spark安装
 Spark下载
Spark下载
在spark主页的download下,选择自己想要安装的spark版本, 注意跟本地hadoop的兼容性。我这里选择了2.4.0.
https://www.apache.org/dyn/closer.lua/spark/spark-2.4.0/spark-2.4.0-bin-hadoop2.7.tgz
解压与配置环境变量
在master机器上的/opt/spark/下解压安装包
[root@master spark]# tar zxvf spark-2.4.-bin-hadoop2..tgz
在集群各台机器上添加环境变量
vi /etc/profile
export SPARK_HOME=/opt/spark/spark-2.4.-bin-hadoop2./
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SPARK_HOME/bin:
[root@master spark]# source /etc/profile
配置spark环境
进入spark配置文件路径
[root@master conf]# cd /opt/spark/spark-2.4.0-bin-hadoop2.7/conf
此处需要配置的文件为两个 spark-env.sh和slaves
首先拷贝模板文件
[root@master conf]# cp spark-env.sh.template spark-env.sh
[root@master conf]# cp slaves.template slaves
修改spark-env.sh文件
[root@master conf]# vi spark-env.sh
export JAVA_HOME=/opt/java/jdk1..0_191 export HADOOP_HOME=/opt/hadoop/hadoop-2.9./ export HADOOP_CONF_DIR=/opt/hadoop/hadoop-2.9./etc/hadoop export SPARK_MASTER_IP=192.168.102.3 export SPARK_WORKER_MEMORY=500m export SPARK_WORKER_CORES= export SPARK_WORKER_INSTANCES=
变量说明
- JAVA_HOME:Java安装目录
- HADOOP_HOME:hadoop安装目录
- HADOOP_CONF_DIR:hadoop集群的配置文件的目录
- SPARK_MASTER_IP:spark集群的Master节点的ip地址
- SPARK_WORKER_MEMORY:每个worker节点能够最大分配给exectors的内存大小
- SPARK_WORKER_CORES:每个worker节点所占有的CPU核数目
- SPARK_WORKER_INSTANCES:每台机器上开启的worker节点的数目
这边个人配置都有一定区别,选自己需要的配置就可以了。
修改slaves文件
[root@master conf]# vi slaves
slave1
slave2
将配置好的spark文件夹分发给所有slaves
首先在slave1 和slave2上创建spark文件夹
mkdir /opt/spark/
分发spark
[root@master conf]# scp -r /opt/spark/spark-2.4.-bin-hadoop2. slave1:/opt/spark/
[root@master conf]# scp -r /opt/spark/spark-2.4.-bin-hadoop2. slave2:/opt/spark/
启动Spark集群
因为我们只需要使用hadoop的HDFS文件系统,所以我们并不用把hadoop全部功能都启动。
启动hadoop的HDFS文件系统
[root@master sbin]# start-dfs.sh
启动Spark
因为hadoop/sbin以及spark/sbin均配置到了系统的环境中,它们同一个文件夹下存在同样的start-all.sh文件。所以我把spark的start-all.sh改了一个名字,方便以后使用。
[root@master sbin]# mv start-all.sh start-all-spark.sh
[root@master sbin]# start-all-spark.sh
成功打开之后使用jps在master、slave1和slave2节点上分别可以看到新开启的Master和Worker进程。
[root@master sbin]# jps
Jps
Master
NodeManager
NameNode
JobHistoryServer
[root@slave1 spark]# jps
Worker
NodeManager
DataNode
Jps
ResourceManager
[root@slave2 java]# jps
NodeManager
Jps
SecondaryNameNode
Worker
DataNode
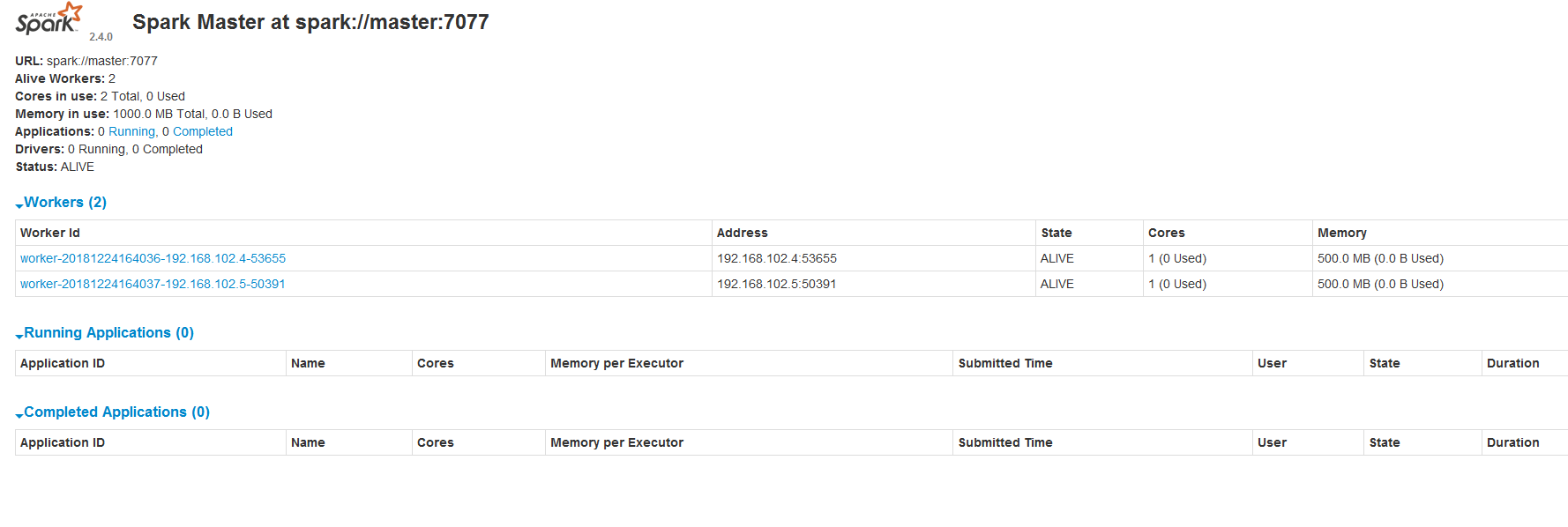
成功打开Spark集群之后可以进入Spark的WebUI界面,可以通过下面地址访问
http://192.168.102.3:8080/
spark安装的更多相关文章
- Hive on Spark安装配置详解(都是坑啊)
个人主页:http://www.linbingdong.com 简书地址:http://www.jianshu.com/p/a7f75b868568 简介 本文主要记录如何安装配置Hive on Sp ...
- Spark学习(一) -- Spark安装及简介
标签(空格分隔): Spark 学习中的知识点:函数式编程.泛型编程.面向对象.并行编程. 任何工具的产生都会涉及这几个问题: 现实问题是什么? 理论模型的提出. 工程实现. 思考: 数据规模达到一台 ...
- Windows环境中Openfire与Spark安装与配置指南
安装软件: openfire3.9.3 spark2.6.3 安装环境: WindowsXP JDK1.6.0_21 Oracle 一.openfire安装 1.安装openfire3.9.3,下载地 ...
- (转)Spark安装与学习
摘要:Spark是继Hadoop之后的新一代大数据分布式处理框架,由UC Berkeley的Matei Zaharia主导开发.我只能说是神一样的人物造就的神器,详情请猛击http://www.spa ...
- spark安装mysql与hive
第一眼spark安装文件夹lib\spark-assembly-1.0.0-hadoop2.2.0.jar\org\apache\spark\sql下有没有hive文件夹,假设没有的话先下载支持hiv ...
- Spark环境搭建(下)——Spark安装
1. 下载Spark 1.1 官网下载Spark http://spark.apache.org/downloads.html 打开上述链接,进入到下图,点击红框下载Spark-2.2.0-bin-h ...
- hadoop2.7.3+spark2.1.0+scala2.12.1环境搭建(4)SPARK 安装
hadoop2.7.3+spark2.1.0+scala2.12.1环境搭建(4)SPARK 安装 一.依赖文件安装 1.1 JDK 参见博文:http://www.cnblogs.com/liugh ...
- Spark学习之Spark安装
Spark安装 spark运行环境 spark是Scala写的,运行在jvm上,运行环境为java7+ 如果使用Python的API ,需要使用Python2.6+或者Python3.4+ Spark ...
- Spark安装部署(local和standalone模式)
Spark运行的4中模式: Local Standalone Yarn Mesos 一.安装spark前期准备 1.安装java $ sudo tar -zxvf jdk-7u67-linux-x64 ...
- Spark安装过程纪录
1 Scala安装 1.1 master 机器 修改 scala 目录所属用户和用户组. sudo chown -R hadoop:hadoop scala 修改环境变量文件 .bashrc , 添加 ...
随机推荐
- C++面试笔记(3)
20. 浅拷贝与深拷贝 如何理解C++中的浅拷贝与深拷贝 深拷贝和浅拷贝 在进行对象拷贝时,当对象包含对其他资源的引用,如果需要拷贝这个独享所引用的对象,那就是深拷贝,否则就是浅拷贝 *** 21.构 ...
- Vue框架是什么,有什么特点,怎么用
一.Vue基本介绍 1.vue是渐进式的JavaScript框架 2.作者:尤雨溪(一位华裔前Google工程师) 3.作用:动态构建用户界面 二:Vue的特点 1.遵循MVVM模式(m->mo ...
- java第六周作业
1 JSF请求处理生命周期的高度概述 从历史上看,Web应用程序必需的大部分开发,主要是处理Web客户端的HTTP请求.随着Web从传统的静态文档传送模型(在这种模型中,只请求静态Web页面,没有参 ...
- Ricker wavelet 简介
本文依照参考文献简介 Ricker wavelet . 参考: [1] Frequency of the Ricker wavelet DOI: 10.1190/GEO2014-0441.1 [2] ...
- PostMan Test 的脚本scripts编写方法
设置环境变量 pm.environment.set("variable_key", "variable_value"); 将一个嵌套的对象设置为一个环境变量 v ...
- CSV空行问题
当写入CSV时生成的数据会有空行如果加入 newline =‘’ 不会新增空行 writefile = open('result.csv','w',newline =‘’) 原贴 https://bl ...
- 2019 Power BI最Top50面试题,助你面试脱颖而出系列<上>
距离4月还剩11天, 你是否还在投简历找工作而机会寥寥? 你是否还在四处奔波疲于面试而结果不意? ....... 知否知否, 天下武功唯快不破, 传说江湖有本Power BI 面试真香秘籍, 能助你快 ...
- sqlite当天时间的23:59:59
select strftime('%Y-%m-%d %H:%M:%S','now','+1 day','localtime','start of day','-1 seconds')
- Asp.net中时间格式化的几种方法
1. 数据控件绑定时格式化日期方法:<asp:BoundColumn DataField="AddTime" HeaderText="添加时间" Data ...
- Lock详解
在JDK1.5后,并发包里新增了Lock接口以及其实现类来实现锁功能,它提供了与synchronized关键字类似的锁功能,但它需要手动开启.关闭锁.虽然看起来没有synchronized方便,但它可 ...