从0开始学爬虫11之使用requests库下载图片
从0开始学爬虫11之使用requests库下载图片
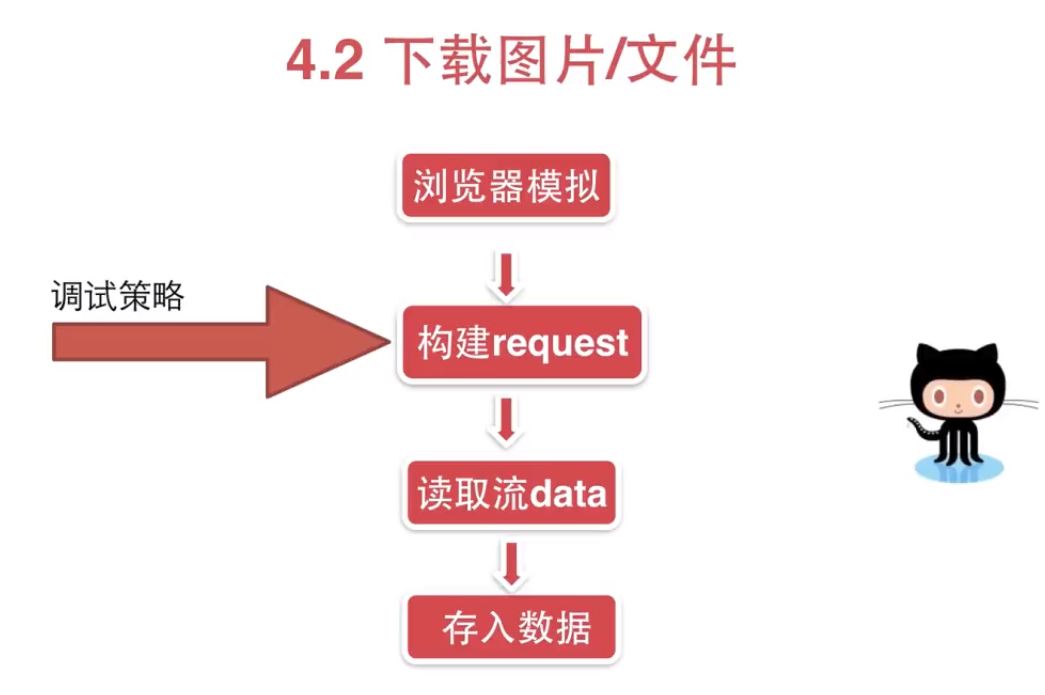
# coding=utf-8
import requests def download_imgage():
'''
demo: 下载图片
'''
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"}
url = "https://ss0.bdstatic.com/94oJfD_bAAcT8t7mm9GUKT-xh_/timg?image&quality=100&size=b4000_4000&sec=1563595148&di=1239a9121c930e1ab892faa7cd0b8f8a&src=http://m.360buyimg.com/pop/jfs/t23434/230/1763906670/10667/55866a07/5b697898N78cd1466.jpg"
response = requests.get(url,headers=headers, stream=True)
with open('demo.jpg', 'wb') as fd:
for chunk in response.iter_content(128):
fd.write(chunk) print response.content def download_image_improved():
# 伪造headers信息
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"}
# 限定url
url = "https://ss0.bdstatic.com/94oJfD_bAAcT8t7mm9GUKT-xh_/timg?image&quality=100&size=b4000_4000&sec=1563595148&di=1239a9121c930e1ab892faa7cd0b8f8a&src=http://m.360buyimg.com/pop/jfs/t23434/230/1763906670/10667/55866a07/5b697898N78cd1466.jpg"
response = requests.get(url, headers=headers, stream=True)
# contextlib 管理上下文信息
from contextlib import closing
# 可以关闭文件流
with closing(requests.get(url, headers=headers, stream=True)) as response:
# 打开文件
with open('demo1.jpg', 'wb') as fd:
# 每128字节写入一次
for chunk in response.iter_content(128):
fd.write(chunk) if __name__ == '__main__':
# download_imgage()
download_image_improved()
从0开始学爬虫11之使用requests库下载图片的更多相关文章
- 从0开始学爬虫12之使用requests库基本认证
从0开始学爬虫12之使用requests库基本认证 此处我们使用github的token进行简单测试验证 # coding=utf-8 import requests BASE_URL = " ...
- 从0开始学爬虫9之requests库的学习之环境搭建
从0开始学爬虫9之requests库的学习之环境搭建 Requests库的环境搭建 环境:python2.7.9版本 参考文档:http://2.python-requests.org/zh_CN/l ...
- 从0开始学爬虫8使用requests/pymysql和beautifulsoup4爬取维基百科词条链接并存入数据库
从0开始学爬虫8使用requests和beautifulsoup4爬取维基百科词条链接并存入数据库 Python使用requests和beautifulsoup4爬取维基百科词条链接并存入数据库 参考 ...
- 从0开始学爬虫4之requests基础知识
从0开始学爬虫4之requests基础知识 安装requestspip install requests get请求:可以用浏览器直接访问请求可以携带参数,但是又长度限制请求参数直接放在URL后面 P ...
- 从0开始学爬虫3之xpath的介绍和使用
从0开始学爬虫3之xpath的介绍和使用 Xpath:一种HTML和XML的查询语言,它能在XML和HTML的树状结构中寻找节点 安装xpath: pip install lxml HTML 超文本标 ...
- 从0开始学爬虫2之json的介绍和使用
从0开始学爬虫2之json的介绍和使用 Json 一种轻量级的数据交换格式,通用,跨平台 键值对的集合,值的有序列表 类似于python中的dict Json中的键值如果是字符串一定要用双引号 jso ...
- Python爬虫利器一之Requests库的用法
前言 之前我们用了 urllib 库,这个作为入门的工具还是不错的,对了解一些爬虫的基本理念,掌握爬虫爬取的流程有所帮助.入门之后,我们就需要学习一些更加高级的内容和工具来方便我们的爬取.那么这一节来 ...
- (转)Python爬虫利器一之Requests库的用法
官方文档 以下内容大多来自于官方文档,本文进行了一些修改和总结.要了解更多可以参考 官方文档 安装 利用 pip 安装 $ pip install requests 或者利用 easy_install ...
- 第三百二十五节,web爬虫,scrapy模块标签选择器下载图片,以及正则匹配标签
第三百二十五节,web爬虫,scrapy模块标签选择器下载图片,以及正则匹配标签 标签选择器对象 HtmlXPathSelector()创建标签选择器对象,参数接收response回调的html对象需 ...
随机推荐
- Scikit-learn库
1 简介 对Python语言有所了解的科研人员可能都知道SciPy——一个开源的基于Python的科学计算工具包.基于SciPy,目前开发者们针对不同的应用领域已经发展出了为数众多的分支版本,它们被统 ...
- (一)WCF基础
我们近期在做项目的时候用到了WCF,之前已经看了部分视频,对于WCF有了一定的了解,但仅限于能够根据搭建好的框架使用WCF,还不了解.所以就进行了研究,这样既有实践也能增加理论,二者结合,使用起来更胜 ...
- SQL Server视频总结
经过这几天艰苦卓绝的奋斗,我终于把视频看完了,可是不知道自己看了什么,下面就来总结一下,看看都学到了那些. 数据库和VB中有很多地方相似,我们可以直接搬过来,而不必再当做新知识给自己增加难度,要调动自 ...
- python操作excel(xlwt写,xlrd读)基本方法
python操作excle在测试工作中还是很有用的,比如读取测试数据,回写测试结果到excel. 1.安装 pip install xlwt pip install xlrd 2.写excel # 导 ...
- js select 默认回显判断
<select id="dataselect" class="input-medium" style="width: 20%"> ...
- SpringMVC的拦截器和数据校验
SpringMVC拦截器 什么是拦截器:Spring MVC中的拦截器(Interceptor)类似于Servlet中的过滤器(Filter),它主要用于拦截用户请求并作相应的处理.例如通过拦截器可以 ...
- MySQL 优化之EXPLAIN详解(执行计划)
学习MySQL时我们都知道索引对于一个SQL的优化很重要,而EXPLAIN关键字在分析是否正确以及高效的增加了索引时起到关键性的作用. 这篇文章显示了如何调用“EXPLAIN”来获取关于查询执行计划的 ...
- 比较ping,tracert和pathping等命令之间的关系
无论你是一个网络维护人员,还是正在学习TCP/IP协议,了解和掌握一些常用的网络测试命令将会有助于您更快地检测到网络故障所在,同时也会有助你您了解网络通信的内幕. 下面我们逐步介绍几个常用的命令: 1 ...
- C语言函数的定义和使用(2)
一:无参函数 类型说明符 get(){ //函数体 } 二:无参函数 类型说明符 getname(int a,int b){ //函数体 } 三:类型说明符包括: int ,char,float,do ...
- 洛谷 P2010 回文日期 题解
P2010 回文日期 题目描述 在日常生活中,通过年.月.日这三个要素可以表示出一个唯一确定的日期. 牛牛习惯用88位数字表示一个日期,其中,前44位代表年份,接下来22位代表月 份,最后22位代表日 ...