scrapy爬虫框架之理解篇(个人理解)
提问: 为什么使用scrapy框架来写爬虫 ?
在python爬虫中:requests + selenium 可以解决目前90%的爬虫需求,难道scrapy 是解决剩下的10%的吗?显然不是。scrapy框架是为了让我们的爬虫更强大、更高效。接下来我们一起学习一下它吧。
1.scrapy 的基础概念:
scrapy 是一个为了爬取网站数据,提取结构性数据而编写的应用框架,我们只需要实现少量代码,就能够快速的抓取到数据内容。Scrapy 使用了 Twisted['twɪstɪd](其主要对手是Tornado)异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
http://scrapy-chs.readthedocs.io/zh_CN/1.0/intro/overview.html

2. scrapy 的工作流程:
之前我们所写爬虫的流程:
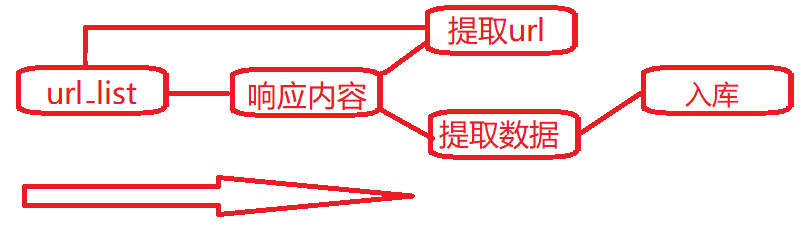
那么 scrapy是如何帮助我们抓取数据的呢?
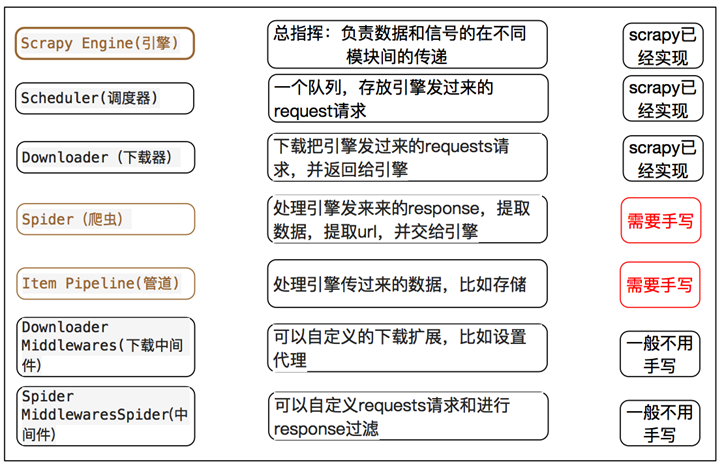
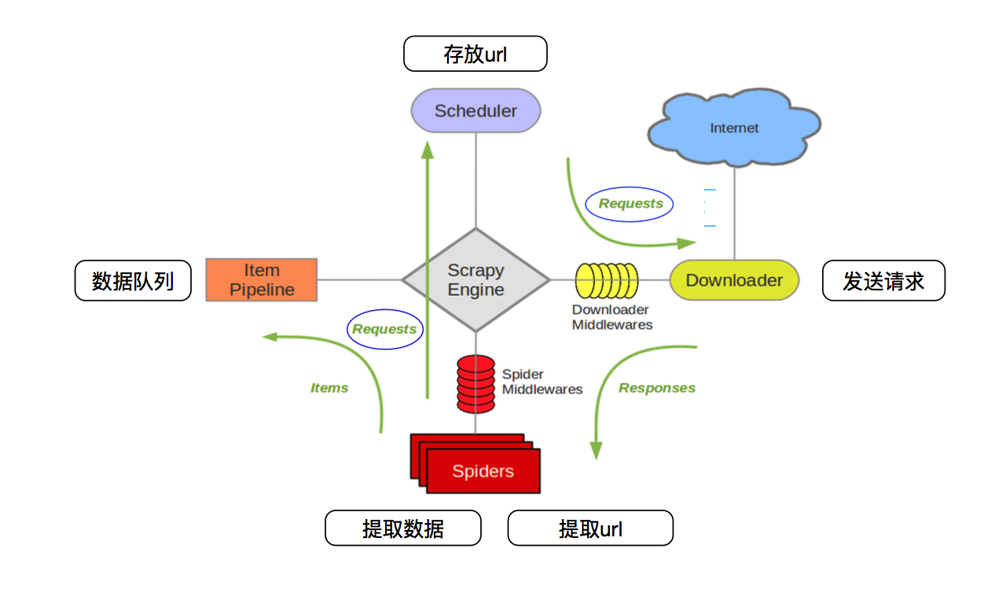
scrapy框架的工作流程:1.首先Spiders(爬虫)将需要发送请求的url(requests)经ScrapyEngine(引擎)交给Scheduler(调度器)。
2.Scheduler(排序,入队)处理后,经ScrapyEngine,DownloaderMiddlewares(可选,主要有User_Agent, Proxy代理)交给Downloader。
3.Downloader向互联网发送请求,并接收下载响应(response)。将响应(response)经ScrapyEngine,SpiderMiddlewares(可选)交给Spiders。
4.Spiders处理response,提取数据并将数据经ScrapyEngine交给ItemPipeline保存(可以是本地,可以是数据库)。
提取url重新经ScrapyEngine交给Scheduler进行下一个循环。直到无Url请求程序停止结束。
scrapy爬虫框架之理解篇(个人理解)的更多相关文章
- Scrapy爬虫框架(实战篇)【Scrapy框架对接Splash抓取javaScript动态渲染页面】
(1).前言 动态页面:HTML文档中的部分是由客户端运行JS脚本生成的,即服务器生成部分HTML文档内容,其余的再由客户端生成 静态页面:整个HTML文档是在服务器端生成的,即服务器生成好了,再发送 ...
- Python之Scrapy爬虫框架安装及简单使用
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- Python爬虫教程-31-创建 Scrapy 爬虫框架项目
本篇是介绍在 Anaconda 环境下,创建 Scrapy 爬虫框架项目的步骤,且介绍比较详细 Python爬虫教程-31-创建 Scrapy 爬虫框架项目 首先说一下,本篇是在 Anaconda 环 ...
- 手把手教你如何新建scrapy爬虫框架的第一个项目(上)
前几天给大家分享了如何在Windows下创建网络爬虫虚拟环境及如何安装Scrapy,还有Scrapy安装过程中常见的问题总结及其对应的解决方法,感兴趣的小伙伴可以戳链接进去查看.关于Scrapy的介绍 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影
前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大家讲解一个完整爬虫的流程. 工具和环境 语言:python 2 ...
- scrapy爬虫框架学习笔记(一)
scrapy爬虫框架学习笔记(一) 1.安装scrapy pip install scrapy 2.新建工程: (1)打开命令行模式 (2)进入要新建工程的目录 (3)运行命令: scrapy sta ...
- Scrapy爬虫框架中的两个流程
下面对比了Scrapy爬虫框架中的两个流程—— ① Scrapy框架的基本运作流程:② Spider或其子类的几个方法的执行流程. 这两个流程是互相联系的,可对比学习. 1 ● Scrapy框架的基本 ...
- Python-S9-Day126——Scrapy爬虫框架
01 今日内容概要 02 内容回顾和补充:scrapy 03 内容回顾和补充:网络和并发编程 04 Scrapy爬虫框架:pipeline做持久化(一) 05 Scrapy爬虫框架:pipeline做 ...
- 第十七节:Scrapy爬虫框架之item.py文件以及spider中使用item
Scrapy原理图: item位于原理图的最左边 item.py文件是报存爬取数据的容器,他使用的方法和字典很相似,但是相比字典item多了额外的保护机制,可以避免拼写错误或者定义错误. 1.创建it ...
随机推荐
- How many Knight Placing? UVA - 11091
How many Knight Placing? Time Limit: 3000MS Memory Limit: Unknown 64bit IO Format: %lld & %l ...
- Java面向对象 继承(上)
Java面向对象 继承 知识概要: (1)继承的概述 (2)继承的特点 (3)super关键字 (4)函数覆盖 (5) 子类的实例化过程 (6) final关键字 (1)继承 ...
- intellij idea 插件开发--快速定位到mybatis mapper文件中的sql
intellij idea 提供了openApi,通过openApi我们可以自己开发插件,提高工作效率.这边直接贴个链接,可以搭个入门的demo:http://www.jianshu.com/p/24 ...
- iOS10新特性之SiriKit
在6月14日凌晨的WWDC2016大会上,苹果提出iOS10是一次里程碑并且推出了十个新特性,大部分的特性是基于iPhone自身的原生应用的更新,具体的特性笔者不在这里再次叙述,请看客们移步WWDC2 ...
- hdu5696 区间的价值
区间的价值 我们定义"区间的价值"为一段区间的最大值*最小值. 一个区间左端点在L,右端点在R,那么该区间的长度为(R-L+1). 现在聪明的杰西想要知道,对于长度为k的区间,最大 ...
- Nhibernate/Hibernate 使用多参数存儲過程 出現could not execute query,Could not locate named parameter等錯誤解決
<?xml version="1.0" encoding="utf-8" ?> <hibernate-mapping xmlns=" ...
- Emgu.CV(三)
像素交换 private void btn_Exchange_Click(object sender, EventArgs e) { if (imageBox1.Image != null) { va ...
- visual Studio 无法调试,提示程序跟踪已退出
今天在打码出现了vs无法调试,我在网上查了很久没有发现一个方法. vs点击启动时,出现了一下提示 程序"[12648] *.vshost.exe: 程序跟踪"已退出,返回值为 0 ...
- 张高兴的 UWP 开发笔记:手机状态栏 StatusBar
UWP 有关应用标题栏 TitleBar 的文章比较多,但介绍 StatusBar 的却没几篇,在这里随便写写.状态栏 StatusBar 用法比较简单,花点心思稍微设计一下,对应用会是个很好的点缀. ...
- 【转】vim替换命令
vim替换命令 free:此文后面涉及了正则表达式,随便看了一下,觉得正则表达式有时间学一学对于在Linux下操作也是方便许多 替換(substitute) :[range]s/pattern/str ...