K-MEANS算法及sklearn实现
K-MEANS算法
聚类概念:
1.无监督问题:我们手里没有标签
2.聚类:相似的东西分到一组
3.难点:如何评估,如何调参
4.要得到簇的个数,需要指定K值
5.质心:均值,即向量各维取平均即可
6.距离的度量:常用欧几里得距离和余弦相似度
7.优化目标:min$$ min \sum_{i=0}^k \sum_{C_j=0} dist(c_i,x)^2$$
工作流程:
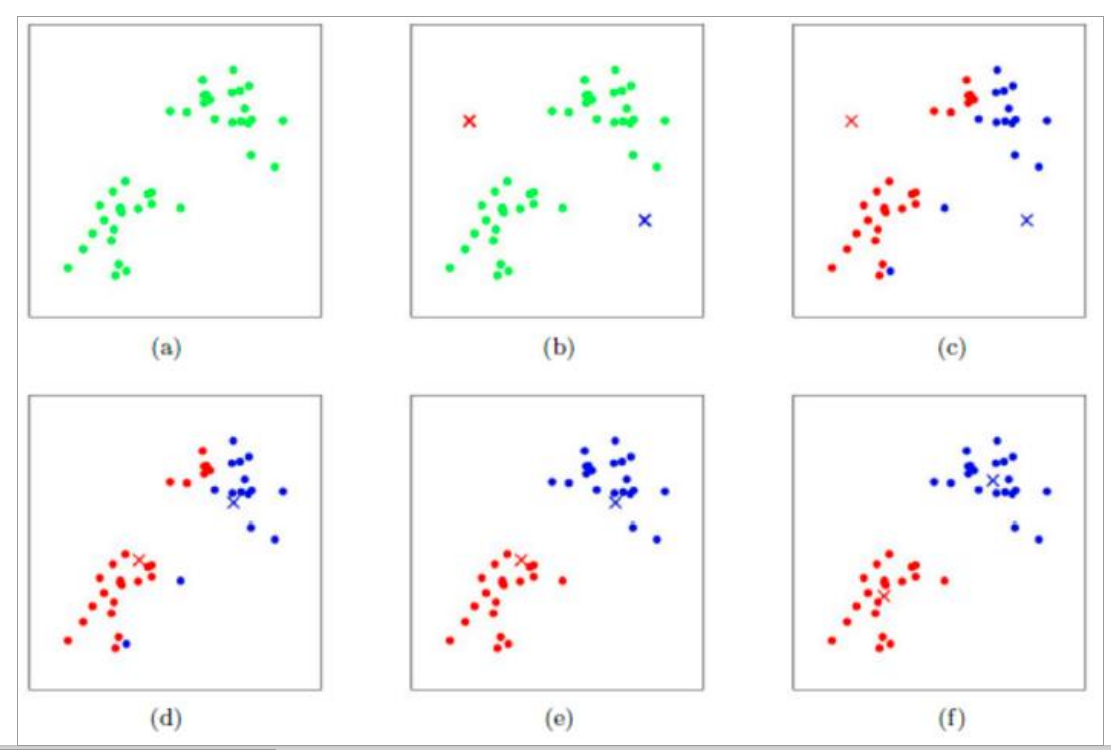
(a)读入数据
(b)随机初始化两个点
(c)计算每个点到质心的距离,离那个质心距离近,就暂时归为那类
(d)重新计算评估指标,更新质心,执行c动作
(e)重新更新质心
(f)重新计算质心的距离,进行分类,直到质心不在发生变化
优势:
简单、快速、适合常规数据集
劣势:
K值难确定
复杂度与样本呈线性关系
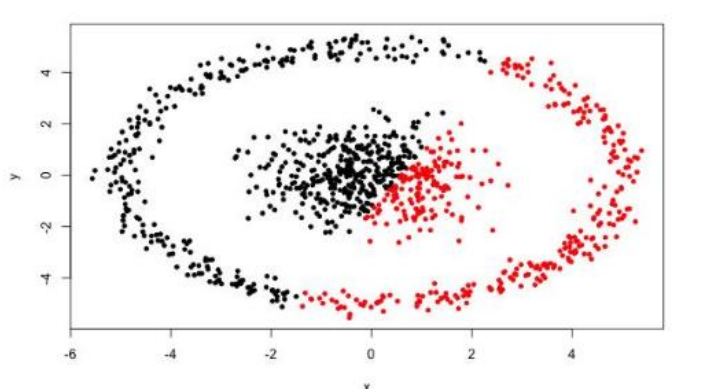
很难发现任意形状的簇,如下图:
sklearn实现
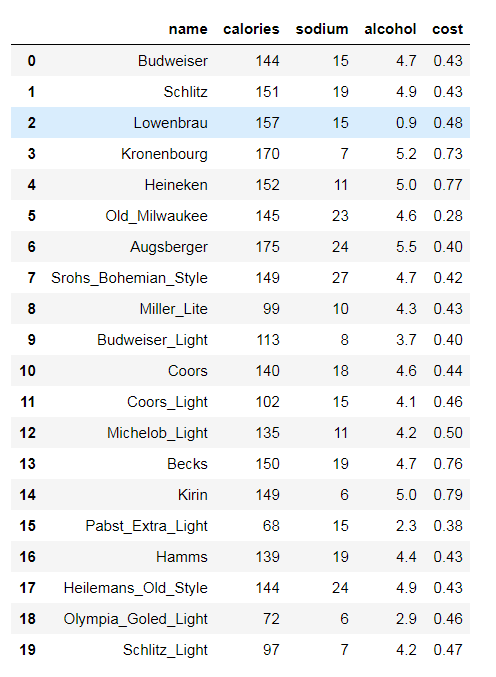
#数据读入
# beer dataset
import pandas as pd
beer = pd.read_csv('data.txt',sep=' ')
beer
X = beer[["calories","sodium","alcohol","cost"]]
from sklearn.cluster import KMeans
km = KMeans(n_clusters = 3).fit(X)
km2 = KMeans(n_clusters = 2).fit(X)
print(km.labels_)
array([0, 0, 0, 0, 0, 0, 0, 0, 2, 2, 0, 2, 0, 0, 0, 1, 0, 0, 1, 2])
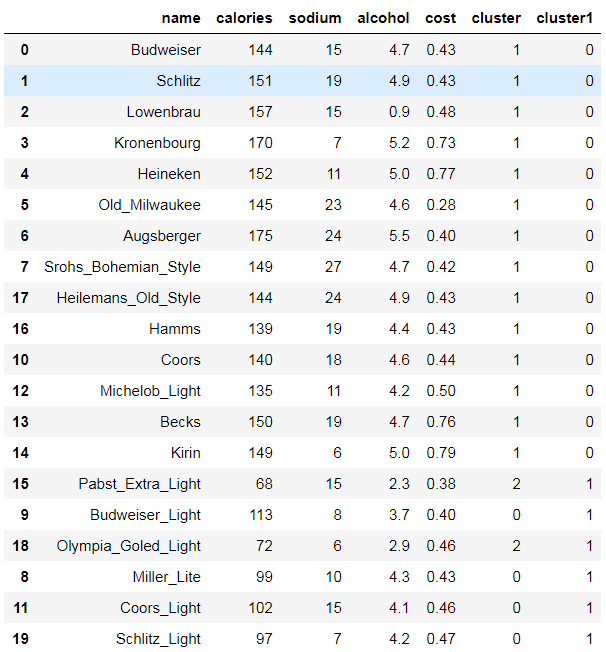
beer['cluster'] = km.labels_
beer['cluster1'] = km2.labels_
beer.sort_values('cluster')
beer.sort_values('cluster1')
K-MEANS算法及sklearn实现的更多相关文章
- KNN 与 K - Means 算法比较
KNN K-Means 1.分类算法 聚类算法 2.监督学习 非监督学习 3.数据类型:喂给它的数据集是带label的数据,已经是完全正确的数据 喂给它的数据集是无label的数据,是杂乱无章的,经过 ...
- K-means算法
K-means算法很简单,它属于无监督学习算法中的聚类算法中的一种方法吧,利用欧式距离进行聚合啦. 解决的问题如图所示哈:有一堆没有标签的训练样本,并且它们可以潜在地分为K类,我们怎么把它们划分呢? ...
- 聚类--K均值算法:自主实现与sklearn.cluster.KMeans调用
1.用python实现K均值算法 import numpy as np x = np.random.randint(1,100,20)#产生的20个一到一百的随机整数 y = np.zeros(20) ...
- SK-learn实现k近邻算法【准确率随k值的变化】-------莺尾花种类预测
代码详解: from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split fr ...
- 机器学习03:K近邻算法
本文来自同步博客. P.S. 不知道怎么显示数学公式以及排版文章.所以如果觉得文章下面格式乱的话请自行跳转到上述链接.后续我将不再对数学公式进行截图,毕竟行内公式截图的话排版会很乱.看原博客地址会有更 ...
- k邻近算法(KNN)实例
一 k近邻算法原理 k近邻算法是一种基本分类和回归方法. 原理:K近邻算法,即是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例,这K个实例的多数属于某个类,就把该输入实 ...
- 机器学习——KNN算法(k近邻算法)
一 KNN算法 1. KNN算法简介 KNN(K-Nearest Neighbor)工作原理:存在一个样本数据集合,也称为训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分 ...
- 机器学习(Machine Learning)算法总结-K临近算法
一.算法详解 1.什么是K临近算法 Cover 和 Hart在1968年提出了最初的临近算法 属于分类(classification)算法 邻近算法,或者说K最近邻(kNN,k-NearestNeig ...
- 【学习笔记】分类算法-k近邻算法
k-近邻算法采用测量不同特征值之间的距离来进行分类. 优点:精度高.对异常值不敏感.无数据输入假定 缺点:计算复杂度高.空间复杂度高 使用数据范围:数值型和标称型 用例子来理解k-近邻算法 电影可以按 ...
- 机器学习实战 - python3 学习笔记(一) - k近邻算法
一. 使用k近邻算法改进约会网站的配对效果 k-近邻算法的一般流程: 收集数据:可以使用爬虫进行数据的收集,也可以使用第三方提供的免费或收费的数据.一般来讲,数据放在txt文本文件中,按照一定的格式进 ...
随机推荐
- React Hook 学习
1.官方文档 https://react.docschina.org/docs/hooks-intro.html 2.阮一峰 reactHook http://www.ruanyifeng.com/b ...
- kube-metric在kubernetes上的部署
1.拿包 wgethttps://github.com/kubernetes/kube-state-metrics/archive/v1.7.2.tar.gz 2.tar -zxf v1.7.2.t ...
- 如何禁止谷歌浏览器隐藏url的www前缀
若要将Chrome浏览器的设置恢复为隐藏HTTP.HTTPS以及WWW前缀,则只需再次进入此页面: chrome://flags/#omnibox-ui-hide-steady-state-url-s ...
- 基于模板匹配的目标跟踪(OpenCV)
基于VS2010+ OpenCV2.代码可以读入视频,也可以读摄像头,两者的选择只需要在代码中稍微修改即可.对于视频来说,运行会先显示第一帧,然后我们用鼠标框选要跟踪的目标,然后跟踪器开始跟踪每一帧. ...
- ZooKeeper的安装及部署
Zookeeper的安装部署 2.1 Zookeeper的安装 Zookeeper安装前需要安装好 JDK.配置好环境变量. 下载:zookeeper-3.4.5-cdh5.7.0.tar.gz 解压 ...
- 【LOJ】#3109. 「TJOI2019」甲苯先生的线段树
LOJ#3109. 「TJOI2019」甲苯先生的线段树 发现如果枚举路径两边的长度的话,如果根节点的值是$x$,左边走了$l$,右边走了$r$ 肯定答案会是$(2^{l + 1} + 2^{r + ...
- dash shell 的一些总结
最近写个一些dash shell 相关的代码,中间遇到了一些坑以及需要注意的地方,记录一下 1 参数 numberofargmuments(){ echo "The number of ar ...
- 线性基求交(2019牛客国庆集训派对day4)
题意:https://ac.nowcoder.com/acm/contest/1109/C 问你有几个x满足A,B集合都能XOR出x. 思路: 就是线性基求交后,有几个基就是2^几次方. #defin ...
- 使用Enablebuffering多次读取Asp Net Core 请求体
使用Enablebuffering多次读取Asp Net Core 请求体 1 .Net Core 2.X时代 使用EnableRewind倒带 public IActionResult Index( ...
- c# TCP/IP协议利用Socket Client通信(只含客户端Demo)
完全是基础,新手可以随意看看,大牛可以关闭浏览页了,哈哈. TCP/IP协议 TCP/IP是一系列网络通信协议的统称,其中最核心的两个协议是TCP和IP.TCP称为传输控制协议,IP称为互联网络协议. ...