第1节 flume:12、flume的load_balance实现机制
1.5、flume的负载均衡load balancer
负载均衡是用于解决一台机器(一个进程)无法解决所有请求而产生的一种算法。Load balancing Sink Processor 能够实现 load balance 功能,如下图Agent1 是一个路由节点,负责将 Channel 暂存的 Event 均衡到对应的多个 Sink组件上,而每个 Sink 组件分别连接到一个独立的 Agent 上,示例配置,如下所示:
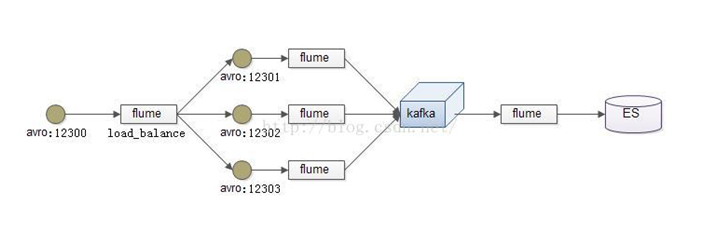
在此处我们通过三台机器来进行模拟flume的负载均衡
三台机器规划如下:
node01:采集数据,发送到node02和node03机器上去
node02:接收node01的部分数据
node03:接收node01的部分数据
第一步:开发node01服务器的flume配置
node01服务器配置:
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin/conf
vim load_balancer_client.conf
#agent name
a1.channels = c1
a1.sources = r1
a1.sinks = k1 k2
#set gruop
a1.sinkgroups = g1
#set channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.sources.r1.channels = c1
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /export/servers/taillogs/access_log
# set sink1
a1.sinks.k1.channel = c1
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = node02
a1.sinks.k1.port = 52020
# set sink2
a1.sinks.k2.channel = c1
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = node03
a1.sinks.k2.port = 52020
#set sink group
a1.sinkgroups.g1.sinks = k1 k2
#set failover
a1.sinkgroups.g1.processor.type = load_balance
a1.sinkgroups.g1.processor.backoff = true
a1.sinkgroups.g1.processor.selector = round_robin
a1.sinkgroups.g1.processor.selector.maxTimeOut=10000
第二步:开发node02服务器的flume配置
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin/conf
vim load_banlancer_server.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = avro
a1.sources.r1.channels = c1
a1.sources.r1.bind = node02
a1.sources.r1.port = 52020
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
第三步:开发node03服务器flume配置
node03服务器配置
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin/conf
vim load_banlancer_server.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = avro
a1.sources.r1.channels = c1
a1.sources.r1.bind = node03
a1.sources.r1.port = 52020
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
第四步:准备启动flume服务
启动node03的flume服务
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin
bin/flume-ng agent -n a1 -c conf -f conf/load_balancer_server.conf -Dflume.root.logger=DEBUG,console
启动node02的flume服务
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin
bin/flume-ng agent -n a1 -c conf -f conf/load_balancer_server.conf -Dflume.root.logger=DEBUG,console
启动node01的flume服务
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin
bin/flume-ng agent -n a1 -c conf -f conf/load_balancer_client.conf -Dflume.root.logger=DEBUG,console
第五步:node01服务器运行脚本产生数据
cd /export/servers/shells
sh tail-file.sh
第1节 flume:12、flume的load_balance实现机制的更多相关文章
- Flume篇---Flume安装配置与相关使用
一.前述 Copy过来一段介绍Apache Flume 是一个从可以收集例如日志,事件等数据资源,并将这些数量庞大的数据从各项数据资源中集中起来存储的工具/服务,或者数集中机制.flume具有高可用, ...
- [Flume][Kafka]Flume 与 Kakfa结合例子(Kakfa 作为flume 的sink 输出到 Kafka topic)
Flume 与 Kakfa结合例子(Kakfa 作为flume 的sink 输出到 Kafka topic) 进行准备工作: $sudo mkdir -p /flume/web_spooldir$su ...
- [Flume]使用 Flume 来传递web log 到 hdfs 的例子
[Flume]使用 Flume 来传递web log 到 hdfs 的例子: 在 hdfs 上创建存储 log 的目录: $ hdfs dfs -mkdir -p /test001/weblogsfl ...
- flume到flume消息传递
环境:两台虚拟机( 每台都有flume) 第一台slave作为消息的产生者 第二台master作为消息的接收者 IP(192.168.83.133) 原理:通过监听slave中文件的变化,获取变 ...
- 12.Flume的安装
先把flume包上传并解压 给flume创建一个软链接 给flume配置环境变量 #flume export FLUME_HOME=/opt/modules/flume export PATH=$PA ...
- 整体认识flume:Flume介绍、分布式安装、常见问题及解决方案
问题导读 1.什么是flume? 2.flume包含哪些组件? 3.Flume在读取utf-8格式的文件时会出现解析不了时间戳,该如何解决? Flume是一个分布式.可靠.和高可用的海量日志采集.聚合 ...
- Flume学习——Flume中事务的定义
首先要搞清楚的问题是:Flume中的事务用来干嘛? Flume中的事务用来保证消息的可靠传递. 当使用继承自BasicChannelSemantics的Channel时,Flume强制在操作Chann ...
- Flume学习——Flume的架构
Flume有三个组件:Source.Channel 和 Sink.在源码中对应同名的三个接口. When a Flume source receives an event, it stores it ...
- 【Flume】flume于transactionCapacity和batchSize进行详细的分析和质疑的概念
我不知道你用flume读者熟悉无论这两个概念 一开始我是有点困惑,? 没感觉到transactionCapacity的作用啊? batchSize又是干啥的啊? -- -- 带着这些问题,我们深入源代 ...
随机推荐
- 用matplotlib画线
1:matplotlib基础 Matplotlib 是一个 Python 的 2D绘图库,它以各种硬拷贝格式和跨平台的交互式环境生成出版质量级别的图形[1] . 通过 Matplotlib,开发者可以 ...
- [UE4]C++实现动态加载的问题:LoadClass()和LoadObject()
http://aigo.iteye.com/blog/2281558 原文作者:@玄冬Wong 相关内容:C++静态加载问题:ConstructorHelpers::FClassFinder()和FO ...
- AES 加密 PHP 和 JAVA 互通
PHP代码: <?php class Security { public static function encrypt($input, $key) { $size = mcrypt_get_b ...
- 洛谷P2018 消息传递
P2018 消息传递 题目描述 巴蜀国的社会等级森严,除了国王之外,每个人均有且只有一个直接上级,当然国王没有上级.如果A是B的上级,B是C的上级,那么A就是C的上级.绝对不会出现这样的关系:A是B的 ...
- Noip2016day1 玩具迷题toy
题目描述 小南有一套可爱的玩具小人, 它们各有不同的职业. 有一天, 这些玩具小人把小南的眼镜藏了起来. 小南发现玩具小人们围成了一个圈,它们有的面朝圈内,有的面朝圈外.如下图: 这时singer告诉 ...
- codevs 3342绿色通道
3342 绿色通道 时间限制: 1 s 空间限制: 256000 KB 题目等级 : 黄金 Gold
- 支持通配符查询的k-gram索引
k-gram索引的通配符查询处理技术称为k-gram索引. 一个k-gram代表由k个字符组成的序列.对于词项castle来说,cas.ast.stl都是3-gram.我们用特殊的字符$来标识词项的开 ...
- docker 使用数据库mysql
1. docker pull mysql 获取mysql镜像 2. docker images 查看镜像列表 3. docker run -itd -P mysql bash :启动mysql镜像 ...
- 微信小程序入门文档
一 基本介绍 微信专门为小程序开发了一个ide叫做微信开发者工具 最新一版的微信开发者工具,把微信公众号的调试开发工作也集成了进去,可以更换开发模式. https://mp.weixin.qq.com ...
- Struts2 拦截器(Interceptor )原理和配置
http://blog.csdn.net/kingmax54212008/article/details/51777851