bs4爬取笔趣阁小说
参考链接:https://www.cnblogs.com/wt714/p/11963497.html
模块:requests,bs4,queue,sys,time
步骤:给出URL--> 访问URL --> 获取数据 --> 保存数据
第一步:给出URL
百度搜索笔趣阁,进入相关网页,找到自己想要看的小说,如“天下第九”,打开第一章,获得第一章的URL:https://www.52bqg.com/book_113099/37128558.html
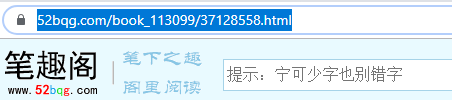
第二步:访问URL
def get_content(url):
try:
# 进入主页
# https://www.52bqg.com/
# 随便搜索一步小说,找出变化规律
# https://www.52bqg.com/book_110102/
headers = {
'User-Agent': ""
}
res = requests.get(url=url, headers=headers)
res.encoding = "gbk"
content = res.text
return content
except:
s = sys.exc_info()
print("Error '%s' happened on line %d" % (s[1], s[2].tb_lineno))
return "ERROR"
返回的是此页面的内容
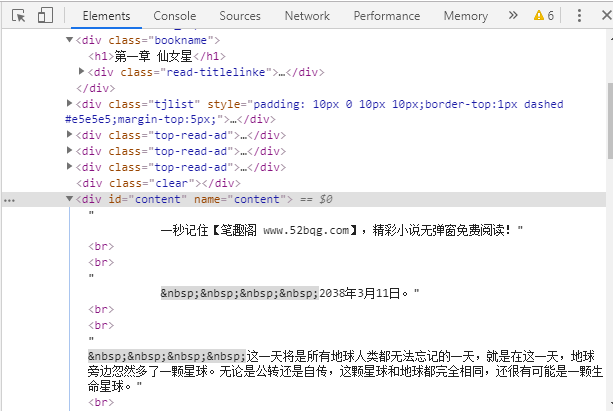
第三步:获取数据
def parseContent(first_url, content):
soup = BeautifulSoup(content, "html.parser")
chapter = soup.find(name='div', class_="bookname").h1.text
content = soup.find(name="div", id="content").text
chapter获取的就是每一章的名称,例如:第一章 仙女星
content获取的就是每一章的内容,例如:这一天将是所有地球。。。。
第四步:保存数据
def save(chapter, content):
filename = 文件名字
f = open(filename, "a+", encoding="utf-8")
f.write("".join(chapter) + "\n")
f.write("".join(content.split()[2:]) + "\n")
f.close()
以上就是爬取数据的一般步骤,介绍了一章是如何爬取下来的,那么一本小说,有很多很多章,全部爬取下来的话,就将上面的步骤一次又一次的进行就好了。
这里采取的方法是队列形式,首先给出第一章的url,存放到一个队列中,然后从队列中提取url进行访问,在访问过程中找到第二章的url,放入队列中,然后提取第二个url访问,依次类推,直到将小说所有章节爬取下来,队列为空为止。文件名字这一块,也是通过访问小说的url获取到小说名字,然后以小说名字命名txt的名字。
完整代码如下:
#!/usr/bin/env python
# _*_ coding: UTF-8 _*_
"""=================================================
@Project -> File : Operate_system_ModeView_structure -> get_book_exe.py
@IDE : PyCharm
@Author : zihan
@Date : 2020/4/25 10:28
@Desc :爬取笔趣阁小说: https://www.52bqg.com/
将url放入一个队列中Queue
访问第一章的url得到第二章的url,放入队列,依次类推
=================================================""" import requests
from bs4 import BeautifulSoup
import sys
import time
import queue # 获取内容
def get_content(url):
try:
# 进入主页
# https://www.52bqg.com/
# 随便搜索一步小说,找出变化规律
# https://www.52bqg.com/book_110102/
headers = {
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36"
}
res = requests.get(url=url, headers=headers) # 获取小说目录界面
res.encoding = "gbk"
content = res.text
return content
except:
s = sys.exc_info()
print("Error '%s' happened on line %d" % (s[1], s[2].tb_lineno))
return "ERROR" # 解析内容
def parseContent(q, first_url, content):
base_url_list = first_url.split("/")
html_order = base_url_list[-1]
last_number = first_url.find(html_order)
base_url = first_url[:last_number]
soup = BeautifulSoup(content, "html.parser")
chapter = soup.find(name='div', class_="bookname").h1.text
content = soup.find(name="div", id="content").text
save(base_url, chapter, content)
# 如果存在下一个章节的链接,则将链接加入队列
next1 = soup.find(name='div', class_="bottem").find_all('a')[3].get('href')
if next1 != base_url:
q.put(next1)
# print(next1)
return q def save(base_url, chapter, content):
book_name = get_book_name(base_url)
filename = book_name + ".txt"
f = open(filename, "a+", encoding="utf-8")
f.write("".join(chapter) + "\n")
f.write("".join(content.split()[2:]) + "\n")
f.close() # 获取书名
def get_book_name(base_url):
content = get_content(base_url)
soup = BeautifulSoup(content, "html.parser")
name = soup.find(name='div', class_="box_con").h1.text
return name def main():
first_url = input("请输入小说第一章的链接:")
start_time = time.time() # 进入主页
# https://www.52bqg.com/
# 随便搜索一步小说,找出变化规律
# https://www.52bqg.com/book_110102/
q = queue.Queue()
# 小说第一章链接
# first_url = "https://www.52bqg.com/book_110102/35620490.html"
q.put(first_url)
while not q.empty():
content = get_content(q.get())
q = parseContent(q, first_url, content)
end_time = time.time()
project_time = end_time - start_time
print("下载用时:", project_time) if __name__ == '__main__':
main()
欢迎大家分享一些新发现。
bs4爬取笔趣阁小说的更多相关文章
- Jsoup-基于Java实现网络爬虫-爬取笔趣阁小说
注意!仅供学习交流使用,请勿用在歪门邪道的地方!技术只是工具!关键在于用途! 今天接触了一款有意思的框架,作用是网络爬虫,他可以像操作JS一样对网页内容进行提取 初体验Jsoup <!-- Ma ...
- Python爬取笔趣阁小说,有趣又实用
上班想摸鱼?为了摸鱼方便,今天自己写了个爬取笔阁小说的程序.好吧,其实就是找个目的学习python,分享一下. 1. 首先导入相关的模块 import os import requests from ...
- scrapycrawl 爬取笔趣阁小说
前言 第一次发到博客上..不太会排版见谅 最近在看一些爬虫教学的视频,有感而发,大学的时候看盗版小说网站觉得很能赚钱,心想自己也要搞个,正好想爬点小说能不能试试做个网站(网站搭建啥的都不会...) 站 ...
- python应用:爬虫框架Scrapy系统学习第四篇——scrapy爬取笔趣阁小说
使用cmd创建一个scrapy项目: scrapy startproject project_name (project_name 必须以字母开头,只能包含字母.数字以及下划线<undersco ...
- scrapy框架爬取笔趣阁
笔趣阁是很好爬的网站了,这里简单爬取了全部小说链接和每本的全部章节链接,还想爬取章节内容在biquge.py里在加一个爬取循环,在pipelines.py添加保存函数即可 1 创建一个scrapy项目 ...
- HttpClients+Jsoup抓取笔趣阁小说,并保存到本地TXT文件
前言 首先先介绍一下Jsoup:(摘自官网) jsoup is a Java library for working with real-world HTML. It provides a very ...
- scrapy框架爬取笔趣阁完整版
继续上一篇,这一次的爬取了小说内容 pipelines.py import csv class ScrapytestPipeline(object): # 爬虫文件中提取数据的方法每yield一次it ...
- 爬虫入门实例:利用requests库爬取笔趣小说网
w3cschool上的来练练手,爬取笔趣看小说http://www.biqukan.com/, 爬取<凡人修仙传仙界篇>的所有章节 1.利用requests访问目标网址,使用了get方法 ...
- python入门学习之Python爬取最新笔趣阁小说
Python爬取新笔趣阁小说,并保存到TXT文件中 我写的这篇文章,是利用Python爬取小说编写的程序,这是我学习Python爬虫当中自己独立写的第一个程序,中途也遇到了一些困难,但是最后 ...
随机推荐
- UF_CSYS 坐标系操作
Open C UF_CSYS_ask_csys_info 获取WCS坐标系的原点坐标和矩阵标识UF_CSYS_ask_matrix_of_object 获得对象 ...
- 在H5页面播放m3u8音频文件
需要使用hls插件 首先安装依赖npm install hls.js --save <audio ref="audio"></audio> import H ...
- Spring Boot WebFlux-08——WebFlux 中 WebSocket 实现通信
第08课:WebFlux 中 WebSocket 实现通信 前言 WebFlux 该模块中包含了对反应式 HTTP.服务器推送事件和 WebSocket 的客户端和服务器端的支持.这里我们简单实践下 ...
- SCP,SSH应用
- JS 使用try catch捕获异常
JS 使用try catch捕获异常 博客说明 文章所涉及的资料来自互联网整理和个人总结,意在于个人学习和经验汇总,如有什么地方侵权,请联系本人删除,谢谢! 简介 前端是攻克客户的先锋,需要特别注意到 ...
- 关于Ubuntu的超级管理员Root的切换及初始密码设置
背景介绍 总有一些操作,可能需要更高的超级管理员权限才能进行,甚至才可见有些文件,所以在Linux中我们需要切换到Root用户,也就是对应的Windows的Administrator账户. 从当前用户 ...
- Gerrit+replication 同步Gitlab
配置环境:gerrit 192.168.1.100gitlab 192.168.1.1011.创建秘钥 [root@gerrit ~]# ssh-keygen -m PEM -t rsa 2.添加ho ...
- 24、配置Oracle下sqlplus历史命令的回调功能
24.1.前言: 1.在oracle服务器上使用默认的sqlplus写sql命令时,如果写错了一个字母需要修改时,是无法通过 退格键消除错误的字母的,只能另起一行,重新写sql语句,而且也不能通过键盘 ...
- POJ 3304 Segments 叉积
题意: 找出一条直线,让给出的n条线段在这条直线的投影至少有一个重合的点 转化一下,以重合的点作垂线,那么这条直线一定经过那n条线段.现在就是求找到一条直线,让这条直线经过所有线段 分析: 假设存在这 ...
- 面试:Spring面试知识点总结
Spring知识点总结 1. 简介一下Spring框架. 答:Spring框架是一个开源的容器性质的轻量级框架.主要有三大特点:容器.IOC(控制反转).AOP(面向切面编程). 2. Spring框 ...