定了池化操作的感受野;
2、池化操作:对每个网格进行池化操作,通常使用最大池化(Max Pooling);最大池化会选择每个网格中的最大值作为输出。这样,每个网格都会生成一个固定大小的特征表示,需要注意的是这个池化操作是一个并发的过程;
3、特征拼接:将所有网格的特征表示拼接起来,形成一个固定长度的特征向量;这个特征向量随后可以作为后续全连接层的输入;
为什么很多带全连接层的网络结构都需要固定归一化图像的大小呢(如AlexNet强制缩放到227×227的图像大小)?举个例子就是我在全连接层输出的网络结构是固定大小的,比如是21*512这个大小:
在最后一层卷积层我们已经固定用了512个卷积核,那么输入到全连接层的数据就是 w * h * 512 (特征图像的长宽乘通道数),那么在通道数固定的情况下,图像大小变化的话就会和全连接层对应不上。接口对接不起来!!!
拿全连接层所需数据大小21*512举例,在卷积层输出的通道数固定为512的情况下,我们构建1x1、2x2、4x4的三层空间金字塔池化:
假设我们有一张 448×448 的输入图像,通过卷积层后得到特征图 56×56×512;接下来,我们使用 SPP 层进行处理:
1.特征图分割:
1x1 网格:整个特征图作为一份数据
2x2 网格:特征图被均匀分割成 4 份数据
4x4 网格:特征图被均匀分割为16份数据
2. 池化操作:
1x1 网格:最大池化后的特征图尺寸为 1×1×512;
2x2 网格:最大池化后的特征图尺寸为 2×2×512=4×512=4×512;
4x4 网格:最大池化后的特征图尺寸为 4×4×512=16×512=16×512;
3. 特征拼接:
拼接后的特征向量长度为:21 x 512 =10752 不管你输入图像的大小是多少227x227 ,512x512,318x318也好,经过三层的空间金字塔网络后提取的特征数目都是21份,加上通道数就是 21x512份。这样就不用在意输入图像数据的大小了。
下图就非常鲜明了,厚度就是通道数:

大概代码实现(任意输入图像尺寸,输出的大小一致):
import torch
import torch.nn as nn class SpatialPyramidPooling(nn.Module):
def __init__(self, levels=[4, 2, 1]):
super().__init__()
self.levels = levels def forward(self, x):
N, C, H, W = x.size()
outputs = []
for level in self.levels:
kh = H // level
kw = W // level
pool = nn.MaxPool2d(kernel_size=(kh, kw), stride=(kh, kw))
outputs.append(pool(x).view(N, -1))
return torch.cat(outputs, dim=1) # 使用示例
spp = SpatialPyramidPooling(levels=[4, 2, 1])
input = torch.randn(1, 256, 13, 13) # 任意尺寸输入
output = spp(input) # 输出固定维度: (1, 21 * 256)
代码的隐藏条件
代码隐式要求输入尺寸必须能被所有level整除,否则实际输出网格数会偏离预设level:
- 反例:输入10×10,level=4
- 池化核:10//4=2,步长2×2
- 输出尺寸:
(10-2)/2 +1 =5→ 5×5(而非预设的4×4)
若想不管这个隐藏条件,还可以这样改,使用自适应池化:
class SpatialPyramidPooling(nn.Module):
def __init__(self, levels=[4, 2, 1]):
super().__init__()
self.pools = nn.ModuleList([
nn.AdaptiveMaxPool2d((level, level)) for level in levels
]) def forward(self, x):
N, C, _, _ = x.size()
outputs = [pool(x).view(N, -1) for pool in self.pools]
return torch.cat(outputs, dim=1)
AdaptiveMaxPool2d直接强制输出目标尺寸(如4×4),无需计算核尺寸
局限性
池化信息损失:
- 最大池化丢弃非最大值信息
- 后续的ROI Align改用双线性插值缓解此问题
计算资源消耗:
- 多级池化增加内存占用
- 实时性弱于纯全卷积网络(FCN)
总结
SPPNet通过空间金字塔池化,首次实现了CNN对任意尺寸输入的处理,奠定了多尺度特征融合的基础。其核心思想被后续众多模型(如Fast R-CNN、Mask R-CNN)继承发展,是深度学习发展史上的重要里程碑。理解SPP机制对掌握现代目标检测和图像分类模型至关重要。
SPPF(Spatial Pyramid Pooling Fast)详解
SPPF(空间金字塔快速池化)是SPPNet的改进版本,由YOLO系列(如YOLOv5、YOLOv7)引入,旨在保持多尺度特征融合能力的同时显著提升计算效率。其核心思想是通过串行重复池化操作替代传统金字塔并行池化,减少计算冗余。以下是详细解析:
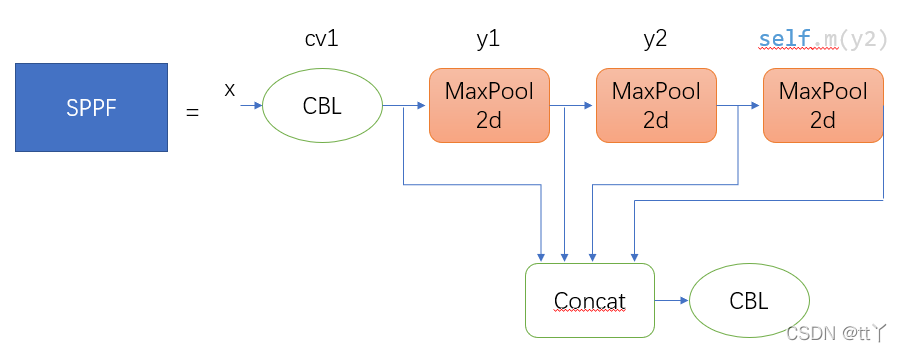
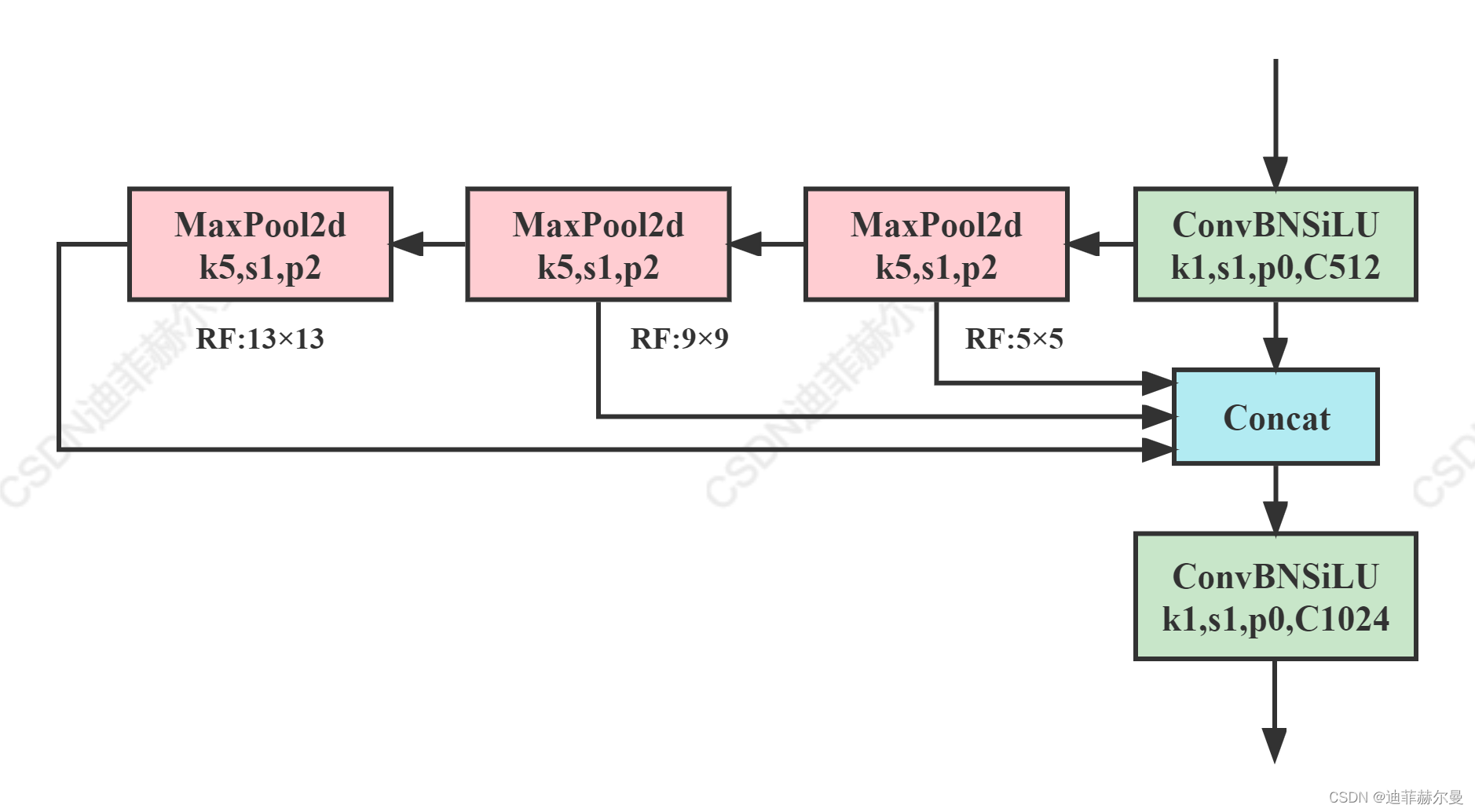
一、SPPF与SPP的结构对比
| 模块 | 池化方式 | 计算路径 | 参数量 | 输出特征维度 |
|---|---|---|---|---|
| SPP | 并行多级池化(如4×4, 2×2, 1×1) | 独立分支 | 多 | 多级特征拼接 |
| SPPF | 串行重复池化(如三次5×5池化) | 单链叠加 | 少 | 等效金字塔融合 |
| 特性 | SPP | SPPF |
|---|---|---|
| 多尺度特征来源 | 离散分级(4×4, 2×2, 1×1) | 连续叠加(5→9→13感受野) |
| 计算效率 | 低(多分支并行池化) | 高(单链串行池化,GPU优化) |
| 硬件友好性 | 内存碎片化 | 连续内存操作 |
| 适用场景 | 分类网络(需全连接层) | 检测网络(全卷积架构) |
二、SPPF核心原理
1. 串行池化设计
- 池化核尺寸固定:通常使用5×5池化窗口,重复三次
- 步长固定为1:通过填充(padding)保持特征图尺寸不变
- 动态感受野叠加:每次池化扩大感受野,等效多尺度特征提取
2. 数学过程
输入特征图尺寸:W×H×C
- 第一次池化:5×5池化 → 输出 W×H×C
- 第二次池化:5×5池化 → 输出 W×H×C
- 第三次池化:5×5池化 → 输出 W×H×C
- 特征拼接:原始输入 + 三次池化输出 → 最终维度 4C 而SPPF中的W×H始终不变,SPP则是通道数和金字塔后输出的数据不变
等效感受野:
- 三次5×5池化 ≈ 单次13×13池化(5+(5-1)x2 ) = 13
3. 计算效率优化
- 参数共享:三次池化使用相同核尺寸,无需额外参数
- 内存连续性:串行操作减少内存碎片,提升GPU利用率
- FLOPs对比(以256×13×13输入为例):
- SPP:约 1.2 GFLOPs
- SPPF:约 0.8 GFLOPs (速度提升33%)
具体示例演示
Case 1:输入尺寸 13×13×256
第一次池化:
- 输入:13×13×256
- 输出:13×13×256(保持尺寸)
- 感受野:5×5(覆盖输入中5×5区域)
第二次池化:
- 输入:13×13×256
- 输出:13×13×256
- 感受野:9×9(叠加两次5×5池化)
第三次池化:
- 输入:13×13×256
- 输出:13×13×256
- 感受野:13×13(叠加三次池化覆盖全图)
拼接结果:
- 输出尺寸:13×13×(256×4) = 13×13×1024
虽然SPPF输出的空间尺寸 (W×H) 仍与输入相关,但后续网络通过 全局池化(Global Pooling) 或 自适应层(Adaptive Layers) 将其转换为固定维度

SPPF中的感受野计算示例
以YOLOv5的SPPF模块为例(三次5×5池化,步长=1):
| 层数 | 操作 | 核尺寸(k) | 步长(stride) | 感受野计算 | 累计感受野 |
|---|---|---|---|---|---|
| 1 | 输入 | - | - | 初始感受野=1 | 1×1 |
| 2 | 第一次池化 | 5×5 | 1 | 1 + (5-1)*1 = 5 | 5×5 |
| 3 | 第二次池化 | 5×5 | 1 | 5 + (5-1)*1 * 1 = 9 | 9×9 |
| 4 | 第三次池化 | 5×5 | 1 | 9 + (5-1)*1 * 1 * 1 = 13 | 13×13 |
- 不强制固定维度:保留空间信息以支持目标检测中的位置敏感任务。
- 与后续卷积层兼容:YOLO的检测头(Head)直接处理可变尺寸特征图。
- 错误理解:将SPPF用于分类任务(需全连接层)时,才需要额外添加全局池化。
- 正确场景:在YOLO等检测网络中,SPPF天然适配全卷积结构,无需任何后续约束
YOLO中SPPF的实际应用:
在YOLOv5/v7中,SPPF模块后直接连接卷积层,无需全局池化:
# YOLOv5的C3模块(包含SPPF)
class C3(nn.Module):
def __init__(self, c1, c2):
super().__init__()
self.sppf = SPPF(c1) # 输出H×W×4C1
self.conv = nn.Conv2d(4*c1, c2, 1) # 压缩通道到C2 def forward(self, x):
x = self.sppf(x) # H×W×4C1 → 空间维度保留
x = self.conv(x) # H×W×C2 → 输入检测头
return x
三、SPPF的具体实现
1. PyTorch代码示例:
import torch
import torch.nn as nn class SPPF(nn.Module):
def __init__(self, in_channels):
super().__init__()
self.pool = nn.MaxPool2d(kernel_size=5, stride=1, padding=2) def forward(self, x):
x1 = self.pool(x)
x2 = self.pool(x1)
x3 = self.pool(x2)
return torch.cat([x, x1, x2, x3], dim=1) # 输入示例:batch=1, channels=256, size=13x13
input = torch.randn(1, 256, 13, 13)
sppf = SPPF(256)
output = sppf(input) # 输出维度:[1, 1024, 13, 13]
2. 关键参数配置
- 核尺寸:通常为5×5(平衡感受野与计算量)
- 填充策略:
padding=kernel_size//2(保持尺寸不变) - 拼接方式:沿通道维度拼接原始输入与池化结果
四、SPPF的优势分析
计算效率提升:
- 减少分支操作,利用串行流水线加速
- YOLOv5中SPPF比SPP快2.5倍(相同硬件)
多尺度特征融合增强:
- 三次池化等效于13×13、9×9、5×5多级感受野
- 保留更精细的局部特征(对比SPP的跳跃式分级)
硬件友好性:
- 连续内存访问优化缓存命中率
- 适合部署到边缘设备(如Jetson系列)
模型兼容性:
- 输入输出尺寸一致,可直接替换SPP模块
- 无缝集成到ResNet、CSPNet等主流骨干网络
五、SPPF在YOLO中的实际应用
1. YOLOv5网络结构集成
Backbone
├── Focus
├── Conv
├── C3
└── SPPF # 替换原始SPP模块
2. 性能提升对比(COCO数据集)
| 模型 | mAP@0.5 | FPS (Tesla T4) | 参数量 (M) |
|---|---|---|---|
| YOLOv5s | 37.2 | 125 | 7.2 |
| YOLOv5s+SPPF | 37.8 | 142 | 7.3 |
六、SPPF的局限性
小物体检测精度衰减:
- 多次池化可能模糊微小物体的细节特征
- 需配合FPN(特征金字塔)使用以缓解此问题
理论感受野与实际差异:
- 串行池化的等效感受野为线性增长,弱于SPP的指数级覆盖
通道膨胀问题:
- 输出通道数变为输入4倍,可能增加后续卷积计算量
七、改进变体(下面这些都是不断改进升级的版本)
SPPF+SE:
- 加入通道注意力机制(Squeeze-and-Excitation)
- 提升重要通道的权重分配
ASPPF(Atrous SPPF):
- 使用空洞池化(Dilated Pooling)扩大感受野
- 减少下采样带来的信息损失
轻量化SPPF:
- 采用深度可分离卷积(Depthwise Separable Conv)
- 适用于移动端部署
还有SimSPPF,SPPCSPC,SPPFCSPC+都可以去了解一下都是YOLO不断升级中改进出来的。
八、总结
SPPF通过巧妙的串行池化结构,在保持多尺度特征融合能力的同时,显著提升了计算效率。其设计体现了“简单即有效”的优化哲学,成为实时目标检测模型的标配模块。理解SPPF的工作原理对于优化模型速度和精度平衡至关重要,特别是在边缘计算和实时视频分析场景中具有重要价值。
参考博客:https://blog.csdn.net/CITY_OF_MO_GY/article/details/143897303
https://developer.aliyun.com/article/1509544
https://blog.csdn.net/weixin_38346042/article/details/131796263
pytorch 实战教程之 SPP(SPPNet---Spatial Pyramid Pooling)空间金字塔池化网络代码实现 和 SPPF (Spatial Pyramid Pooling Fast)详解的更多相关文章
- 空间金字塔池化(Spatial Pyramid Pooling, SPP)原理和代码实现(Pytorch)
想直接看公式的可跳至第三节 3.公式修正 一.为什么需要SPP 首先需要知道为什么会需要SPP. 我们都知道卷积神经网络(CNN)由卷积层和全连接层组成,其中卷积层对于输入数据的大小并没有要求,唯一对 ...
- Spatial pyramid pooling (SPP)-net (空间金字塔池化)笔记(转)
在学习r-cnn系列时,一直看到SPP-net的身影,许多有疑问的地方在这篇论文里找到了答案. 论文:Spatial Pyramid Pooling in Deep Convolutional Net ...
- 空间金字塔池化(Spatial Pyramid Pooling,SPP)
基于空间金字塔池化的卷积神经网络物体检测 原文地址:http://blog.csdn.net/hjimce/article/details/50187655 作者:hjimce 一.相关理论 本篇博文 ...
- SPPNet论文翻译-空间金字塔池化Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
http://www.dengfanxin.cn/?p=403 原文地址 我对物体检测的一篇重要著作SPPNet的论文的主要部分进行了翻译工作.SPPNet的初衷非常明晰,就是希望网络对输入的尺寸更加 ...
- SPP空间金字塔池化技术的直观理解
空间金字塔池化技术, 厉害之处,在于使得我们构建的网络,可以输入任意大小的图片,不需要经过裁剪缩放等操作. 是后续许多金字塔技术(psp,aspp等)的起源,主要的目的都是为了获取场景语境信息,获取上 ...
- SPPNet(特征金字塔池化)学习笔记
SPPNet paper:Spatial pyramid pooling in deep convolutional networks for visual recognition code 首先介绍 ...
- 《手把手教你》系列技巧篇(二十九)-java+ selenium自动化测试- Actions的相关操作上篇(详解教程)
1.简介 有些测试场景或者事件,Selenium根本就没有直接提供方法去操作,而且也不可能把各种测试场景都全面覆盖提供方法去操作.比如:就像鼠标悬停,一般测试场景鼠标悬停分两种常见,一种是鼠标悬停在某 ...
- 《手把手教你》系列技巧篇(三十八)-java+ selenium自动化测试-日历时间控件-下篇(详解教程)
1.简介 理想很丰满现实很骨感,在应用selenium实现web自动化时,经常会遇到处理日期控件点击问题,手工很简单,可以一个个点击日期控件选择需要的日期,但自动化执行过程中,完全复制手工这样的操作就 ...
- 《手把手教你》系列技巧篇(四十五)-java+ selenium自动化测试-web页面定位toast-上篇(详解教程)
1.简介 在使用appium写app自动化的时候介绍toast的相关元素的定位,在Web UI测试过程中,也经常遇到一些toast,那么这个toast我们这边如何进行测试呢?今天宏哥就分两篇介绍一下. ...
- 《手把手教你》系列技巧篇(四十六)-java+ selenium自动化测试-web页面定位toast-下篇(详解教程)
1.简介 终于经过宏哥的不懈努力,偶然发现了一个toast的web页面,所以直接就用这个页面来夯实一下,上一篇学过的知识-处理toast元素. 2.安居客 事先声明啊,宏哥没有收他们的广告费啊,纯粹是 ...
随机推荐
- UTS Open '21 P6 - Terra Mater
传送门 前言 本题是一道很好的"dp"题,无论是正难反易,还是模型转化都值得称赞,尤其是最后的神之一手,让我大脑宕机. 题意描述 给定一个长度为 \(N\) 的序列 \(H\),修 ...
- Win7下的文件权限
平常编写的程序总会有配置功能,然后配置肯定是以文本文件的方式存放在目录下.平常自己电脑测试没问题 发到客户那里总会有各种乱七八糟的状况 反映配置无法保存.先前早知道win7有管理员权限的机制,然后还刻 ...
- 微信小程序音频播放
微信小程序音频播放 // 开启播放音频 startAudio(){ const innerAudioContext = uni.createInnerAudioContext();//创建并返回内部 ...
- 从DNS配置到Pacemaker部署:一步步教你在Linux平台上实现AlwaysOn集群
从DNS配置到Pacemaker部署:一步步教你在Linux平台上实现AlwaysOn集群 AlwaysOn集群是SQL Server里唯一推荐的高可用性架构, 在AlwaysOn高可用性架构中,有非 ...
- oacle12c 静默安装
一.环境 系统 : CentOS 7.x硬件:虚拟机处理器4核 内存 4g 硬盘1:40g 硬盘2:20g 1.上传安装包,安装压缩组件 uname -ryum install -y unzip zi ...
- FLink17--全窗口聚合方法1--ApplyWindowApp
一.依赖 二.代码 package net.xdclass.class11; import java.util.List; import java.util.stream.Collectors; im ...
- 大人,时代变了! 赶快把自有业务的本地AI“模型”训练起来!
1 大人,时代变了! 赶快把自有业务的本地AI"模型"训练起来! 1.1 背景 目前AI已经大行其道,chatGPT.DeepSeek等如雨后春笋般涌现出来,笔者做为一个守旧派 ...
- Vue实现企业微信扫码登录
Vue实现企业微信扫码登录 企业微信扫码登录原理 构建企业微信登录二维码 获取访问令牌access_token 请求方式:GET(HTTPS)请求URL:https://qyapi.wei ...
- UE蓝图:准心锁定敌人实现,通过UI锁定敌人
UI控件蓝图 1.让UI动起来 (1) 创建事件AimMoveEvent,接受参数Dir,即UI的移动方向 (2) *5是控制ui的移动速度(阅者可自行调整,建议提升为参数),CorssHairP ...
- 批量视频剪辑软件开心版合集——CRVideoMate、固乔剪辑助手、批量剪辑大师MV批量创作大师、ai全自动剪辑
CRVideoMate(推荐) 非常好用的批量剪辑工具,如果是简单的基础处理完全是够用了. 软件的官网:http://www.cr-soft.net/crvideomate.html 如果经济允许推荐 ...