lucene相关
lucene相关:
应用领域:
- 互联网全文检索引擎(比如百度, 谷歌, 必应)
- 站内全文检索引擎(淘宝, 京东搜索功能)
- 优化数据库查询(因为数据库中使用like关键字是全表扫描也就是顺序扫描算法,查询慢)
lucene:又叫全文检索,先建立索引,在对索引进行搜索的过程。
Lucene下载
官方网站:http://lucene.apache.org/
版本:lucene4.10.3
Jdk要求:1.7以上
域的各种类型:
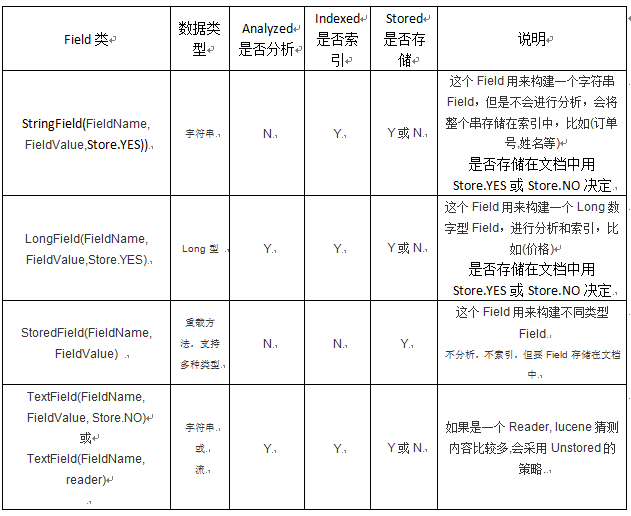
lucene的使用:
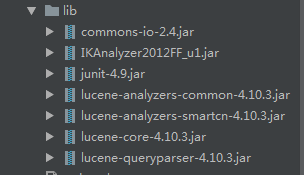
1、导入jar包:
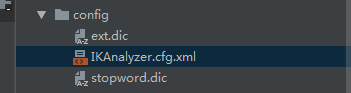
2、这里我们使用的IKAnalyzer分词器,导入相关配置:
3:代码:
新建 IndexManagerTest 类,主要用于新增、删除、修改索引:
package com.dengwei.lucene; import org.apache.commons.io.FileUtils;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.document.LongField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.Term;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
import org.junit.Test;
import org.wltea.analyzer.lucene.IKAnalyzer; import java.io.File;
import java.util.ArrayList;
import java.util.List; public class IndexManagerTest { /*
* testIndexCreate();创建索引,数据来源于txt文件
*/
@Test
public void testIndexCreate() throws Exception{
//创建文档列表,保存多个Docuemnt
List<Document> docList = new ArrayList<Document>(); //指定txt文件所在目录(需要建立索引的文件)
File dir = new File("E:\\searchsource");
//循环文件夹取出文件
for(File file : dir.listFiles()){
//文件名称
String fileName = file.getName();
//文件内容
String fileContext = FileUtils.readFileToString(file);
//文件大小
Long fileSize = FileUtils.sizeOf(file); //文档对象,文件系统中的一个文件就是一个Docuemnt对象
Document doc = new Document(); //第一个参数:域名
//第二个参数:域值
//第三个参数:是否存储,是为yes,不存储为no
/*TextField nameFiled = new TextField("fileName", fileName, Store.YES);
TextField contextFiled = new TextField("fileContext", fileContext, Store.YES);
TextField sizeFiled = new TextField("fileSize", fileSize.toString(), Store.YES);*/ //是否分词:要,因为它要索引,并且它不是一个整体,分词有意义
//是否索引:要,因为要通过它来进行搜索
//是否存储:要,因为要直接在页面上显示
TextField nameFiled = new TextField("fileName", fileName, Store.YES); //是否分词: 要,因为要根据内容进行搜索,并且它分词有意义
//是否索引: 要,因为要根据它进行搜索
//是否存储: 可以要也可以不要,不存储搜索完内容就提取不出来
TextField contextFiled = new TextField("fileContext", fileContext, Store.NO); //是否分词: 要, 因为数字要对比,搜索文档的时候可以搜大小, lunene内部对数字进行了分词算法
//是否索引: 要, 因为要根据大小进行搜索
//是否存储: 要, 因为要显示文档大小
LongField sizeFiled = new LongField("fileSize", fileSize, Store.YES); //将所有的域都存入文档中
doc.add(nameFiled);
doc.add(contextFiled);
doc.add(sizeFiled); //将文档存入文档集合中
docList.add(doc);
} //创建分词器,StandardAnalyzer标准分词器,标准分词器对英文分词效果很好,对中文是单字分词
Analyzer analyzer = new IKAnalyzer();
//指定索引和文档存储的目录
Directory directory = FSDirectory.open(new File("E:\\dic"));
//创建写对象的初始化对象
IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_4_10_3, analyzer);
//创建索引和文档写对象
IndexWriter indexWriter = new IndexWriter(directory, config); //将文档加入到索引和文档的写对象中
for(Document doc : docList){
indexWriter.addDocument(doc);
}
//提交
indexWriter.commit();
//关闭流
indexWriter.close();
} /*
* testIndexDel();删除所有和根据词源进行删除。
*/
@Test
public void testIndexDel() throws Exception{
//创建分词器,StandardAnalyzer标准分词器,标准分词器对英文分词效果很好,对中文是单字分词
Analyzer analyzer = new IKAnalyzer();
//指定索引和文档存储的目录
Directory directory = FSDirectory.open(new File("E:\\dic"));
//创建写对象的初始化对象
IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_4_10_3, analyzer);
//创建索引和文档写对象
IndexWriter indexWriter = new IndexWriter(directory, config); //删除所有
//indexWriter.deleteAll(); //根据名称进行删除
//Term词元,就是一个词, 第一个参数:域名, 第二个参数:要删除含有此关键词的数据
indexWriter.deleteDocuments(new Term("fileName", "apache")); //提交
indexWriter.commit();
//关闭
indexWriter.close();
} /**
* testIndexUpdate();更新:
* 更新就是按照传入的Term进行搜索,如果找到结果那么删除,将更新的内容重新生成一个Document对象
* 如果没有搜索到结果,那么将更新的内容直接添加一个新的Document对象
* @throws Exception
*/
@Test
public void testIndexUpdate() throws Exception{
//创建分词器,StandardAnalyzer标准分词器,标准分词器对英文分词效果很好,对中文是单字分词
Analyzer analyzer = new IKAnalyzer();
//指定索引和文档存储的目录
Directory directory = FSDirectory.open(new File("E:\\dic"));
//创建写对象的初始化对象
IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_4_10_3, analyzer);
//创建索引和文档写对象
IndexWriter indexWriter = new IndexWriter(directory, config); //根据文件名称进行更新
Term term = new Term("fileName", "web");
//更新的对象
Document doc = new Document();
doc.add(new TextField("fileName", "xxxxxx", Store.YES));
doc.add(new TextField("fileContext", "think in java xxxxxxx", Store.NO));
doc.add(new LongField("fileSize", 100L, Store.YES)); //更新
indexWriter.updateDocument(term, doc); //提交
indexWriter.commit();
//关闭
indexWriter.close();
}
}
2:新建 IndexSearchTest 类,主要用于搜索索引:
package com.dengwei.lucene; import java.io.File; import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.Term;
import org.apache.lucene.queryparser.classic.MultiFieldQueryParser;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.BooleanClause.Occur;
import org.apache.lucene.search.BooleanQuery;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.MatchAllDocsQuery;
import org.apache.lucene.search.NumericRangeQuery;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.junit.Test;
import org.wltea.analyzer.lucene.IKAnalyzer; public class IndexSearchTest {
/*
*testIndexSearch()
* 根据关键字搜索,并指定默认域
*/
@Test
public void testIndexSearch() throws Exception{ //创建分词器(创建索引和所有时所用的分词器必须一致)
Analyzer analyzer = new IKAnalyzer();
//创建查询对象,第一个参数:默认搜索域, 第二个参数:分词器
//默认搜索域作用:如果搜索语法中指定域名从指定域中搜索,如果搜索时只写了查询关键字,则从默认搜索域中进行搜索
QueryParser queryParser = new QueryParser("fileContext", analyzer);
//查询语法=域名:搜索的关键字
Query query = queryParser.parse("fileName:web"); //指定索引和文档的目录
Directory dir = FSDirectory.open(new File("E:\\dic"));
//索引和文档的读取对象
IndexReader indexReader = IndexReader.open(dir);
//创建索引的搜索对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
//搜索:第一个参数为查询语句对象, 第二个参数:指定显示多少条
TopDocs topdocs = indexSearcher.search(query, 5);
//一共搜索到多少条记录
System.out.println("=====count=====" + topdocs.totalHits);
//从搜索结果对象中获取结果集
ScoreDoc[] scoreDocs = topdocs.scoreDocs; for(ScoreDoc scoreDoc : scoreDocs){
//获取docID
int docID = scoreDoc.doc;
//通过文档ID从硬盘中读取出对应的文档
Document document = indexReader.document(docID);
//get域名可以取出值 打印
System.out.println("fileName:" + document.get("fileName"));
System.out.println("fileSize:" + document.get("fileSize"));
System.out.println("============================================================");
} } /*
*testIndexTermQuery()
* 根据关键字进行搜索,需要指定域名,和上面的对比起来,更推荐
* 使用上面的(可以指定默认域名的)
*/ @Test
public void testIndexTermQuery() throws Exception{
//创建分词器(创建索引和所有时所用的分词器必须一致)
Analyzer analyzer = new IKAnalyzer();
//创建词元:就是词,
Term term = new Term("fileName", "apache");
//使用TermQuery查询,根据term对象进行查询
TermQuery termQuery = new TermQuery(term); //指定索引和文档的目录
Directory dir = FSDirectory.open(new File("E:\\dic"));
//索引和文档的读取对象
IndexReader indexReader = IndexReader.open(dir);
//创建索引的搜索对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
//搜索:第一个参数为查询语句对象, 第二个参数:指定显示多少条
TopDocs topdocs = indexSearcher.search(termQuery, 5);
//一共搜索到多少条记录
System.out.println("=====count=====" + topdocs.totalHits);
//从搜索结果对象中获取结果集
ScoreDoc[] scoreDocs = topdocs.scoreDocs; for(ScoreDoc scoreDoc : scoreDocs){
//获取docID
int docID = scoreDoc.doc;
//通过文档ID从硬盘中读取出对应的文档
Document document = indexReader.document(docID);
//get域名可以取出值 打印
System.out.println("fileName:" + document.get("fileName"));
System.out.println("fileSize:" + document.get("fileSize"));
System.out.println("============================================================");
}
} /*
*testNumericRangeQuery();
* 用于搜索价格、大小等数值区间
*/
@Test
public void testNumericRangeQuery() throws Exception{
//创建分词器(创建索引和所有时所用的分词器必须一致)
Analyzer analyzer = new IKAnalyzer(); //根据数字范围查询
//查询文件大小,大于100 小于1000的文章
//第一个参数:域名 第二个参数:最小值, 第三个参数:最大值, 第四个参数:是否包含最小值, 第五个参数:是否包含最大值
Query query = NumericRangeQuery.newLongRange("fileSize", 100L, 1000L, true, true); //指定索引和文档的目录
Directory dir = FSDirectory.open(new File("E:\\dic"));
//索引和文档的读取对象
IndexReader indexReader = IndexReader.open(dir);
//创建索引的搜索对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
//搜索:第一个参数为查询语句对象, 第二个参数:指定显示多少条
TopDocs topdocs = indexSearcher.search(query, 5);
//一共搜索到多少条记录
System.out.println("=====count=====" + topdocs.totalHits);
//从搜索结果对象中获取结果集
ScoreDoc[] scoreDocs = topdocs.scoreDocs; for(ScoreDoc scoreDoc : scoreDocs){
//获取docID
int docID = scoreDoc.doc;
//通过文档ID从硬盘中读取出对应的文档
Document document = indexReader.document(docID);
//get域名可以取出值 打印
System.out.println("fileName:" + document.get("fileName"));
System.out.println("fileSize:" + document.get("fileSize"));
System.out.println("============================================================");
}
} /*
*testBooleanQuery();
* 组合查询,可以根据多条件进行查询
*/
@Test
public void testBooleanQuery() throws Exception{
//创建分词器(创建索引和所有时所用的分词器必须一致)
Analyzer analyzer = new IKAnalyzer(); //布尔查询,就是可以根据多个条件组合进行查询
//文件名称包含apache的,并且文件大小大于等于100 小于等于1000字节的文章
BooleanQuery query = new BooleanQuery(); //根据数字范围查询
//查询文件大小,大于100 小于1000的文章
//第一个参数:域名 第二个参数:最小值, 第三个参数:最大值, 第四个参数:是否包含最小值, 第五个参数:是否包含最大值
Query numericQuery = NumericRangeQuery.newLongRange("fileSize", 100L, 1000L, true, true); //创建词元:就是词,
Term term = new Term("fileName", "apache");
//使用TermQuery查询,根据term对象进行查询
TermQuery termQuery = new TermQuery(term); //Occur是逻辑条件
//must相当于and关键字,是并且的意思
//should,相当于or关键字或者的意思
//must_not相当于not关键字, 非的意思
//注意:单独使用must_not 或者 独自使用must_not没有任何意义
query.add(termQuery, Occur.MUST);
query.add(numericQuery, Occur.MUST); //指定索引和文档的目录
Directory dir = FSDirectory.open(new File("E:\\dic"));
//索引和文档的读取对象
IndexReader indexReader = IndexReader.open(dir);
//创建索引的搜索对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
//搜索:第一个参数为查询语句对象, 第二个参数:指定显示多少条
TopDocs topdocs = indexSearcher.search(query, 5);
//一共搜索到多少条记录
System.out.println("=====count=====" + topdocs.totalHits);
//从搜索结果对象中获取结果集
ScoreDoc[] scoreDocs = topdocs.scoreDocs; for(ScoreDoc scoreDoc : scoreDocs){
//获取docID
int docID = scoreDoc.doc;
//通过文档ID从硬盘中读取出对应的文档
Document document = indexReader.document(docID);
//get域名可以取出值 打印
System.out.println("fileName:" + document.get("fileName"));
System.out.println("fileSize:" + document.get("fileSize"));
System.out.println("============================================================");
}
} /*
*testMathAllQuery();
* 查询所有:
*/
@Test
public void testMathAllQuery() throws Exception{
//创建分词器(创建索引和所有时所用的分词器必须一致)
Analyzer analyzer = new IKAnalyzer(); //查询所有文档
MatchAllDocsQuery query = new MatchAllDocsQuery(); //指定索引和文档的目录
Directory dir = FSDirectory.open(new File("E:\\dic"));
//索引和文档的读取对象
IndexReader indexReader = IndexReader.open(dir);
//创建索引的搜索对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
//搜索:第一个参数为查询语句对象, 第二个参数:指定显示多少条
TopDocs topdocs = indexSearcher.search(query, 5);
//一共搜索到多少条记录
System.out.println("=====count=====" + topdocs.totalHits);
//从搜索结果对象中获取结果集
ScoreDoc[] scoreDocs = topdocs.scoreDocs; for(ScoreDoc scoreDoc : scoreDocs){
//获取docID
int docID = scoreDoc.doc;
//通过文档ID从硬盘中读取出对应的文档
Document document = indexReader.document(docID);
//get域名可以取出值 打印
System.out.println("fileName:" + document.get("fileName"));
System.out.println("fileSize:" + document.get("fileSize"));
System.out.println("============================================================");
}
} /*
*testMultiFieldQueryParser();
* 从多个域中进行查询
*/
@Test
public void testMultiFieldQueryParser() throws Exception{
//创建分词器(创建索引和所有时所用的分词器必须一致)
Analyzer analyzer = new IKAnalyzer(); String [] fields = {"fileName","fileContext"};
//从文件名称和文件内容中查询,只有含有apache的就查出来
MultiFieldQueryParser multiQuery = new MultiFieldQueryParser(fields, analyzer);
//输入需要搜索的关键字
Query query = multiQuery.parse("apache"); //指定索引和文档的目录
Directory dir = FSDirectory.open(new File("E:\\dic"));
//索引和文档的读取对象
IndexReader indexReader = IndexReader.open(dir);
//创建索引的搜索对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
//搜索:第一个参数为查询语句对象, 第二个参数:指定显示多少条
TopDocs topdocs = indexSearcher.search(query, 5);
//一共搜索到多少条记录
System.out.println("=====count=====" + topdocs.totalHits);
//从搜索结果对象中获取结果集
ScoreDoc[] scoreDocs = topdocs.scoreDocs; for(ScoreDoc scoreDoc : scoreDocs){
//获取docID
int docID = scoreDoc.doc;
//通过文档ID从硬盘中读取出对应的文档
Document document = indexReader.document(docID);
//get域名可以取出值 打印
System.out.println("fileName:" + document.get("fileName"));
System.out.println("fileSize:" + document.get("fileSize"));
System.out.println("============================================================");
}
}
}
lucene相关的更多相关文章
- Lucene 基础理论 (zhuan)
http://www.blogjava.net/hoojo/archive/2012/09/06/387140.html**************************************** ...
- Lucene全文检索技术
Lucene全文检索技术 今日大纲 ● 搜索的概念.搜索引擎原理.倒排索引 ● 全文索引的概念 ● 使用Lucene对索引进行CRUD操作 ● Lucene常用API详解 ● ...
- lucene 核心概念及入门
lucene Lucene介绍及核心概念 什么是Lucene Lucene是一套用于全文检索和搜索的开放源代码程序库,由Apache软件基金会支持和提供.Lucene提供了一个简单却强大的应用程序接口 ...
- lucene教程【转】【补】
现实流程 lucene 相关jar包 第一个:Lucene-core-4.0.0.jar, 其中包括了常用的文档,索引,搜索,存储等相关核心代码. 第二个:Lucene-analyzers-commo ...
- Lucene 3.0 输出相似度
http://www.cnblogs.com/ibook360/archive/2011/10/19/2217638.html Lucene3.0之结果排序(原理篇) 传统上,人们将信息检索系统返回结 ...
- lucene 学习之编码篇
本文环境:lucene5.2 JDK1.7 IKAnalyzer 引入lucene相关包 <!-- lucene核心包 --> <dependency> <g ...
- lucene构建restful风格的简单搜索引擎服务
来自于本人博客: lucene构建restful风格的简单搜索引擎服务 本人的博客如今也要改成使用lucene进行全文检索的功能,因此在这里把代码贴出来与大家分享 一,文件夹结构: 二,配置文件: 总 ...
- springboot+lucene实现公众号关键词回复智能问答
一.场景简介 最近在做公众号关键词回复方面的智能问答相关功能,发现用户输入提问内容和我们运营配置的关键词匹配回复率极低,原因是我们采用的是数据库的Like匹配. 这种模糊匹配首先不是很智能,而且也没有 ...
- Lucene入门+实现
Lucene简介详情见:(https://blog.csdn.net/Regan_Hoo/article/details/78802897) lucene实现原理 其实网上很多资料表明了,lucene ...
随机推荐
- MT【243】球内接四面体体积
已知半径为2的球面上有$A,B,C,D$四点,若$AB=CD=2$,则四面体$ABCD$的体积最大为____ 解答:利用$V=\dfrac{1}{6}|AB||CD|d<AB,CD>sin ...
- Web页面执行shell命令
本文以apache为web服务器为例 安装apache服务yum -y install httpd 启动apachesystemctl restart httpd 创建shell脚本cd /var/w ...
- 【比赛】NOIP2018 铺设道路
原题,而且还是CCF自己的 考虑对于一段最长不上升序列,无论如何都至少有序列第一个数的贡献,可以知道,这个贡献是可以做到且最少的 然后对于序列最后一位,也就是最小的那一个数,可以和后面序列拼起来的就拼 ...
- 【arc073e】Ball Coloring(线段树,贪心)
[arc073e]Ball Coloring(线段树,贪心) 题面 AtCoder 洛谷 题解 大型翻车现场,菊队完美压中男神的模拟题 首先钦定全局最小值为红色,剩下的袋子按照其中较大值排序. 枚举前 ...
- 【BZOJ4061】[Cerc2012]Farm and factory(最短路,构造)
[BZOJ4061][Cerc2012]Farm and factory(最短路,构造) 题面 BZOJ 然而权限题QwQ. 题解 先求出所有点到达\(1,2\)的最短路,不妨记为\(d_{u,1}, ...
- js多回调函数
多回调问题 前端编程时,大多通过接口交换数据,接口调用都是异步的,处理数据都是在回调函数里. 假如需要为一个用户建立档案,需要准备以下数据,然后调用建档接口 name // 用户名字 使用接口 ...
- selenium的等待~
既然使用了selenium,那么必然牺牲了一些速度上的优势,但由于公司网速不稳定,导致频频出现加载报错,这才意识到selenium等待的重要性. 说到等待又可以分为3类, 1.强制等待 time.sl ...
- 牛客练习赛43 Tachibana Kanade Loves Review C(最小生成树Kruskal)
链接:https://ac.nowcoder.com/acm/contest/548/C来源:牛客网 题目描述 立华奏是一个刚刚开始学习 OI 的萌新. 最近,实力强大的 QingyuQingyu 当 ...
- 编写高质量代码:改善Java程序的151个建议 --[0~25]
警惕自增的陷阱 public class Client7 { public static void main(String[] args) { int count=0; for(int i=0; i& ...
- sha256加密
sha256: 1.使用npm安装 :npm install js-sha256 2.然后在组件中methods定义方法,在调用 // sha256加密密码 setSha(){ let sha256 ...