Scrapyd部署
从github(https://github.com/scrapy/scrapyd)下载安装包
放到D:\python\Lib\site-packages\
解压压缩包:cd 到解压目录
python setup.py install
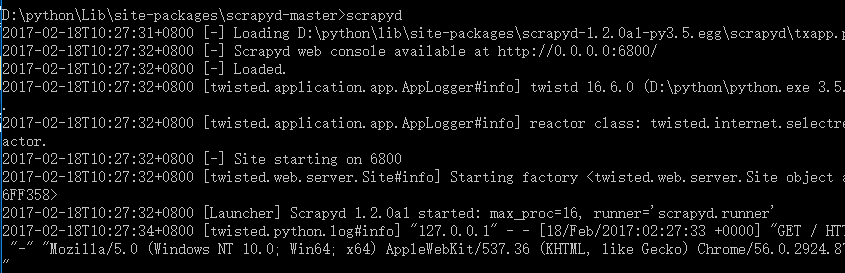
执行命令:Scrapyd;如下证明安装成功
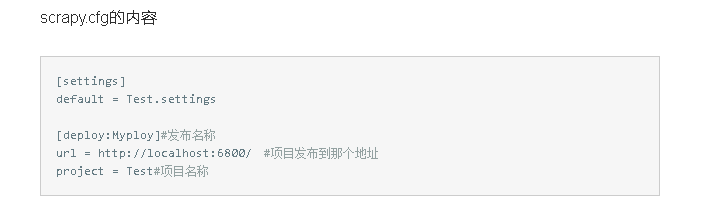
在项目中找到scrapy.cfg文件,编辑如下:
在scrapy.cfg所在目录中执行命令:
scrapyd-deploy Myploy -p Test #在scrapy.cfg文件有配置
报错:'scrapyd-deploy' 不是内部或外部命令,也不是可运行的程序 或批处理文件。在windows上使用scrapyd-client
安装后,并不能使用相应的命令'scrapyd-deploy'
需要在"C:\Python27\Scripts" 目录下 增加scrapyd-deploy.bat文件
内容填充为:
@echo off
"C:\python27\python.exe" "C:\python27\Scripts\scrapyd-deploy" %1 %2 %3 %4 %5 %6 %7 %8 %9
在scrapy.cfg所在目录中重新执行命令:
scrapyd-deploy Myploy -p Test #在scrapy.cfg文件有配置

现在只是将项目发布到目标地址,但是没有调度爬虫,调度爬虫需要用到curl命令,如下:
spd是自定义的:

curl http://localhost:6800/schedule.json -d project=testscrapy -d spider=spd
如果window下没有安装crul工具包,会报错:curl不是内部或外部命令,也不是可运行的程序 或批处理文件。
下载:http://curl.haxx.se/download.html;找到系统对应的版本;下载到本地并解压,找到curl.exe 所在路径配置到系统环境变量中;
再次输入:curl http://localhost:6800/schedule.json -d project=testscrapy -d spider=spd

参考:
http://www.jianshu.com/p/694a56b2199a
http://blog.wiseturtles.com/posts/scrapyd.html
http://blog.csdn.net/xxwang6276/article/details/45745181
Scrapyd部署的更多相关文章
- Scrapyd部署爬虫
Scrapyd部署爬虫 准备工作 安装scrapyd: pip install scrapyd 安装scrapyd-client : pip install scrapyd-client 安装curl ...
- 第三百七十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目
第三百七十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目 scrapyd模块是专门用于部署scrapy项目的,可以部署和管理scrapy项目 下载地址:h ...
- 五十一 Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目
scrapyd模块是专门用于部署scrapy项目的,可以部署和管理scrapy项目 下载地址:https://github.com/scrapy/scrapyd 建议安装 pip3 install s ...
- 爬虫部署 --- scrapyd部署爬虫 + Gerapy 管理界面 scrapyd+gerapy部署流程
---------scrapyd部署爬虫---------------1.编写爬虫2.部署环境pip install scrapyd pip install scrapyd-client 启动scra ...
- scrapyd部署、使用Gerapy 分布式爬虫管理框架
Scrapyd部署爬虫项目 GitHub:https://github.com/scrapy/scrapyd API 文档:http://scrapyd.readthedocs.io/en/stabl ...
- 潭州课堂25班:Ph201805201 爬虫高级 第九课 scrapyd 部署 (课堂笔记)
c rapyd是 scrapy 的部署, 是官方提供的一个爬虫管理工具, 通过他可以非常方便的上传控制爬虫的运行, 安装 : pip install scapyd 他提供了一个json ,web, s ...
- scrapy 项目通过scrapyd部署
年前的时候采用scrapy 爬取了某网站的数据,当时只是通过crawl 来运行了爬虫,现在还想通过持续的爬取数据所以需要把爬虫部署起来,查了下文档可以采用scrapyd来部署scrapy项目,scra ...
- 1.scrapyd部署相关问题
部署scrapy爬虫项目到6800上 启动scrapyd 出现问题 1: scrapyd-deloy -l 未找到相关命令 scrapyd-deploy -l 可以看到当前部署的爬虫项目,但是当我输 ...
- 使用Scrapyd部署Scrapy爬虫到远程服务器上
1.准备好爬虫程序 2.修改项目配置 找到项目配置文件scrapy.cnf,将里面注释掉的url解开来 本代码需要连接数据库,因此需要修改对应的数据库配置 其实就是将里面的数据库地址进行修改,变成远程 ...
随机推荐
- Python Challenge 第一关
偶然在网上看到这个,PYTHON CHALLENGE,利用Python语言闯关,觉得挺有意思,就记录一下. 第0关应该算个入口吧,试了好几次才试出来,没什么代码就不写了.计算一个结果出来就行. 第一关 ...
- [Web Tools] 实用的Web开发工具
模拟http请求:Postman https://www.getpostman.com 生成Json数据 http://www.json-generator.com/
- 洛谷——P2527 [SHOI2001]Panda的烦恼
P2527 [SHOI2001]Panda的烦恼 题目描述 panda是个数学怪人,他非常喜欢研究跟别人相反的事情.最近他正在研究筛法,众所周知,对一个范围内的整数,经过筛法处理以后,剩下的全部都 ...
- k8s之nginx-ingress、 Daemonset实现生产案例
上一篇中用node ip + 非80端口,访问k8s集群内部的服务.实际生产中更希望用node ip + 80端口的方式,访问k8s集群内的服务. # 修改mandatory.yaml中创建控制器部分 ...
- SpringBoot 整合 RabbitMQ(包含三种消息确认机制以及消费端限流)
目录 说明 生产端 消费端 说明 本文 SpringBoot 与 RabbitMQ 进行整合的时候,包含了三种消息的确认模式,如果查询详细的确认模式设置,请阅读:RabbitMQ的三种消息确认模式 同 ...
- xshell配置
字体:DejaVu Sans Mono 或者 Consolas 11号
- Maven创建Web工程并执行构建/测试/打包/部署
创建工程基本参考上一篇Java Application工程,不同的是命令参数变了,创建Web工程的命令如下: mvn archetype:generate -DgroupId=com.jsoft.te ...
- 更新tensorflow支持GPU时出错
sudo pip install --upgrade tensorflow-gpu Operation not permitted: '/tmp/pip-Sx_vMg-uninstall/System ...
- Cocos2d-X中Menu的综合运用
今天将曾经写的代码和项目集成到了一个菜单中,能够通过菜单切换到曾经做的项目 程序的project文件夹 主要代码分析: LessonMenu.h中实现创建菜单,遍历菜单通过菜单切换到各个项目 #ifn ...
- log4net报错Could not load type 'System.Security.Claims.ClaimsIdentity'
使用log4net,在win7上可以正常使用,但是在部分xp电脑上可以生成access数据库,但是无法写数据到mdb 排除了程序原因,怀疑是xp缺少什么dll之类的 偶然查到log4net的调试方法: ...