C# 使用AngleSharp 爬虫图片
AngleSharp 简介
AngleSharp是基于.NET(C#)开发的专门解析HTML源码的DLL组件。根据HTML的DOM结构操作HTML,整个DOM已传输到逻辑类结构中。这种结构可以更好的操作DOM元素。
AngleSharp还带来了一些非常有用的扩展方法,它们跟jQuery和JavaScript中的用法类似。 使用命名空间AngleSharp可以访问Html,Css,Attr或Text等方法。 这些方法向给定的IHtmlCollection一样在给定的IEnumerable <IElement>上运行。 目的很简单:轻松修改给定的DOM元素。此插件最大的优势:支持输出Javascript、Linq语法、ID和Class选择器、动态添加节点。
AngleSharp是个开源项目, 主页地址。
参考
http://www.cnblogs.com/pandait/p/AngleSharp.html
https://www.cnblogs.com/liguobao/p/6130121.html
通过NuGet获取AngleSharp
将AngleSharp整合到您的项目中最简单的方法是使用NuGet。您可以通过打开软件包管理器控制台(PM)并输入以下语句来安装AngleSharp:
Install-Package AngleSharp
您也可以使用图形库包管理器(“管理解决方案的NuGet包”)。在官方的NuGet在线源中搜索“AngleSharp”将会找到这个库。
操作DOM示例
//创建一个(可重用)解析器前端
var parser = new HtmlParser();
//html DOM节点
var source = "<h1>Some example source</h1><p>This is a paragraph element";
//解析源文件
var document = parser.Parse(source);
//创建P标签
var p = document.CreateElement("p");
p.TextContent = "This is another paragraph.";
//添加到DOM
document.Body.AppendChild(p);
//返回完整html
var html = document.DocumentElement.OuterHtml;
ViewData["html"] = html;
效果展示
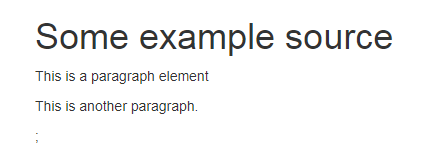
更改标签属性
给<li> 标签添加自定义属性
var parser = new HtmlParser();
//为以下源代码生成HTML DOM
var document = parser.Parse("<ul><li>First element<li>Second element<li>third<li class=bla>Last");
//获取所有li元素并将test属性设置为值测试
var elements = document.QuerySelectorAll("li").Attr("test", "test");
//元素仍然包含所有li元素
ViewData["html"] = document.DocumentElement.OuterHtml;
效果展示

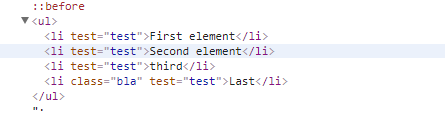
爬取豆瓣美女图片
新建个Belle类用于保存获取的图片信息
/// <summary>
/// 解析html
/// </summary>
public class Belle
{
/// <summary>
/// 标题
/// </summary>
public string Title { get; set; }
/// <summary>
/// 图片地址
/// </summary>
public string ImageUrl { get; set; }
}
获取html并解析
// 设置配置以支持文档加载
var config = Configuration.Default.WithDefaultLoader();
// 豆瓣地址
var address = "https://www.dbmeinv.com/dbgroup/show.htm?cid=4";
// 请求豆辨网
var document = BrowsingContext.New(config).OpenAsync(address);
// 根据class获取html元素
var cells = document.Result.QuerySelectorAll(".panel-body li");
// We are only interested in the text - select it with LINQ
List<Belle> list = new List<Belle>();
foreach (var item in cells)
{
var belle = new Belle
{
Title= item.QuerySelector("img").GetAttribute("title"),
ImageUrl= item.QuerySelector("img").GetAttribute("src")
};
list.Add(belle);
}
ViewData["html"] = list;
效果如下
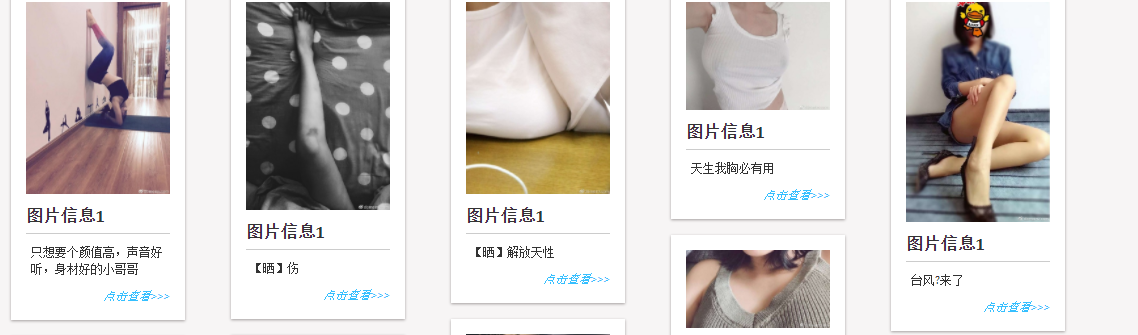
C# 使用AngleSharp 爬虫图片的更多相关文章
- Selenium&EmguCV实现爬虫图片识别
概述 爬虫需要抓取网站价格,与一般抓取网页区别的是抓取内容是通过AJAX加载,并且价格是通过CSS背景图片显示的. 每一个数字对应一个样式,如'p_h57_5' .p_h57_5 { backgrou ...
- Day04_网络爬虫图片收获
#所需模块 requests .Beautifulsoup.urllib 1. response = requests.get('www.baidu.com') #获取网站响应 2.html = r ...
- python爬虫-图片批量下载
# 爬起摄图网的图片批量下载# coding:utf-8 import requests from bs4 import BeautifulSoup from scipy.misc import im ...
- Python 爬虫-图片的爬取
2017-07-25 22:49:21 import requests import os url = 'https://wallpapers.wallhaven.cc/wallpapers/full ...
- scrapy实战3利用fiddler对手机app进行抓包爬虫图片下载(重写ImagesPipeline):
关于fiddler的使用方法参考(http://jingyan.baidu.com/article/03b2f78c7b6bb05ea237aed2.html) 本案例爬取斗鱼 app 先利用fidd ...
- python爬虫--图片懒加载
图片懒加载 是一种反爬机制,图片懒加载是一种网页优化技术.图片作为一种网络资源,在被请求时也与普通静态资源一样,将占用网络资源,而一次性将整个页面的所有图片加载完,将大大增加页面的首屏加载时间.为了解 ...
- python3爬虫图片验证码识别
# 图片验证码识别 环境安装# sudo apt-get install -y tesseract-ocr libtesseract-dev libleptonica-dev# pip install ...
- [python爬虫] Selenium定向爬取虎扑篮球海量精美图片
前言: 作为一名从小就看篮球的球迷,会经常逛虎扑篮球及湿乎乎等论坛,在论坛里面会存在很多精美图片,包括NBA球队.CBA明星.花边新闻.球鞋美女等等,如果一张张右键另存为的话真是手都点疼了.作为程序员 ...
- 下载百度上的图片C#——输入名字就可以下载
using System; using System.Collections.Generic; using System.Data; using System.Configuration; using ...
随机推荐
- 开源三维地球GIS引擎Cesium常用功能的开发
Cesium是一个非常优秀的三维地球GIS引擎(开源且免费).能够加载各种符合标准的地图图层,瓦片图.矢量图等都支持.支持3DMax等建模软件生成的obj文件,支持通用的GIS计算:支持DEM高程图. ...
- docker 安装 msyql
**************************************************************************************************** ...
- vue 的准备项目架构环境配置
一.环境搭建 中国镜像 composer config repo.packagist composer https://packagist.phpcomposer.com 命令 composer in ...
- Spring MVC 数据校验@Valid
先看看几个关键词 @Valid @Pattern @NotNull @NotBlank @Size BindingResult 这些就是Spring MVC的数据校验的几个注解. 那怎么用呢?往下看 ...
- linux_nginx反向代理
什么代理? 代理他人工作 什么是正向代理和反向向代理,他们之间的区别? 这两个代理很类似,但扮演了两个不同角色,一个站在用户角度,一个站在服务端角度 正向代理: 帮助用户请求服务 返向代理:帮助服务均 ...
- Log4j源码解析--LoggerRepository和Configurator解析
本文转自上善若水的博客,原文出处:http://www.blogjava.net/DLevin/archive/2012/07/10/382678.html.感谢作者的无私分享. LoggerRepo ...
- java1.8--1.8入门介绍
在我之前的工作中,一直使用的是java6.所以即使现在java已经到了1.8,对于1.7增加的新特性我也基本没使用的.在整理一系列1.8的新特性的过程中,我也会添加上1.7增加的特性. 下面的整理可能 ...
- 浅谈Java Virtual Machine
Java Virtual Machine 就是指Java虚拟器,以下简称VM.关于VM的概念,最早出自CPU模拟器,众所周知的PC上的游戏机模拟器采用的便是和Java VM类似的技术.ja ...
- SSMS 2005 连接 SQL SERVER 2008问题
用本机的 Microsoft SQL Server Management Studio 2005 客户端连接数据库服务器时报错:"This version of Microsoft SQL ...
- android activity传递实体类对象
通过实现Parcelable接口序列化对象的步骤: 1.实现Parcelable接口.2.并且实现Parcelable接口的public void writeToParcel(Parcel dest, ...