ubuntu18.04 基于Hadoop3.1.2集群的Hbase2.0.6集群搭建
前置条件: 之前已经搭好了带有HDFS, MapReduce,Yarn 的 Hadoop 集群
上传tar包并修改配置文件
解压tar包到指定目录
tar -zxvf hbase-2.0.6-bin.tar.hz -C /opt/ronnie
进入配置目录
vim hbase-env.sh 修改 hbase-env.sh文件
# 添加jdk路径
export JAVA_HOME=/usr/lib/jvm/jdk1.8
# 设置不使用自带的Zookeeper
export HBASE_MANAGES_ZK=false
vim hbase-site.xml 修改 hbase-site.xml 文件
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://ns/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>node03:2181,node04:2181,node05:2181</value>
</property>
</configuration>
vim regionservers 设置 regionserver
node01
node02
node03
node04
node05
将 Hadoop 的 core-site.xml 与 hdfs-site.xml 复制到 hbase 的 conf下, 以使hbase能识别nameservice
cp /opt/ronnie/hadoop-3.1.2/etc/hadoop/{core-site.xml,hdfs-site.xml} /opt/ronnie/hbase-2.0.6/conf/
vim backup-masters 创建备用HMaster文件
node02
将Hbase 目录发送到其他虚拟机:
scp -r hbase-2.0.6/ root@node02:`pwd`
scp -r hbase-2.0.6/ root@node03:`pwd`
scp -r hbase-2.0.6/ root@node04:`pwd`
scp -r hbase-2.0.6/ root@node05:`pwd`
vim ~/.bashrc 修改配置文件, 添加:
# Hbase
export HBASE_HOME=/opt/ronnie/hbase-2.0.6
export PATH=$HBASE_HOME/bin:$PATH
source ~/.bashrc 使配置文件生效
启动测试
在node03, node04, node05节点上启动Zookeeper: zkServer.sh start
启动hdfs: start-dfs.sh
启动yarn: start-yarn.sh
启动hbase: start-hbase.sh
连接主节点的16010端口即可查看UI界面
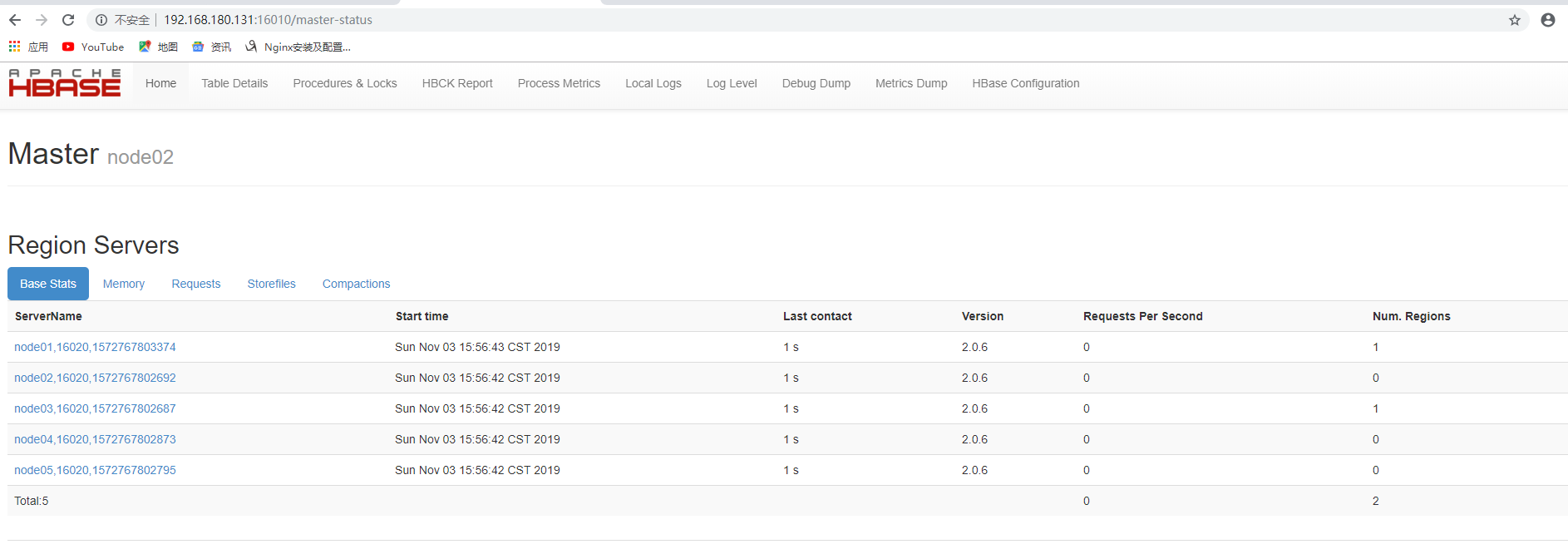
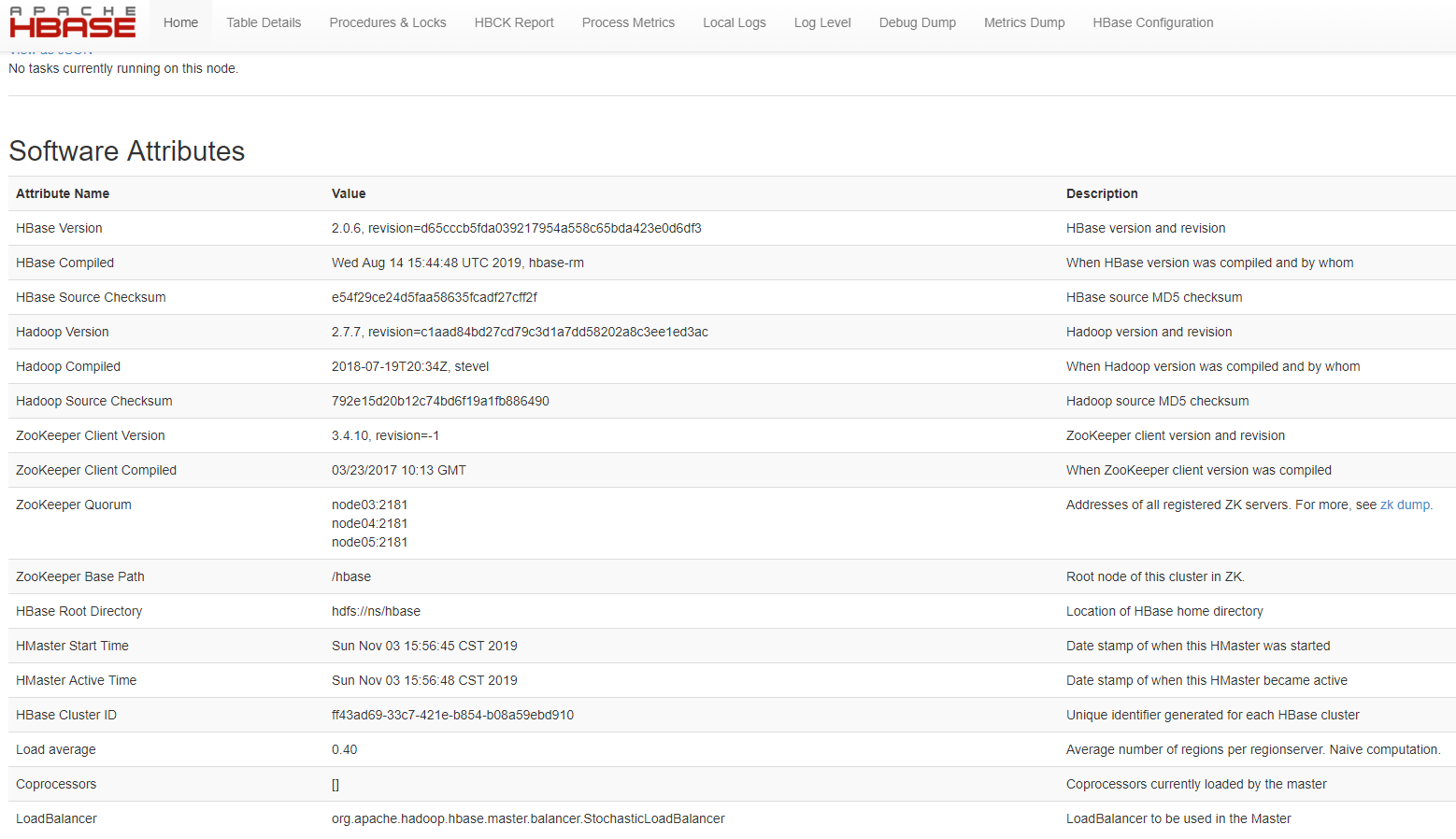
ubuntu18.04 基于Hadoop3.1.2集群的Hbase2.0.6集群搭建的更多相关文章
- ubuntu18.04.2 hadoop3.1.2+zookeeper3.5.5高可用完全分布式集群搭建
ubuntu18.04.2 hadoop3.1.2+zookeeper3.5.5高可用完全分布式集群搭建 集群规划: hostname NameNode DataNode JournalNode Re ...
- hbase-2.0.4集群部署
hbase-2.0.4集群部署 1. 集群节点规划: rzx1 HMaster,HRegionServer rzx2 HRegionServer rzx3 HRegionServer 前提:搭建好ha ...
- 04基于python玩转人工智能最火框架之TensorFlow开发环境搭建
MOOC_VM.vdl.zip 解压之后,得到一个vdl文件.打开virtual box,新建选择类型linuxubuntu 64位. 选择继续,分配2g.使用已有的虚拟硬盘文件,点击选择我们下载的文 ...
- 基于Hadoop3.1.2集群的Hive3.1.2安装(有不少坑)
前置条件: 已经安装好了带有HDFS, MapReduce, Yarn 功能的 Hadoop集群 链接: ubuntu18.04.2 hadoop3.1.2+zookeeper3.5.5高可用完全分布 ...
- ubuntu18.04 flink-1.9.0 Standalone集群搭建
集群规划 Master JobManager Standby JobManager Task Manager Zookeeper flink01 √ √ flink02 √ √ flink03 √ √ ...
- Ubuntu18.04 LTS 搭建Cassandra集群
环境需求 jdk8 root@node01:~# java -version java version "1.8.0_202" Java(TM) SE Runtime Enviro ...
- 在Ubuntu18.04下配置hadoop集群
服务器准备 启动hadoop最小集群的典型配置是3台服务器, 一台作为Master, NameNode, 两台作为Slave, DataNode. 操作系统使用的Ubuntu18.04 Server, ...
- kubeadm部署1.17.3[基于Ubuntu18.04]
基于 Ubuntu18.04 使用 kubeadm 部署Kubernetes 1.17.3 高可用集群 环境 所有节点初始化 # cat <<EOF>> /etc/hosts ...
- 部署Bookinfo示例程序详细过程和步骤(基于Kubernetes集群+Istio v1.0)
部署Bookinfo示例程序详细过程和步骤(基于Kubernetes集群+Istio v1.0) 部署Bookinfo示例程序 在下载的Istio安装包的samples目录中包含了示例应用程序. ...
随机推荐
- 使用Thymeleaf时,ajax的url如何设置?
使用Thymeleaf时,ajax的url如何设置? 最近在做一个论坛项目使用到了Thymeleaf,在使用ajax请求的时候发现无法获取BasePath.在经过一番查阅资料后终于得知如下俩种方法,在 ...
- c++类的创建与使用
c++类的创建与使用 前言: 之前一直对c++的类的创建与使用不太熟悉,有些概念还是有点模糊,借着这次休息的机会整理一下对应是知识点.如有不正确的地方还希望各位读者批评指正. 一.C++中public ...
- cmd如何进入和退出Python编程环境?
cmd里面进入python编译环境的方式: 安装Python之后需直接运行: python 即可进入Python开发环境 退出Python编译环境主要有三种方式: 1:输入exit(),回车 2:输入 ...
- etc/passwd 和 /etc/shadow 文件内容及其解释
/etc/passwd 和 /etc/shadow 文件内容及其解释 默认情况下,/etc/passwd 存储有关本地用户的信息 /etc/passwd 采用以下格式: 1)username ...
- 吴裕雄 Bootstrap 前端框架开发——Bootstrap 按钮:表示成功的动作
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> ...
- win7/10获取本地wifi密码明文
win7 单击右下角无线网图标,选择已连接的无线网 右击无线网名称,选择属性 点击标题栏的安全,再点击显示字符,即可显示wifi密码明文 win10 控制面板[查看方式选类别]-查看网络状态和任务 点 ...
- for 循环遍历数据动态渲染html
本案例通过ajax动态获取数据,然后遍历出数据渲染html小心踩坑:因为有时候不注意,渲染页面的时候只能输出最后一个数据所以正确写法为下:如果AJAX数据请求成功的情况下: html <div ...
- WCF 学习
https://www.cnblogs.com/iamlilinfeng/archive/2012/09/25/2700049.html using System.ServiceModel; name ...
- angularJs-服务调用与后台数据获取
可以用factory做一些后台数据的获取,例如 happyFarm.factory('seedList',['$http',function($http){ return { ge ...
- metasploit练习
复现ms08_067_netapi 使用模块 msf5 > use exploit/windows/smb/ms08_067_netapi 查看配置 msf5 exploit(windows/s ...