爬虫之Resquests模块的使用(二)
Requests
Requests模块
Requests模块是一个用于网络访问的模块,其实类似的模块有很多,比如urllib,urllib2,httplib,httplib2,他们基本都提供相似的功能。
在上一篇我们已经使用urllib模块
而Requests会比urllib更加方便,可以节约我们大量的工作,它更加强大,所以更建议使用Requests。
各种请求方式
requests里提供各种请求方式
HTTP定义了与服务器进行交互的不同方式, 其中, 最基本的方法有四种: GET, POST, PUT, DELETE; 一个URL对应着一个网络上的资源, 这四种方法就对应着对这个资源的查询, 修改, 增加, 删除四个操作.上面的程序用到的requests.get()来读取指定网页的信息, 而不会对信息就行修改, 相当于是"只读". requests库提供了HTTP所有基本的请求方式, 都是一句话搞定。
requests请求方法
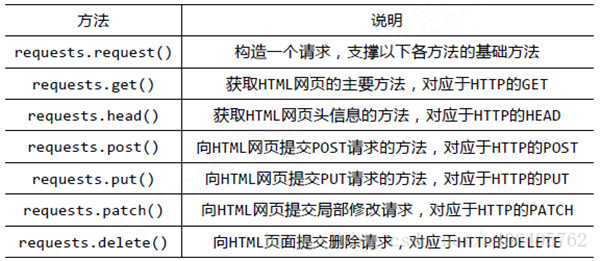
请求示例
r = requests.get(‘https://github.com/timeline.json’) # GET请求
r = requests.post(“http://httpbin.org/post”) # POST请求
r = requests.put(“http://httpbin.org/put”) # PUT请求
r = requests.delete(“http://httpbin.org/delete”) # DELETE请求
r = requests.head(“http://httpbin.org/get”) # HEAD请求
r = requests.options(“http://httpbin.org/get” ) # OPTIONS请求
以上方法均是在此方法的基础上构建
requests.request(method, url, **kwargs)
返回值属性
import requests
respone=requests.get('http://www.jianshu.com')
# respone属性
print(respone.text)# 所请求网页的内容
print(respone.content)
print(respone.status_code) #返回状态码
print(respone.headers)# 网页的头
print(respone.cookies)# 网页的cookie内容
print(respone.cookies.get_dict())
print(respone.cookies.items())
print(respone.url) # 实际的网址
print(respone.history)
print(respone.encoding) # 所请求网页的编码方式
GET请求:requests.get(url)
import requests
response = requests.get('http://httpbin.org/get') # 返回一个实例,包含了很多的信息
print(response.text) # 所请求网页的内容
带参数的GET请求:requests.get(url, param=None)
通常我们会通过httpbin.org/get?key=val方式传递。Requests模块允许使用params关键字传递参数,以一个字典来传递这些参数。
比如我们想传递key1=value1,key2=value2到http://httpbin.org/get里面
构造的url:http://httpbin.org/get?key1=value1&key2=value2
import requests
data = {
"key1":"key1",
"key2":"key2"
}
response = requests.get("http://httpbin.org/get",params=data)
print(response.url)
运行结果如下
C:\Pycham\venv\Scripts\python.exe C:/Pycham/demoe3.py
http://httpbin.org/get?key1=key1&key2=key2 Process finished with exit code 0
可以看到,参数之间用&隔开,参数名和参数值之间用=隔开。
上述两种的结果是相同的,通过params参数传递一个字典内容,从而直接构造url。
注意:通过传参字典的方式的时候,如果字典中的参数为None则不会添加到url上。
POST请求:requests.post(url, data=data)
requests.post()用法与requests.get()完全一致,特殊的是requests.post()有一个data参数,用来存放请求体数据
注意:同样的在发送post请求的时候也可以和发送get请求一样通过headers参数传递一个字典类型的数据
import requests
data = {
"name":"zhaofan",
"age":23
}
response = requests.post("http://httpbin.org/post",data=data)
print(response.text)
运行结果如下:
可以看到参数传成功了,然后服务器返回了我们传的数据。
C:\Pycham\venv\Scripts\python.exe C:/Pycham/demoe3.py
{
"args": {},
"data": "",
"files": {},
"form": {
"age": "23",
"name": "zhaofan"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Connection": "close",
"Content-Length": "19",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.19.1"
},
"json": null,
"origin": "218.200.145.68",
"url": "http://httpbin.org/post"
}
定制请求头和cookie信息
import requests
import json data = {'some': 'data'}
cookie = {'key':'value'}
headers = {'content-type': 'application/json',
'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:22.0) Gecko/20100101 Firefox/22.0'}
r = requests.post('https://api.github.com/some/endpoint', data=data, headers=headers,cookies =cookie)
print(r.text)
设置请求超时与代理
import requests
import json
data = {'some': 'data'}
proxies = {'http':'ip1','https':'ip2' } r = requests.post('https://api.github.com/some/endpoint', data=data,proxies=proxies,timeout = 1)
print(r.text)
传送json格式数据
有时候我们需要传送的信息不是表单形式的,需要我们传JSON格式的数据过去,所以我们可以用 json.dumps() 方法把表单数据序列化
import json
import requests url = 'http://httpbin.org/post'
data = {'some': 'data'}
r = requests.post(url, data=json.dumps(data))
print r.text
运行结果如下:
C:\Pycham\venv\Scripts\python.exe C:/Pycham/demoe3.py
{
"args": {},
"data": "{\"some\": \"data\"}",
"files": {},
"form": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Connection": "close",
"Content-Length": "16",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.19.1"
},
"json": {
"some": "data"
},
"origin": "218.200.145.68",
"url": "http://httpbin.org/post"
}
上传文件
如果想要上传文件,那么直接用 file 参数即可
import requests url = 'http://httpbin.org/post'
files = {'file': open('test.txt', 'rb')}
r = requests.post(url, files=files)
print r.text
运行结果如下
{
"args": {},
"data": "",
"files": {
"file": "Hello World!"
},
"form": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "156",
"Content-Type": "multipart/form-data; boundary=7d8eb5ff99a04c11bb3e862ce78d7000",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.9.1"
},
"json": null,
"url": "http://httpbin.org/post"
}
解析json
import requests
import json
response=requests.get('http://httpbin.org/get')
res1=json.loads(response.text) #太麻烦
res2=response.json() #直接获取json数据
print(res1 == res2) #True
那r.text和r.content的区别是什么呢?
r.text是unicode编码的响应内容(r.text is the content of the response in unicode)
r.content是字符编码的响应内容(r.content is the content of the response in bytes)
text属性会尝试按照encoding属性自动将响应的内容进行转码后返回,如果encoding为None,requests会按照chardet(这是什么?)猜测正确的编码
如果你想取文本,可以通过r.text, 如果想取图片,文件,则可以通过r.content
针对响应内容是二进制文件(如图片)的场景,content属性获取响应的原始内容(以字节为单位)
爬虫之Resquests模块的使用(二)的更多相关文章
- 第三百二十六节,web爬虫,scrapy模块,解决重复ur——自动递归url
第三百二十六节,web爬虫,scrapy模块,解决重复url——自动递归url 一般抓取过的url不重复抓取,那么就需要记录url,判断当前URL如果在记录里说明已经抓取过了,如果不存在说明没抓取过 ...
- 第三百二十五节,web爬虫,scrapy模块标签选择器下载图片,以及正则匹配标签
第三百二十五节,web爬虫,scrapy模块标签选择器下载图片,以及正则匹配标签 标签选择器对象 HtmlXPathSelector()创建标签选择器对象,参数接收response回调的html对象需 ...
- 第三百二十四节,web爬虫,scrapy模块介绍与使用
第三百二十四节,web爬虫,scrapy模块介绍与使用 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了 ...
- 第三百二十三节,web爬虫,scrapy模块以及相关依赖模块安装
第三百二十三节,web爬虫,scrapy模块以及相关依赖模块安装 当前环境python3.5 ,windows10系统 Linux系统安装 在线安装,会自动安装scrapy模块以及相关依赖模块 pip ...
- asynicio模块以及爬虫应用asynicio模块(高性能爬虫)
一.背景知识 爬虫的本质就是一个socket客户端与服务端的通信过程,如果我们有多个url待爬取,只用一个线程且采用串行的方式执行,那只能等待爬取一个结束后才能继续下一个,效率会非常低. 需要强调的是 ...
- 孤荷凌寒自学python第六十七天初步了解Python爬虫初识requests模块
孤荷凌寒自学python第六十七天初步了解Python爬虫初识requests模块 (完整学习过程屏幕记录视频地址在文末) 从今天起开始正式学习Python的爬虫. 今天已经初步了解了两个主要的模块: ...
- 八、asynicio模块以及爬虫应用asynicio模块(高性能爬虫)
asynicio模块以及爬虫应用asynicio模块(高性能爬虫) 一.背景知识 爬虫的本质就是一个socket客户端与服务端的通信过程,如果我们有多个url待爬取,只用一个线程且采用串行的方式执行, ...
- Python爬虫练习(requests模块)
Python爬虫练习(requests模块) 关注公众号"轻松学编程"了解更多. 一.使用正则表达式解析页面和提取数据 1.爬取动态数据(js格式) 爬取http://fund.e ...
- python爬虫主要就是五个模块:爬虫启动入口模块,URL管理器存放已经爬虫的URL和待爬虫URL列表,html下载器,html解析器,html输出器 同时可以掌握到urllib2的使用、bs4(BeautifulSoup)页面解析器、re正则表达式、urlparse、python基础知识回顾(set集合操作)等相关内容。
本次python爬虫百步百科,里面详细分析了爬虫的步骤,对每一步代码都有详细的注释说明,可通过本案例掌握python爬虫的特点: 1.爬虫调度入口(crawler_main.py) # coding: ...
随机推荐
- Mybatis入门学习笔记
1.定义别名 在sqlMapConfig.xml中,编写如下代码: <!-- 定义别名 --> <typeAliases> <!-- type: 需要映射的类型 alia ...
- Java中eclipse与命令行向main函数传递参数
我们知道main函数是java程序的入口,main函数的参数类型是String[]. 1.Eclipse中向main方法传递参数 例如: public class Mytest { public st ...
- pycharm2018破解
1.下载 链接:https://pan.baidu.com/s/1G0C9xoUQg6JRgNQYLMIi1w 密码:2z3x 2.修改 "G:\Python\JetBrains\PyCha ...
- Gaussian discriminant analysis 高斯判别分析
高斯判别分析(附Matlab实现) 生成学习算法 高斯判别分析(Gaussian Discriminant analysis,GDA),与之前的线性回归和Logistic回归从方法上讲有很大的不同,G ...
- Windows和Mac上NodeJS和Express的安装
一.安装NodeJS,官网上下载,https://nodejs.org/en/ 直接下一步安装就行了. 打开命令行工具,输入 node -v 则会出现node的版本,则成功了. 下面我们介绍如何安装e ...
- STM32F103X datasheet学习笔记---USART
1.前言 通用同步异步收发器(USART)提供了一种灵活的方法与使用工业标准NRZ异步串行数据格式的外部设备之间进行全双工数据交换. USART利用分数波特率发生器提供宽范围的波特率选择. 它支持同步 ...
- 017_nginx重定向需求
重定向的各种需求 需求一. 前端同事需要把特定的url进行重定向,实现如下: location / { root /data/base.apiportal_opsweb; index index.ht ...
- 生产环境elasticsearch5.0.1和6.3.2集群的部署配置详解
线上环境elasticsearch5.0.1集群的配置部署 es集群的规划: 硬件: 7台8核.64G内存.2T ssd硬盘加1台8核16G的阿里云服务器 其中一台作为kibana+kafka连接查询 ...
- 利用mycat实现基于mysql5.5主从复制的读写分离
整体步骤: 1.准备好两台服务器,一台作为主数据库服务器,一台作为从服务器,并安装好mysql数据库,此处略 2.配置好主从同步 3.下载JDK配置mycat依赖的JAVA环境,mycat采用java ...
- LinkedList源码分析笔记(jdk1.8)
1.特点 LinkedList的底层实现是由一个双向链表实现的,可以从两端作为头节点遍历链表. 允许元素为null 线程不安全 增删相对ArrayList快,改查相对ArrayList慢(curd都会 ...