java实现多线程使用多个代理ip的方式爬取网页页面内容
项目的目录结构
核心源码:
package cn.edu.zyt.spider; import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream;
import java.util.Properties; import cn.edu.zyt.spider.model.SpiderParams;
import cn.edu.zyt.spider.queue.UrlQueue;
import cn.edu.zyt.spider.worker.SpiderWorker; public class SpiderStarter { public static void main(String[] args){ System.setProperty("java.net.useSystemProxies", "true");
System.setProperty("http.proxyHost", "113.128.9.37");
System.setProperty("http.proxyPort", "9999");
System.setProperty("https.proxyHost", "113.128.9.37");
System.setProperty("https.proxyPort", "9999"); // 初始化配置参数
initializeParams(); // 初始化爬取队列
initializeQueue(); // 创建worker线程并启动
for(int i = 1; i <= SpiderParams.WORKER_NUM; i++){
new Thread(new SpiderWorker(i)).start();
}
} /**
* 初始化配置文件参数
*/
private static void initializeParams(){
InputStream in;
try {
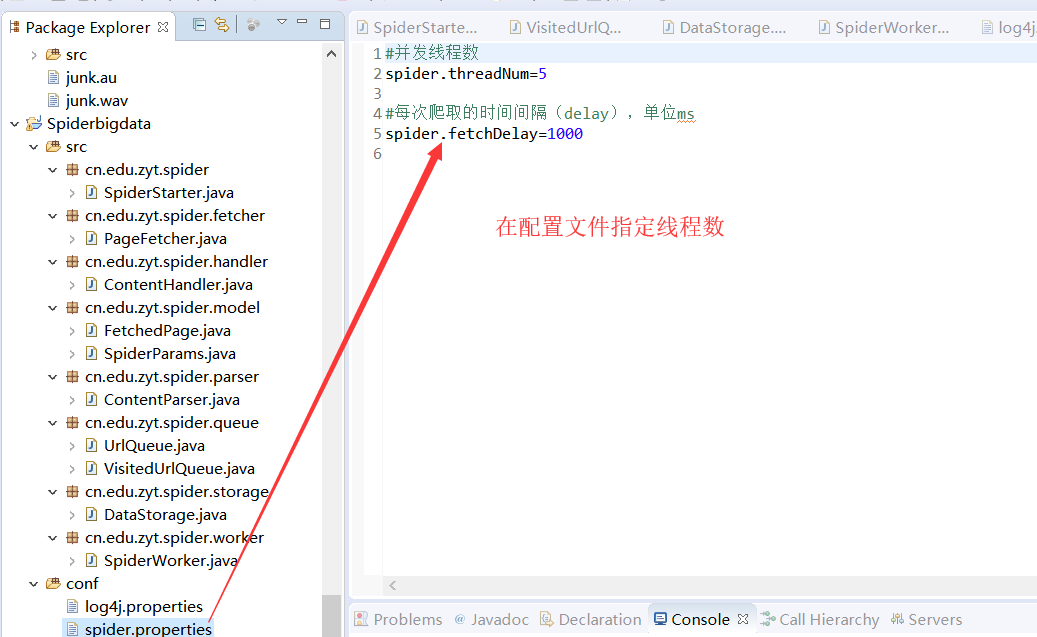
in = new BufferedInputStream(new FileInputStream("conf/spider.properties"));
Properties properties = new Properties();
properties.load(in); // 从配置文件中读取参数
SpiderParams.WORKER_NUM = Integer.parseInt(properties.getProperty("spider.threadNum"));
SpiderParams.DEYLAY_TIME = Integer.parseInt(properties.getProperty("spider.fetchDelay")); in.close();
}
catch (FileNotFoundException e) {
e.printStackTrace();
}
catch (IOException e) {
e.printStackTrace();
}
} /**
* 准备初始的爬取链接
*/
private static void initializeQueue(){
// 例如,需要抓取天下粮仓信息,根据链接规则生成URLs放入带抓取队列http://www.cofeed.com/national_1.html for(int i = 0; i < 3; i += 1){
UrlQueue.addElement("http://www.cofeed.com/national_" + i+".html");
}
}
}

实现效果图:

由于页面代码较多就不一一粘贴了,获取完整源码可在博客下方留言哈
java实现多线程使用多个代理ip的方式爬取网页页面内容的更多相关文章
- Java中使用多线程、curl及代理IP模拟post提交和get访问
Java中使用多线程.curl及代理IP模拟post提交和get访问 菜鸟,多线程好玩就写着玩,大神可以路过指教,小弟在这受教,谢谢! 更多分享请关注微信公众号:lvxing1788 ~~~~~~ 分 ...
- Java中使用多线程、curl及代理IP模拟post提交和get訪问
Java中使用多线程.curl及代理IP模拟post提交和get訪问 菜鸟,多线程好玩就写着玩.大神能够路过不吝赐教.小弟在这受教.谢谢! 很多其它分享请关注微信公众号:lvxing1788 ~~~~ ...
- 使用Selenium&PhantomJS的方式爬取代理
前面已经爬取了代理,今天我们使用Selenium&PhantomJS的方式爬取快代理 :快代理 - 高速http代理ip每天更新. 首先分析一下快代理,如下 使用谷歌浏览器,检查,发现每个代理 ...
- Java两种方式简单实现:爬取网页并且保存
注:如果代码中有冗余,错误或者不规范,欢迎指正. Java简单实现:爬取网页并且保存 对于网络,我一直处于好奇的态度.以前一直想着写个爬虫,但是一拖再拖,懒得实现,感觉这是一个很麻烦的事情,出现个小错 ...
- java爬虫-简单爬取网页图片
刚刚接触到“爬虫”这个词的时候是在大一,那时候什么都不明白,但知道了百度.谷歌他们的搜索引擎就是个爬虫. 现在大二.再次燃起对爬虫的热爱,查阅资料,知道常用java.python语言编程,这次我选择了 ...
- php 使用代理IP进行数据抓取
什么是代理?什么情况下会用到代理IP?代理服务器(Proxy Server),其功能就是代用户去取得网络信息,然后返回给用户.形象的说:它是网络信息的中转站.通过代理IP访问目标站,可以隐藏用户的真实 ...
- 如何使用代理IP进行数据抓取,PHP爬虫抓取亚马逊商品数据
什么是代理?什么情况下会用到代理IP? 代理服务器(Proxy Server),其功能就是代用户去取得网络信息,然后返回给用户.形象的说:它是网络信息的中转站.通过代理IP访问目标站,可以隐藏用户的真 ...
- 一个简单java爬虫爬取网页中邮箱并保存
此代码为一十分简单网络爬虫,仅供娱乐之用. java代码如下: package tool; import java.io.BufferedReader; import java.io.File; im ...
- python多线程与多进程--存活主机ping扫描以及爬取股票价格
python多线程与多进程 多线程: 案例:扫描给定网络中存活的主机(通过ping来测试,有响应则说明主机存活) 普通版本: #扫描给定网络中存活的主机(通过ping来测试,有响应则说明主机存活)im ...
随机推荐
- 使用scrapy爬虫,爬取17k小说网的案例-方法一
无意间看到17小说网里面有一些小说小故事,于是决定用爬虫爬取下来自己看着玩,下图这个页面就是要爬取的来源. a 这个页面一共有125个标题,每个标题里面对应一个内容,如下图所示 下面直接看最核心spi ...
- java程序员技术范围
1 工具 开发工具.源代码管理.构建工具.测试工具(压力.安全等).接口测试工具.反编译工具.日志工具.第三方工具等 2 java jvm.多线程.socket.io(两种方式).集合(两大接口).异 ...
- Javascrip动态添加样式,Dom操作,获取自定义属性
var layer=document.querySelector('.layer') 添加样式: 添加单个样式: layer.style.display="block" 添加多个样 ...
- Uncaught TypeError: Cannot read property ‘split’ of undefined
问题 :Uncaught TypeError: Cannot read property ‘split’ of undefinedat HTMLLIElement. split()切割的问题 因为遍历 ...
- https请求之绕过证书安全校验工具类(原)
package com.isoftstone.core.util; import java.io.BufferedReader; import java.io.ByteArrayOutputStrea ...
- 洛谷 P2678 & [NOIP2015提高组] 跳石头
题目链接 https://www.luogu.org/problemnew/show/P2678 题目背景 一年一度的“跳石头”比赛又要开始了! 题目描述 这项比赛将在一条笔直的河道中进行,河道中分布 ...
- iOS开发之GCD同步主线程、异步主线程
/** 在主线程执行block */ + (void)gs_synExecuteOnMainThread:(void (^)(void))block { if ((nil == block) || ( ...
- Topshelf的使用
一.简介 Topshelf可用于创建和管理Windows服务.其优势在于不需要创建windows服务,创建控制台程序就可以.便于调试. 二.官方地址: 1.官网:http://topshelf-pro ...
- Long Long Ago 二分查找
L: Long Long Ago 时间限制: 1 s 内存限制: 128 MB 提交 我的状态 题目描述 今天SHIELD捕获到一段从敌方基地发出的信息里面包含一串被经过某种算法加密过的的序 ...
- git 提示error setting certificate verify locations 解决方案
问题:使用git extension 拉取或者push代码,提示 "C:\Program Files\Git\bin\git.exe" pull --progress " ...