Hadoop MapReduce编程 API入门系列之压缩和计数器(三十)
不多说,直接上代码。
Hadoop MapReduce编程 API入门系列之小文件合并(二十九)
生成的结果,作为输入源。


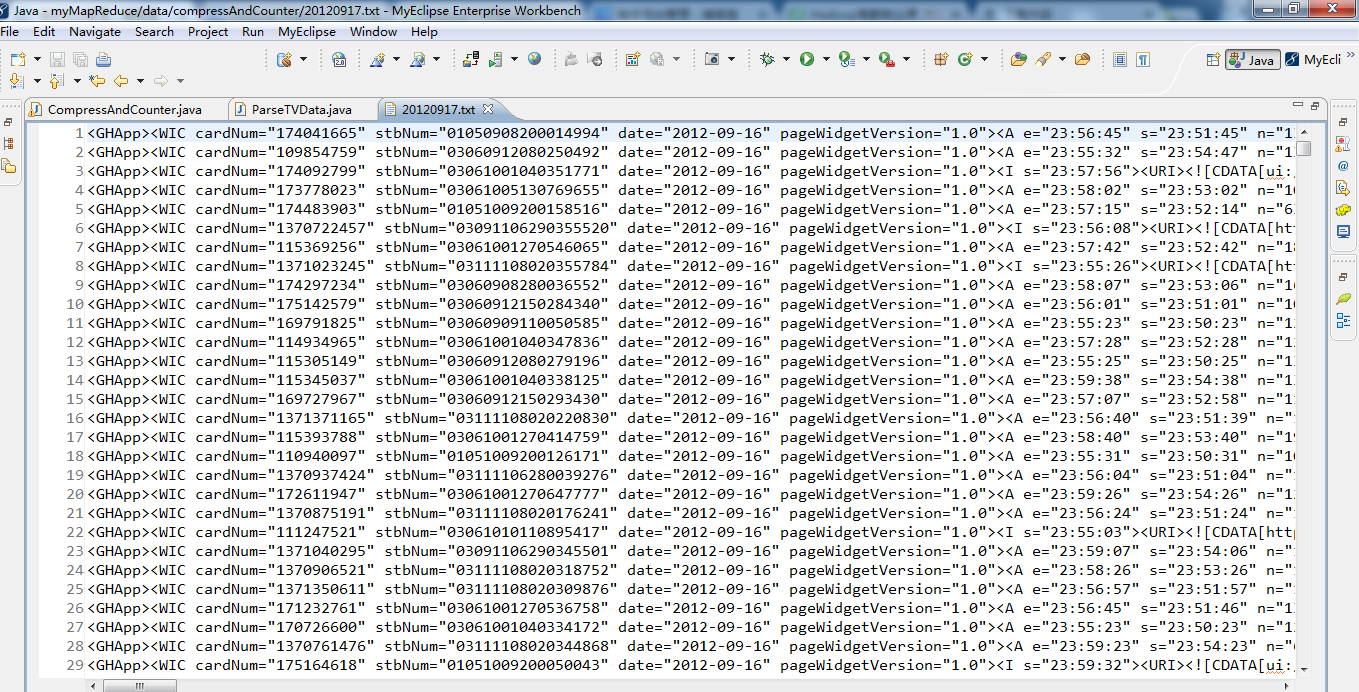
代码
package zhouls.bigdata.myMapReduce.ParseTVDataCompressAndCounter;
import java.net.URI;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.GzipCodec;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
*
* @function 统计无效数据和对输出结果进行压缩
* @author 小讲
*
*/
public class CompressAndCounter extends Configured implements Tool
{
// 定义枚举对象
public static enum LOG_PROCESSOR_COUNTER
{
BAD_RECORDS
};
/**
*
* @function Mapper 解析数据,统计无效数据,并输出有效数据
*
*/
public static class CompressAndCounterMap extends Mapper<LongWritable, Text, Text, Text>
{
protected void map(LongWritable key, Text value, Context context) throws java.io.IOException, InterruptedException
{
// 解析每条机顶盒记录,返回list集合
List<String> list = ParseTVData.transData(value.toString()); //调用ParseTVData.java下的transData方法
int length = list.size();
// 无效记录
if (length == 0)
{
// 动态自定义计数器
context.getCounter("ErrorRecordCounter", "ERROR_Record_TVData").increment(1);
// 枚举声明计数器
context.getCounter(LOG_PROCESSOR_COUNTER.BAD_RECORDS).increment(1);
} else
{
for (String validateRecord : list)
{
//输出解析数据
context.write(new Text(validateRecord), new Text(""));
}
}
}
}
/**
* @function 任务驱动方法
*
*/
@Override
public int run(String[] args) throws Exception
{
// TODO Auto-generated method stub
//读取配置文件
Configuration conf = new Configuration();
//文件系统接口
URI uri = new URI("hdfs://HadoopMaster:9000");
//输出路径
Path mypath = new Path(args[1]);
// 创建FileSystem对象
FileSystem hdfs = FileSystem.get(uri, conf);
if (hdfs.isDirectory(mypath))
{
//删除已经存在的文件路径
hdfs.delete(mypath, true);
}
Job job = new Job(conf, "CompressAndCounter");//新建一个任务
job.setJarByClass(CompressAndCounter.class);//设置主类
job.setMapperClass(CompressAndCounterMap.class);//只有 Mapper
job.setOutputKeyClass(Text.class);//输出 key 类型
job.setOutputValueClass(Text.class);//输出 value 类型
FileInputFormat.addInputPath(job, new Path(args[0]));//输入路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));//输出路径
FileOutputFormat.setCompressOutput(job, true);//对输出结果设置压缩
FileOutputFormat.setOutputCompressorClass(job, GzipCodec.class);//设置压缩类型
job.waitForCompletion(true);//提交任务
return 0;
}
/**
* @function main 方法
* @param args 输入 输出路径
* @throws Exception
*/
public static void main(String[] args) throws Exception
{
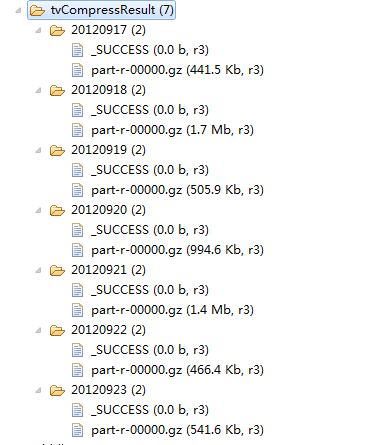
String[] date = {"20120917","20120918","20120919","20120920","20120921","20120922","20120923"};
int ec = 1;
for(String dt:date)
{
String[] args0 = { "hdfs://HadoopMaster:9000/middle/tv/"+dt+".txt",
"hdfs://HadoopMaster:9000/junior/tvCompressResult/"+dt };
// String[] args0 = { "./data/compressAndCounter/"+dt+".txt",
// "hdfs://HadoopMaster:9000/junior/tvCompressResult/"+dt };
ec = ToolRunner.run(new Configuration(), new CompressAndCounter(), args0);
}
System.exit(ec);
}
}
package zhouls.bigdata.myMapReduce.ParseTVDataCompressAndCounter;
import java.util.ArrayList;
import java.util.List;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
/**
*
* @function 解析数据
*
*
*/
public class ParseTVData
{
/**
* @function 使用 Jsoup 工具,解析输入数据,
* @param text
* @return list
*/
public static List<String> transData(String text)
{
List<String> list = new ArrayList<String>();
Document doc;
String rec = "";
try
{
doc = Jsoup.parse(text);// jsoup解析数据
Elements content = doc.getElementsByTag("WIC");
String num = content.get(0).attr("cardNum");// 记录编号
if (num == null || num.equals(""))
{
num = " ";
}
String stbNum = content.get(0).attr("stbNum");// 机顶盒号
if (stbNum.equals(""))
{
return list;
}
String date = content.get(0).attr("date");// 日期
Elements els = doc.getElementsByTag("A");
if (els.isEmpty())
{
return list;
}
for (Element el : els)
{
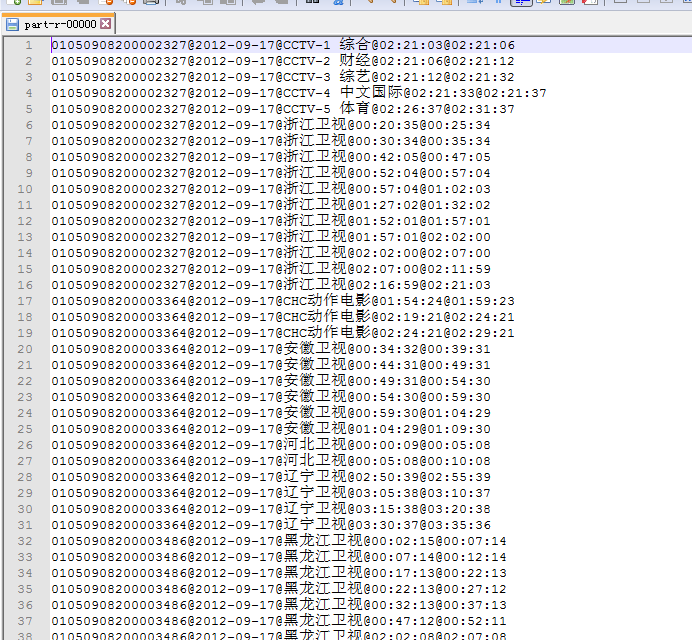
String e = el.attr("e");// 结束时间
String s = el.attr("s");// 开始时间
String sn = el.attr("sn");// 频道名称
rec = stbNum + "@" + date + "@" + sn + "@" + s + "@" + e;
list.add(rec);
}
} catch (Exception e)
{
System.out.println(e.getMessage());
return list;
}
return list;
}
}
Hadoop MapReduce编程 API入门系列之压缩和计数器(三十)的更多相关文章
- Hadoop MapReduce编程 API入门系列之薪水统计(三十一)
不多说,直接上代码. 代码 package zhouls.bigdata.myMapReduce.SalaryCount; import java.io.IOException; import jav ...
- Hadoop MapReduce编程 API入门系列之Crime数据分析(二十五)(未完)
不多说,直接上代码. 一共12列,我们只需提取有用的列:第二列(犯罪类型).第四列(一周的哪一天).第五列(具体时间)和第七列(犯罪场所). 思路分析 基于项目的需求,我们通过以下几步完成: 1.首先 ...
- Hadoop MapReduce编程 API入门系列之网页排序(二十八)
不多说,直接上代码. Map output bytes=247 Map output materialized bytes=275 Input split bytes=139 Combine inpu ...
- Hadoop MapReduce编程 API入门系列之二次排序(十六)
不多说,直接上代码. -- ::, INFO [org.apache.hadoop.metrics.jvm.JvmMetrics] - Initializing JVM Metrics with pr ...
- Hadoop MapReduce编程 API入门系列之分区和合并(十四)
不多说,直接上代码. 代码 package zhouls.bigdata.myMapReduce.Star; import java.io.IOException; import org.apache ...
- Hadoop MapReduce编程 API入门系列之挖掘气象数据版本3(九)
不多说,直接上干货! 下面,是版本1. Hadoop MapReduce编程 API入门系列之挖掘气象数据版本1(一) 下面是版本2. Hadoop MapReduce编程 API入门系列之挖掘气象数 ...
- Hadoop MapReduce编程 API入门系列之挖掘气象数据版本2(十)
下面,是版本1. Hadoop MapReduce编程 API入门系列之挖掘气象数据版本1(一) 这篇博文,包括了,实际生产开发非常重要的,单元测试和调试代码.这里不多赘述,直接送上代码. MRUni ...
- Hadoop MapReduce编程 API入门系列之计数器(二十七)
不多说,直接上代码. MapReduce 计数器是什么? 计数器是用来记录job的执行进度和状态的.它的作用可以理解为日志.我们可以在程序的某个位置插入计数器,记录数据或者进度的变化情况. Ma ...
- Hadoop MapReduce编程 API入门系列之join(二十六)(未完)
不多说,直接上代码. 天气记录数据库 Station ID Timestamp Temperature 气象站数据库 Station ID Station Name 气象站和天气记录合并之后的示意图如 ...
随机推荐
- 【LeetCode OJ】Path Sum II
Problem Link: http://oj.leetcode.com/problems/path-sum-ii/ The basic idea here is same to that of Pa ...
- swift项目中使用OC/C的方法
假如有个OC类OCViewController : UIViewController类里有两个方法 //swift调用oc或c的混编是比较常用的,反过来的调用很少.这里只写了swift调用oc和c的方 ...
- gcc学习笔记
1:第一个程序 : hello world #include <stdio.h> int main(void) { printf("Hello , world ! \n" ...
- iOS开发ARC内存管理
本文的主要内容: ARC的本质 ARC的开启与关闭 ARC的修饰符 ARC与Block ARC与Toll-Free Bridging ARC的本质 ARC是编译器(时)特性,而不是运行时特性,更不是垃 ...
- B - Encoded Love-letter 字符串的处理
B - Encoded Love-letter Time Limit:1000MS Memory Limit:32768KB 64bit IO Format:%I64d & % ...
- MySQL you *might* want to use the less safe log_bin_trust_function_creators variable
因为在打开日志文件情况下执行以前建立的 自定义函数报错详细分析如下: 1 .调用自定义函数 mysql> select sp_function_dbdh_three(); #以前自定义的函数 ...
- 阿里 RocketMQ 安装与简介
一.简介 官方简介: l RocketMQ是一款分布式.队列模型的消息中间件,具有以下特点: l 能够保证严格的消息顺序 l 提供丰富的消息拉取模式 l 高效的订阅者水平扩展能力 l 实时的 ...
- 网络数据包收发流程(三):e1000网卡和DMA
一.硬件布局每个网卡(MAC)都有自己的专用DMA Engine,如上图的 TSEC 和 e1000 网卡intel82546.上图中的红色线就是以太网数据流,DMA与DDR打交道需要其他模块的协助, ...
- [Spring MVC] - 地址路由使用(一)
常用的一些Spring MVC的路由写法以及参数传递方式. 参考引用: http://docs.spring.io/spring/docs/3.0.x/spring-framework-referen ...
- RocketMQ安装与部署说明
一.安装说明1.下载安装包,下载地址:https://github.com/alibaba/RocketMQ/releases/download/v3.1.7/alibaba-rocketmq-3.1 ...