数据算法 --hadoop/spark数据处理技巧 --(7.共同好友 8. 使用MR实现推荐引擎)
七,共同好友。
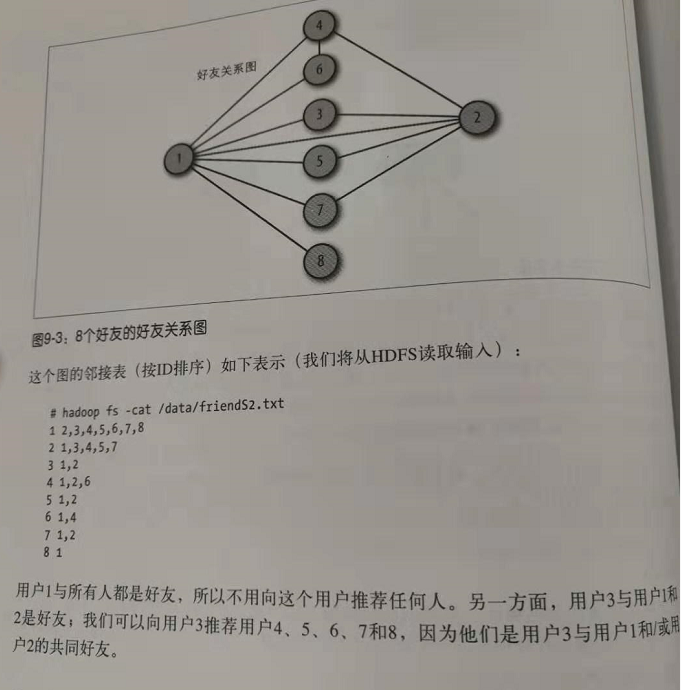
在所有用户对中找出“共同好友”。
eg:
a b,c,d,g
b a,c,d,e
map()-》 <a,b>,<b,c,d,g> ;<a,c>,<b,c,d,g>;.....
<a,b>,<a,c,d,e>
reduce()-> <a,b>,<c,d> 也就是a,b的共同好友是c,d。
上述就是思想。
八,使用MR实现推荐引擎
1.购买过该商品的顾客还购买了哪些商品。
这里,利用MR的两次迭代实现CWBTIAB功能。
阶段1:生成同一个用户购买的所有商品列表。分组由HAdoop框架处理,其中映射器和规约器都会完成一个恒等函数。
阶段2:解决列表商品的共现问题。使用Stripes(条纹)设计模式,只发出5个最常见的商品。


2.经常一起购买的商品(FBT)

3.推荐连接
解决方案(实现思路):


数据算法 --hadoop/spark数据处理技巧 --(7.共同好友 8. 使用MR实现推荐引擎)的更多相关文章
- 数据算法 --hadoop/spark数据处理技巧 --(5.移动平均 6. 数据挖掘之购物篮分析MBA)
五.移动平均 多个连续周期的时间序列数据平均值(按相同时间间隔得到的观察值,如每小时一次或每天一次)称为移动平均.之所以称之为移动,是因为随着新的时间序列数据的到来,要不断重新计算这个平均值,由于会删 ...
- 数据算法 --hadoop/spark数据处理技巧 --(1.二次排序问题 2. TopN问题)
一.二次排序问题. MR/hadoop两种方案: 1.让reducer读取和缓存给个定键的所有值(例如,缓存到一个数组数据结构中,)然后对这些值完成一个reducer中排序.这种方法不具有可伸缩性,因 ...
- 数据算法 --hadoop/spark数据处理技巧 --(9.基于内容的电影推荐 10. 使用马尔科夫模型的智能邮件营销)
九.基于内容的电影推荐 在基于内容的推荐系统中,我们得到的关于内容的信息越多,算法就会越复杂(设计的变量更多),不过推荐也会更准确,更合理. 本次基于评分,提供一个3阶段的MR解决方案来实现电影推荐. ...
- 数据算法 --hadoop/spark数据处理技巧 --(3.左外连接 4.反转排序)
三. 左外连接 考虑一家公司,比如亚马逊,它拥有超过2亿的用户,每天要完成数亿次交易.假设我们有两类数据,用户和交易: users(user_id,location_id) transactions( ...
- 数据算法 --hadoop/spark数据处理技巧 --(17.小文件问题 18.MapReuce的大容量缓存)
十七.小文件问题 十八.MR的大容量缓存 在MR中使用和读取大容量缓存,(也就是说,可能包括数十亿键值对,而无法放在一个商用服务器的内存中).本次提出的算法通用,可以在任何MR范式中使用.(eg:MR ...
- 数据算法 --hadoop/spark数据处理技巧 --(11.K-均值聚类 12. k-近邻)
十一.k-均值聚类 这个需要MR迭代多次. 开始时,会选择K个点作为簇中心,这些点成为簇质心.可以选择很多方法啦初始化质心,其中一种方法是从n个点的样本中随机选择K个点.一旦选择了K个初始的簇质心,下 ...
- 数据算法 --hadoop/spark数据处理技巧 --(13.朴素贝叶斯 14.情感分析)
十三.朴素贝叶斯 朴素贝叶斯是一个线性分类器.处理数值数据时,最好使用聚类技术(eg:K均值)和k-近邻方法,不过对于名字.符号.电子邮件和文本的分类,则最好使用概率方法,朴素贝叶斯就可以.在某些情况 ...
- 数据算法 --hadoop/spark数据处理技巧 --(15.查找、统计和列出大图中的所有三角形 16.k-mer计数)
十五.查找.统计和列出大图中的所有三角形 第一步骤的mr: 第二部mr: 找出三角形 第三部:去重 spark: 十六: k-mer计数 spark:
- 哈,我自己翻译的小书,马上就完成了,是讲用python处理大数据框架hadoop,spark的
花了一些时间, 但感觉很值得. Big Data, MapReduce, Hadoop, and Spark with Python Master Big Data Analytics and Dat ...
随机推荐
- 图解kubernetes调度器ScheduleAlgorithm核心实现学习框架设计
ScheduleAlgorithm是一个接口负责为pod选择一个合适的node节点,本节主要解析如何实现一个可扩展.可配置的通用算法框架来实现通用调度,如何进行算法的统一注册和构建,如何进行metad ...
- Linux上的Tomcat地址映射,且404错误解决
问题:现在想要加一个下载文件功能,但是文件地址不在tomcat的webapps下,需要通过地址映射到tomcat下面再通过链接执行下载文件功能. 解决方法有两种: 方法一: 用方法一的前提是不用启动服 ...
- 重拾c++第一天(3):数据处理
1.short至少16位:int至少与short一样长:long至少32位,且至少与int一样长:long long至少64位,且至少与long一样长 2.sizeof 变量 返回变量长度 或者s ...
- cogs 2109. [NOIP 2015] 运输计划 提高组Day2T3 树链剖分求LCA 二分答案 差分
2109. [NOIP 2015] 运输计划 ★★★☆ 输入文件:transport.in 输出文件:transport.out 简单对比时间限制:3 s 内存限制:256 MB [题 ...
- typescript学习笔记(一)---基础变量类型
作为一个前端开发者,学习新技术跟紧大趋势是必不可少的.随着2019年TS的大火,我打算利用一个月的时间学习这门语言.接下来的几篇文章是我学习TS的学习笔记,其中也会掺杂一些学习心得.话不多说,先从基础 ...
- http请求头中的content-type属性
在HTTP请求中,我们每天都在使用Content-Type来指定不同格式的请求信息,但是却很少有人去全面了解Content-Type中允许的值有多少,因此这里来了解一下Content-Type的可用值 ...
- ValueError: The field admin.LogEntry.user was declared with a lazy reference to 'system.sysuser', bu
问题:已经在settings.py文件中注册过app仍旧提示没有安装,并且使用makegirations命令时会抛出如下异常. ValueError: The field admin.LogEntry ...
- (.text+0x18): undefined reference to `main'
在将VS中的程序移植到ubuntu中出现的一个问题,主要原因是在vs中默认的主函数写成int _tmain(), 而在gcc编译时要找的是int main().改过来就可以了.
- Arduino通信篇系列之print()和write()输出方式的差异
我们都知道,在HardwareSerial类中有print()和write()两种输出方式, 两个都可以输出数据,但其输出方式并不相同. 例子: float FLOAT=1.23456; int IN ...
- JS刷算法题:二叉树
Q1.翻转二叉树(easy) 如题所示 示例: 输入: 4 / \ 2 7 / \ / \ 1 3 6 9 输出: 4 / \ 7 2 / \ / \ 9 6 3 1 来源:力扣(LeetCode) ...