scrapy抓取拉勾网职位信息(四)——对字段进行提取
上一篇中已经分析了详情页的url规则,并且对items.py文件进行了编写,定义了我们需要提取的字段,本篇将具体的items字段提取出来
这里主要是涉及到选择器的一些用法,如果不是很熟,可以参考:scrapy选择器的使用
依旧是在lagou_c.py文件中编写代码
首先是导入LagouItem类,因为两个__init__.py文件的存在,所在的文件夹可以作为python包来使用
from lagou.items import LagouItem
编写parse_item()函数(同样为了详细解释,又是一波注释风暴):
def parse_item(self, response):
item = LagouItem() #生成一个item对象
item['url'] = response.url #这个response是详情页面的response,因为本次我们只对详情页面使用了回调函数,所以可以这样理解
item['name'] = response.css('.name::text').extract_first() #用css选择器选择职位名称,因为结果是个列表,所以使用extract_first()提取第一个
item['salary'] = response.css('.salary::text').extract_first() #用css选择器选择薪水,但是这个是一个string类型,后续可以进行优化
location = response.xpath('//*[@class="job_request"]//span[2]/text()').extract_first() #使用xpath进行提取,span[2]代表多个平行span标签选择第二个
item['location'] = self.remove_splash(location) #得到的文本带有/,还有多余的空格,使用remove_splash函数进行清除,当然这个函数需要自己定义
work_exp = response.xpath('//*[@class="job_request"]//span[3]/text()').extract_first() #获取工作经验要求
item['work_exp'] = self.remove_splash(work_exp) #使用remove_splash对数据清洗
edu_background = response.xpath('//*[@class="job_request"]//span[4]/text()').extract_first() #获取学历要求
item['edu_background'] = self.remove_splash(edu_background)
item['type'] = response.xpath('//*[@class="job_request"]//span[5]/text()').extract_first() #获取职位类型,全职or兼职
tags = response.css('.labels::text').extract() #tags是一个列表类型,直接使用extract()进行提取,而不使用extract_first()
item['tags'] = ','.join(tags) #join函数是python内置函数,作用是把一个序列拼接起来,这里是用逗号把所有的tags标签拼接起来构成一个新的列表
item['release_time'] = response.css('.publish_time::text').extract_first() #获取发布时间,实际上这个发布时间存在很多种情况,有具体日期,也有几天前这种,后续进行优化
advantage = response.css('.job-advantage p::text').extract() #职位诱惑
item['advantage'] = '\n'.join(advantage) #用join进行拼接
job_desc = response.css('.job_bt p::text').extract() #获取职位描述
item['job_desc'] = '\n'.join(job_desc)
work_addr = response.css('.work_addr a::text').extract()[:-1] #这个工作地址列表提取出来后,需要把最后一项去掉,最后一项是地图。。
item['work_addr'] = ''.join(work_addr)
item['company'] = response.css('.job_company img::attr(alt)').extract_first() #获取公司名称
yield item
编写remove_splash()函数,这个函数传入一个值,然后对值中的/替换为空,最后将首尾的空格去掉
def remove_splash(self,value):
return value.replace(r'/','').strip()
这样我们就把需要提取的字段都提取了出来,再次运行爬虫scrapy crawl lagou_c,控制台就可以得到类似如下的输出了
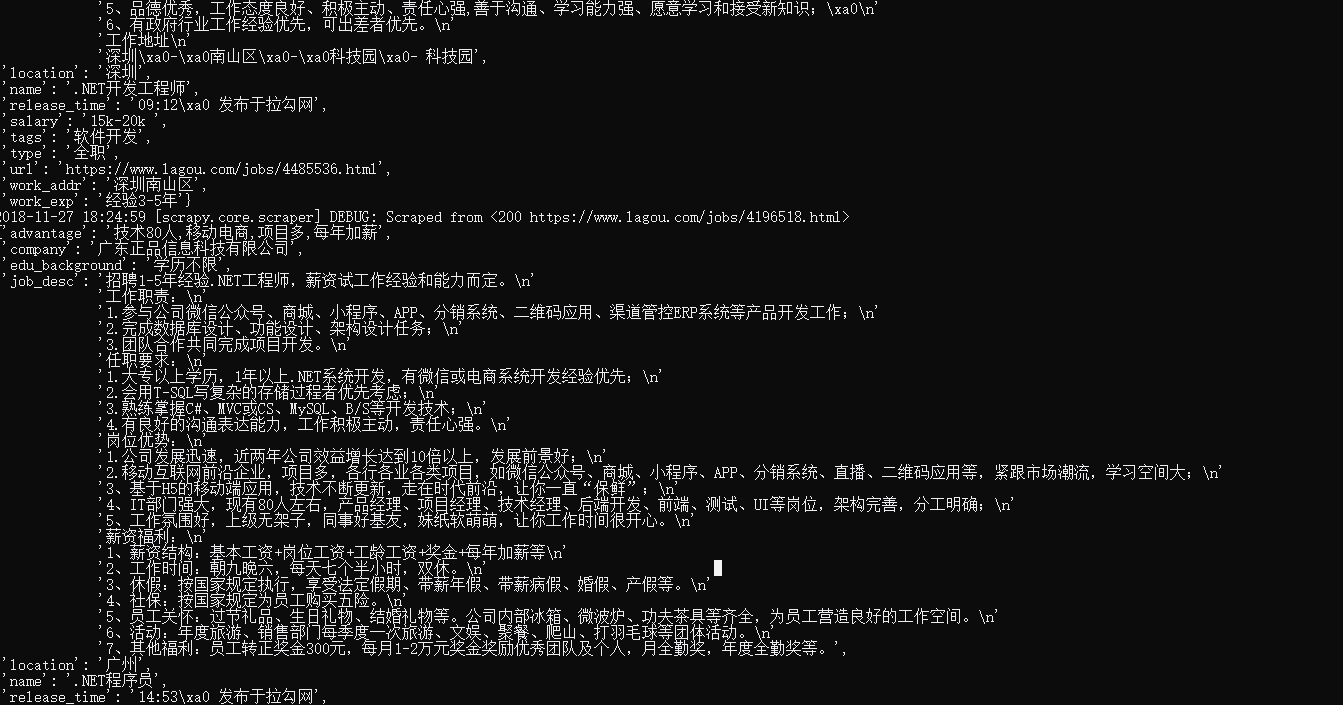
但是这抓取速度实在有点太吓人了。。。很怕被封了IP,要么限制下载速度,要么使用代理,我这里先使用限制下载速度这种措施
在settings.py文件中,取消DOWNLOAD_DELAY的注释修改为DOWNLOAD_DELAY = 1。
我们启动爬虫都是用命令行的方式来实现的,每次输入命令有点麻烦,这里我们修改一下
在根目录下建立一个main.py文件(说了那么多次根目录,其实就是进入项目文件夹后的第一个目录),代码如下:
from scrapy import cmdline
cmdline.execute('scrapy crawl lagou_c'.split())
使用这种方式得到的结果是相同的

scrapy抓取拉勾网职位信息(四)——对字段进行提取的更多相关文章
- scrapy抓取拉勾网职位信息(一)——scrapy初识及lagou爬虫项目建立
本次以scrapy抓取拉勾网职位信息作为scrapy学习的一个实战演练 python版本:3.7.1 框架:scrapy(pip直接安装可能会报错,如果是vc++环境不满足,建议直接安装一个visua ...
- scrapy抓取拉勾网职位信息(三)——爬虫rules内容编写
在上篇中,分析了拉勾网需要跟进的页面url,本篇开始进行代码编写. 在编写代码前,需要对scrapy的数据流走向有一个大致的认识,如果不是很清楚的话建议先看下:scrapy数据流 本篇目标:让拉勾网爬 ...
- scrapy抓取拉勾网职位信息(二)——拉勾网页面分析
网站结构分析: 四个大标签:首页.公司.校园.言职 我们最终是要得到详情页的信息,但是从首页的很多链接都能进入到一个详情页,我们需要对这些标签一个个分析,分析出哪些链接我们需要跟进. 首先是四个大标签 ...
- scrapy抓取拉勾网职位信息(八)——使用scrapyd对爬虫进行部署
上篇我们实现了分布式爬取,本篇来说下爬虫的部署. 分析:我们上节实现的分布式爬虫,需要把爬虫打包,上传到每个远程主机,然后解压后执行爬虫程序.这样做运行爬虫也可以,只不过如果以后爬虫有修改,需要重新修 ...
- scrapy抓取拉勾网职位信息(七)——数据存储(MongoDB,Mysql,本地CSV)
上一篇完成了随机UA和随机代理的设置,让爬虫能更稳定的运行,本篇将爬取好的数据进行存储,包括本地文件,关系型数据库(以Mysql为例),非关系型数据库(以MongoDB为例). 实际上我们在编写爬虫r ...
- scrapy抓取拉勾网职位信息(七)——实现分布式
上篇我们实现了数据的存储,包括把数据存储到MongoDB,Mysql以及本地文件,本篇说下分布式. 我们目前实现的是一个单机爬虫,也就是只在一个机器上运行,想象一下,如果同时有多台机器同时运行这个爬虫 ...
- scrapy抓取拉勾网职位信息(六)——反爬应对(随机UA,随机代理)
上篇已经对数据进行了清洗,本篇对反爬虫做一些应对措施,主要包括随机UserAgent.随机代理. 一.随机UA 分析:构建随机UA可以采用以下两种方法 我们可以选择很多UserAgent,形成一个列表 ...
- scrapy抓取拉勾网职位信息(五)——代码优化
上一篇我们已经让代码跑起来,各个字段也能在控制台输出,但是以item类字典的形式写的代码过于冗长,且有些字段出现的结果不统一,比如发布日期. 而且后续要把数据存到数据库,目前的字段基本都是string ...
- 【图文详解】scrapy爬虫与动态页面——爬取拉勾网职位信息(2)
上次挖了一个坑,今天终于填上了,还记得之前我们做的拉勾爬虫吗?那时我们实现了一页的爬取,今天让我们再接再厉,实现多页爬取,顺便实现职位和公司的关键词搜索功能. 之前的内容就不再介绍了,不熟悉的请一定要 ...
随机推荐
- 【Codeforces629C】Famil Door and Brackets [DP]
Famil Door and Brackets Time Limit: 20 Sec Memory Limit: 512 MB Description Input Output Sample Inp ...
- 如何彻底关闭退出vmware虚拟机
如何彻底关闭退出vmware虚拟机 每次使用虚拟机之后退出时,它都会在系统托盘区留下一个虚拟机图标,该如何彻底关闭退出vmware虚拟机呢? 首先我们需要运行一下虚拟机程序 1:我们如果要对虚拟机进行 ...
- 【HNOI】 小A的树 tree-dp
[题目描述]给定一颗树,每个点有各自的权值,任意选取两个点,要求算出这两个点路径上所有点的and,or,xor的期望值. [数据范围]n<=10^5 首先期望可以转化为求树上所有点对的and,o ...
- setTimeOut、setInterval与clearInterval函数
1.setTimeOut 在指定毫秒数后调用函数或计算表达式,函数或计算表达式只执行一次 setTimeout("alert('5 seconds!')",5000) 2.setI ...
- Part2-HttpClient官方教程-Chapter5-流利的API
5.1. 易于使用的Facade API 使用之前注意引入相应Jar包或者Maven依赖 <dependency> <groupId>org.apache.httpcompon ...
- JavaScript match() 方法
match() 方法可在字符串内检索指定的值,或找到一个或多个正则表达式的匹配. 该方法类似 indexOf() 和 lastIndexOf(),但是它返回指定的值,而不是字符串的位置. var st ...
- java基础 运算符
算数运算符 加号:在操作数值.字符.字符串时其结果是不同的,当两个字符相加得到的是ASCII码表值, 当两个字符串相加时表示将两个字符串连接在一起,从而组成新的字符串. 除号:整数在使用除号操作时,得 ...
- 【Android XML】Android XML 转 Java Code 系列之 介绍(1)
最近在公司做一个项目,需要把Android界面打包进jar包给客户使用.对绝大部分开发者来说,Android界面的布局以XML文件为主,并辅以少量Java代码进行动态调整.而打包进jar包的代码,意味 ...
- python基础===Character string
本文转自:python之Character string 1.python字符串 字符串是 Python 中最常用的数据类型.我们可以使用引号('或")来创建字符串,l Python不支持单 ...
- 2015多校第6场 HDU 5361 并查集,最短路
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=5361 题意:有n个点1-n, 每个点到相邻点的距离是1,然后每个点可以通过花费c[i]的钱从i点走到距 ...