【十大经典数据挖掘算法】k
【十大经典数据挖掘算法】系列
1. 引言
k-means与kNN虽然都是以k打头,但却是两类算法——kNN为监督学习中的分类算法,而k-means则是非监督学习中的聚类算法;二者相同之处:均利用近邻信息来标注类别。
聚类是数据挖掘中一种非常重要的学习流派,指将未标注的样本数据中相似的分为同一类,正所谓“物以类聚,人以群分”嘛。k-means是聚类算法中最为简单、高效的,核心思想:由用户指定k个初始质心(initial centroids),以作为聚类的类别(cluster),重复迭代直至算法收敛。
2. 基本算法
在k-means算法中,用质心来表示cluster;且容易证明k-means算法收敛等同于所有质心不再发生变化。基本的k-means算法流程如下:
选取k个初始质心(作为初始cluster);
repeat:
对每个样本点,计算得到距其最近的质心,将其类别标为该质心所对应的cluster;
重新计算k个cluser对应的质心;
until 质心不再发生变化对于欧式空间的样本数据,以平方误差和(sum of the squared error, SSE)作为聚类的目标函数,同时也可以衡量不同聚类结果好坏的指标:
SSE=k∑i=1∑x∈Cidist(x,ci)
表示样本点x到cluster Ci 的质心 ci 距离平方和;最优的聚类结果应使得SSE达到最小值。
下图中给出了一个通过4次迭代聚类3个cluster的例子:
k-means存在缺点:
k-means是局部最优的,容易受到初始质心的影响;比如在下图中,因选择初始质心不恰当而造成次优的聚类结果(SSE较大):
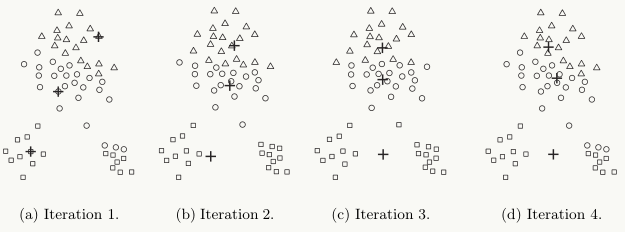
同时,k值的选取也会直接影响聚类结果,最优聚类的k值应与样本数据本身的结构信息相吻合,而这种结构信息是很难去掌握,因此选取最优k值是非常困难的。
3. 优化
为了解决上述存在缺点,在基本k-means的基础上发展而来二分 (bisecting) k-means,其主要思想:一个大cluster进行分裂后可以得到两个小的cluster;为了得到k个cluster,可进行k-1次分裂。算法流程如下:
初始只有一个cluster包含所有样本点;
repeat:
从待分裂的clusters中选择一个进行二元分裂,所选的cluster应使得SSE最小;
until 有k个cluster上述算法流程中,为从待分裂的clusters中求得局部最优解,可以采取暴力方法:依次对每个待分裂的cluster进行二元分裂(bisect)以求得最优分裂。二分k-means算法聚类过程如图:
从图中,我们观察到:二分k-means算法对初始质心的选择不太敏感,因为初始时只选择一个质心。
4. 参考资料
[1] Pang-Ning Tan, Michael Steinbach, Vipin Kumar, Introduction to Data Mining.
[2] Xindong Wu, Vipin Kumar, The Top Ten Algorithms in Data Mining.
【十大经典数据挖掘算法】k的更多相关文章
- 【十大经典数据挖掘算法】PageRank
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 我特地把PageRank作为[十大经 ...
- 【十大经典数据挖掘算法】SVM
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART SVM(Support Vector ...
- 【十大经典数据挖掘算法】Naïve Bayes
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 朴素贝叶斯(Naïve Bayes) ...
- 【十大经典数据挖掘算法】C4.5
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 决策树模型与学习 决策树(de ...
- 【十大经典数据挖掘算法】k-means
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 引言 k-means与kNN虽 ...
- 【十大经典数据挖掘算法】Apriori
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 关联分析 关联分析是一类非常有 ...
- 【十大经典数据挖掘算法】kNN
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 引言 顶级数据挖掘会议ICDM ...
- 【十大经典数据挖掘算法】CART
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 前言 分类与回归树(Class ...
- 【十大经典数据挖掘算法】EM
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 极大似然 极大似然(Maxim ...
随机推荐
- JAVA多线程提高六:java5线程并发库的应用_线程池
前面我们对并发有了一定的认识,并且知道如何创建线程,创建线程主要依靠的是Thread 的类来完成的,那么有什么缺陷呢?如何解决? 一.对比new Threadnew Thread的弊端 a. 每次ne ...
- PHP与Ajax
如何用PHP接收JSON格式数据 1.一般来说,我们直接用$_POST $_REQUEST $_GET这样的超全局变量接收就好了 <?php $obj_temp=$_POST['data']; ...
- 【转】ubuntu 11.04使用apt-get安装软件时一直提示E:unable to locate package
问题: VMware虚拟机安装了ubuntu 11.04,在使用apt-get安装软件时一直提示E:Unable to locate package. 百度了原因,说是要更新源,使用命令:sudo a ...
- 每个Web开发者都需要具备的9个软技能
对于一份工作,你可能专注于修炼自己的内功,会在不自觉中忽视软技能.硬技能决定你是否能得到工作,而软技能能够表明你是否适合这份工作和适应工作环境等.所有的公司都有属于自己的文化,并努力将这些文化传承下去 ...
- 使用 WebSockets 技术的 9 个应用场景
没有其他技术能够像WebSocket一样提供真正的双向通信,许多web开发者仍然是依赖于ajax的长轮询来实现.对Websocket缺少热情,也许是因为多年前他的安全性的脆弱,抑或者是缺少浏览器的支持 ...
- 《JavaScript 实战》:实现拖放(Drag & Drop)效果
拖放效果,也叫拖拽.拖动,学名Drag-and-drop ,是最常见的js特效之一.如果忽略很多细节,实现起来很简单,但往往细节才是难点所在.这个程序的原型是在做图片切割效果的时候做出来的,那时参考了 ...
- 【Codeforces752D】Santa Claus and a Palindrome [STL]
Santa Claus and a Palindrome Time Limit: 20 Sec Memory Limit: 512 MB Description 有k个串,串长都是n,每个串有一个a ...
- Vue的keep-alive
Vue的keep-alive: 简答的做下理解 缓存!页面从某一个页面跳转到另一个页面的时候,需要进行一定的缓存,然后这个时候调用的钩子函数是actived,而在第一次加载的时候,created.ac ...
- offset宏的讲解【转】
转自:http://blog.csdn.net/tigerjibo/article/details/8299584 1.offset宏讲解 #define offsetof(TYPE, MEMBER) ...
- WebHeaderCollection类
.net添加http报头 string[] allKeys = WebHeaderCollection.AllKeys; for (int i = 0; i < allKeys.Length; ...