HDFS核心原理
HDFS 读写解析
HDFS 读数据流程

- 客户端通过 FileSystem 向 NameNode 发起请求下载文件,NameNode 通过查询元数据找到文件所在的 DataNode 地址
- 挑选一台 DataNode(就近原则)服务器,发送读取数据请求
- DataNode 开始传输数据给客户端
- 客户端以 Packet 为单位接收,先在本地缓存,然后写入目标文件
HDFS 写数据流程
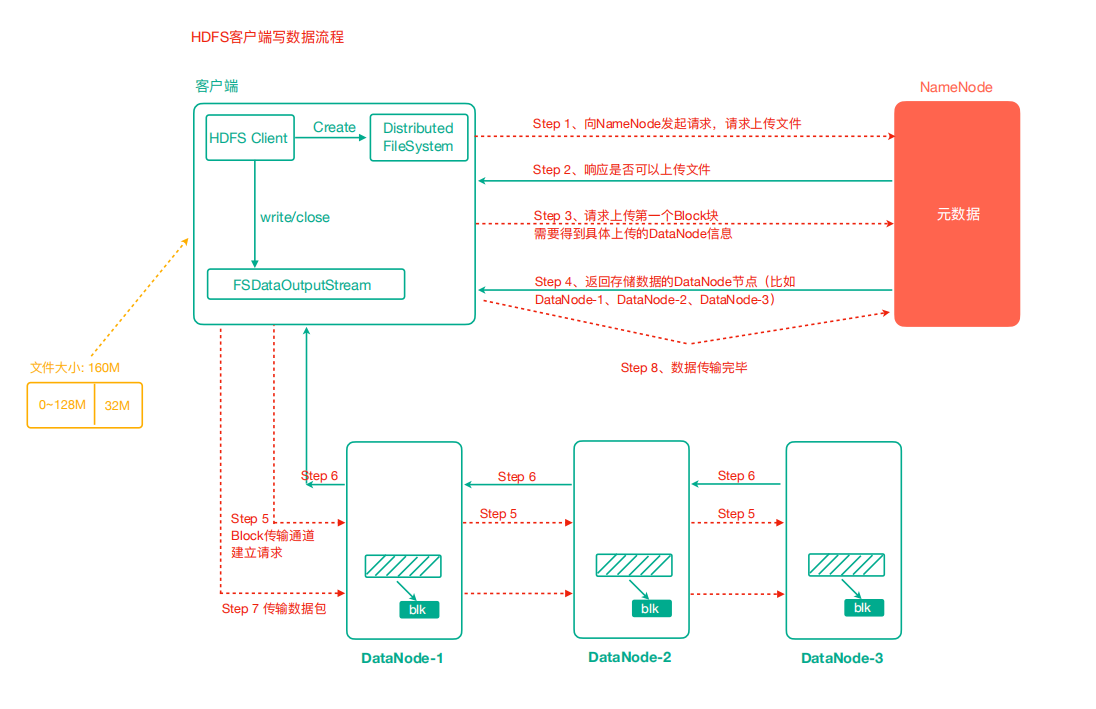
- 客户端通过 FileSystem 模块向 NameNode 发送上传文件请求,NameNode 检查目标文件是否已存在,父目录是否存在
- NameNode 返回是否可以上传
- 客户端请求询问第一个 Block 上传到哪几个 DataNode 服务器
- NameNode 返回 n 个 DataNode 节点,如 dn1、dn2、nd3
- 客户端通过 FSDataOutputStream 模块请求 dn1 上传数据,dn1 收到请求会继续调用 dn2,然后 dn2 调用 dn3,将这个通信管道建立完成
- dn1、dn2、nd3 逐级应答客户端
- 客户端开始往 dn1 上传第一个 Block(先从磁盘读取数据放到一个本地内存缓存),以 Packet 为单位,dn1 收到一个 Packet 就会传给 dn2,dn2 传给 dn3,dn1 每传一个 packet 会放入一个确认队列等待确认
- 当一个 Block 传输完成之后,客户端再次请求 NameNode 上传第二个 Block 的服务器。(重复执行 3-7 步)
默认情况下每 64kb 一个 Packet
代码验证:最开始会有一个输出,也就是一个 64k 的文件会输出两次。
@Test
public void testUploadPacket() throws IOException {
FileInputStream fis = new FileInputStream(new File("e://11.txt"));
FSDataOutputStream fos = fs.create(new Path("bbb.txt"), () -> System.out.println("每传输一个packet就会执行一次"));
IOUtils.copyBytes(fis,fos,new Configuration());
}
NameNode 和 SecondNamenode
元数据管理机制解析
- NameNode 如何管理和存储元数据?
我们一般计算机存储数据无非两种方式:内存或磁盘。内存处理数据快,但断电数据会丢失。磁盘数据处理慢,但是安全性高。
综合以上两点,NameNode 元数据的管理采用的是:内存+磁盘(FsImage 文件)的方式。
- 磁盘和内存中元数据怎么划分?
假设 1:如果要保持磁盘和元数据数据一致,那么对元数据增删改操作的时候,需要同步操作磁盘,这样效率也不高。
假设 2:两个数据合起来才是完整的数据。NameNode 引入了 edits 文件(日志文件,只能追加写入),记录增删改操作。
具体流程如下:
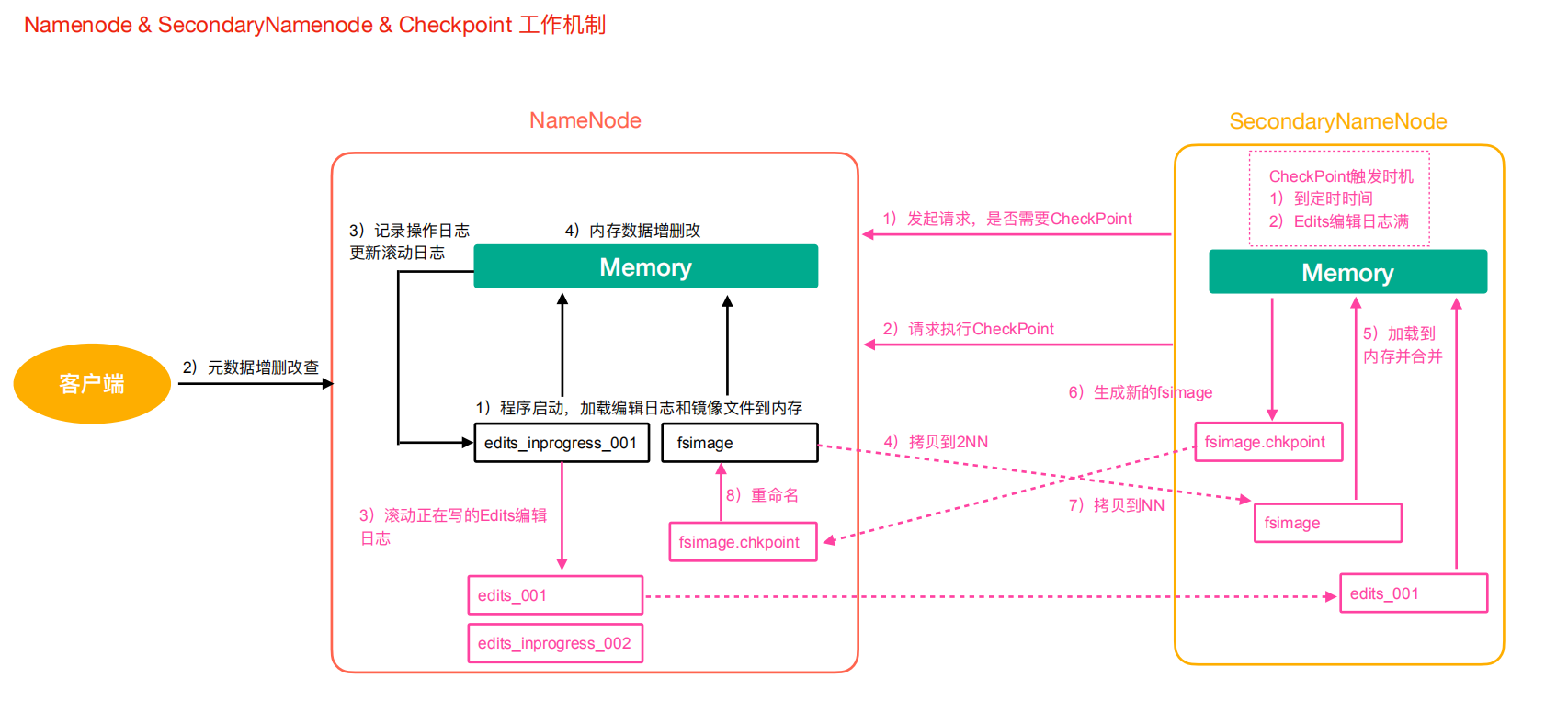
1)第一阶段:NameNode 启动
- 第一次启动 NameNode 格式化后,会创建 Fsimage 和 Edits 文件。如果部署第一次启动,直接加载编辑日志和镜像文件到内存
- 客户端对元数据增删改的请求
- NameNode 记录操作日志,更新滚动日志
- NameNode 在内存中对数据进行增删改
2)第二阶段:Secondary NameNode 工作
- Secondary NameNode 询问 NameNode 是否需要 CheckPoint。直接带回 NameNode 是否执行检查点操作结果
- Secondary NameNode 请求执行 CheckPoint
- NameNode 滚动正在写的 Edits 日志
- 将滚动前的 Edits 日志和镜像文件拷贝到 Secondary NameNode
- Secondary NameNode 加载 Edits 日志和镜像文件到内存,进行合并
- 生成新的镜像文件 fsimage.chkpint
- 拷贝 fsimage.chkpoint 到 NameNode
- NameNode 将 fsimage.chkpoint 重新命名为 fsimage
Edits 文件和镜像文件(Fsimage)解析
这两个文件位于${hadoop.tmp.dir}/dfs/name/current/下
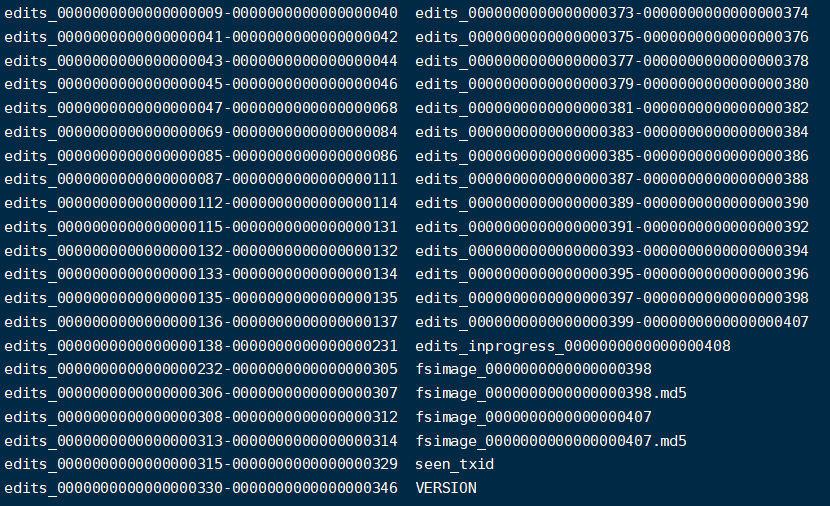
- Fsimage 文件:是 NameNode 中元数据的镜像,包含了 HDFS 文件系统的所有目录及文件信息(Block 数量、副本数量、权限等)
- Edits 文件:存储了客户端对 HDFS 文件系统的所有增删改操作
- seen_txid:该文件保存了一个数字,对应最后一个 Edits 文件名的数字
- VERSION:记录 NameNode 的一些版本号信息
1. Fsimage 文件内容查看
这些文件本身打开是乱码不可查看的,好在官方给我们提供了查看这些文件的命令。
语法:
hdfs oiv -p 文件类型(xml) -i 镜像文件 -o 转换后文件输出路径
示例:
hdfs oiv -p XML -i fsimage_0000000000000000409 -o ./fsimage.xml
我们打开 xml 文件:
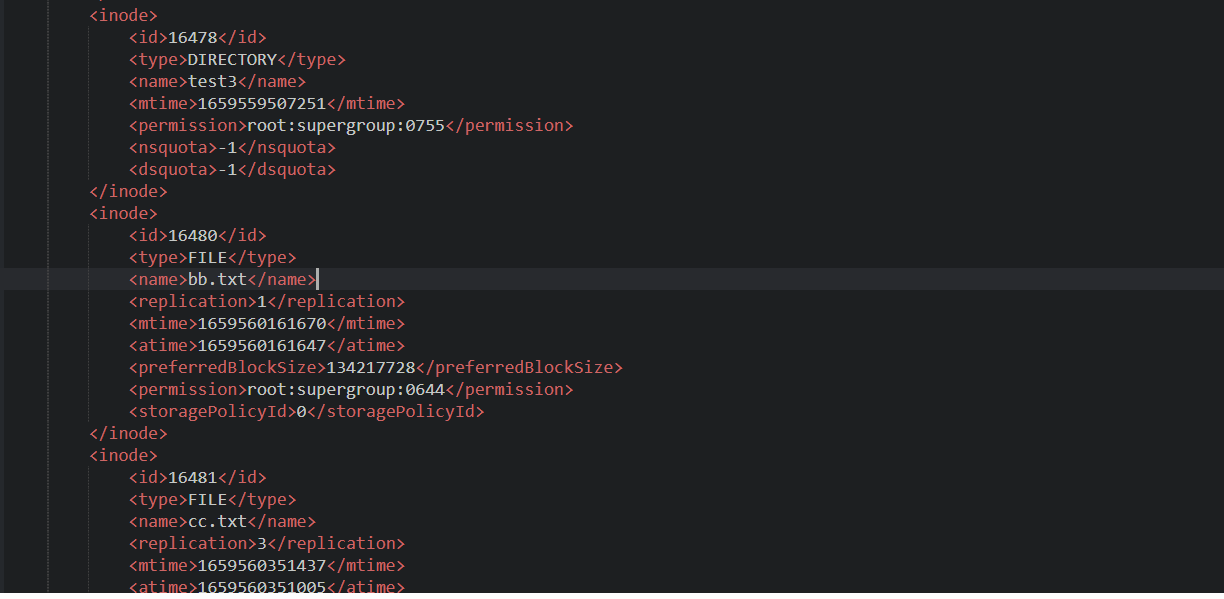
里面包含了类型、文件名、副本数、权限等等信息。注意没有保存块对应的 DataNode 的信息。
因为这个节点信息由 DataNode 自己汇报有哪些文件,而不是文件里记录属于哪个节点。否则如果每个节点宕机了,那么所有的文件都需要进行变更信息。
2. Edits 文件内容
基本语法:
hdfs oev -p 文件类型 -i编辑日志 -o 转换后文件输出路径
示例:
hdfs oev -p XML -i edits_inprogress_0000000000000000420 -o ./edits.xml
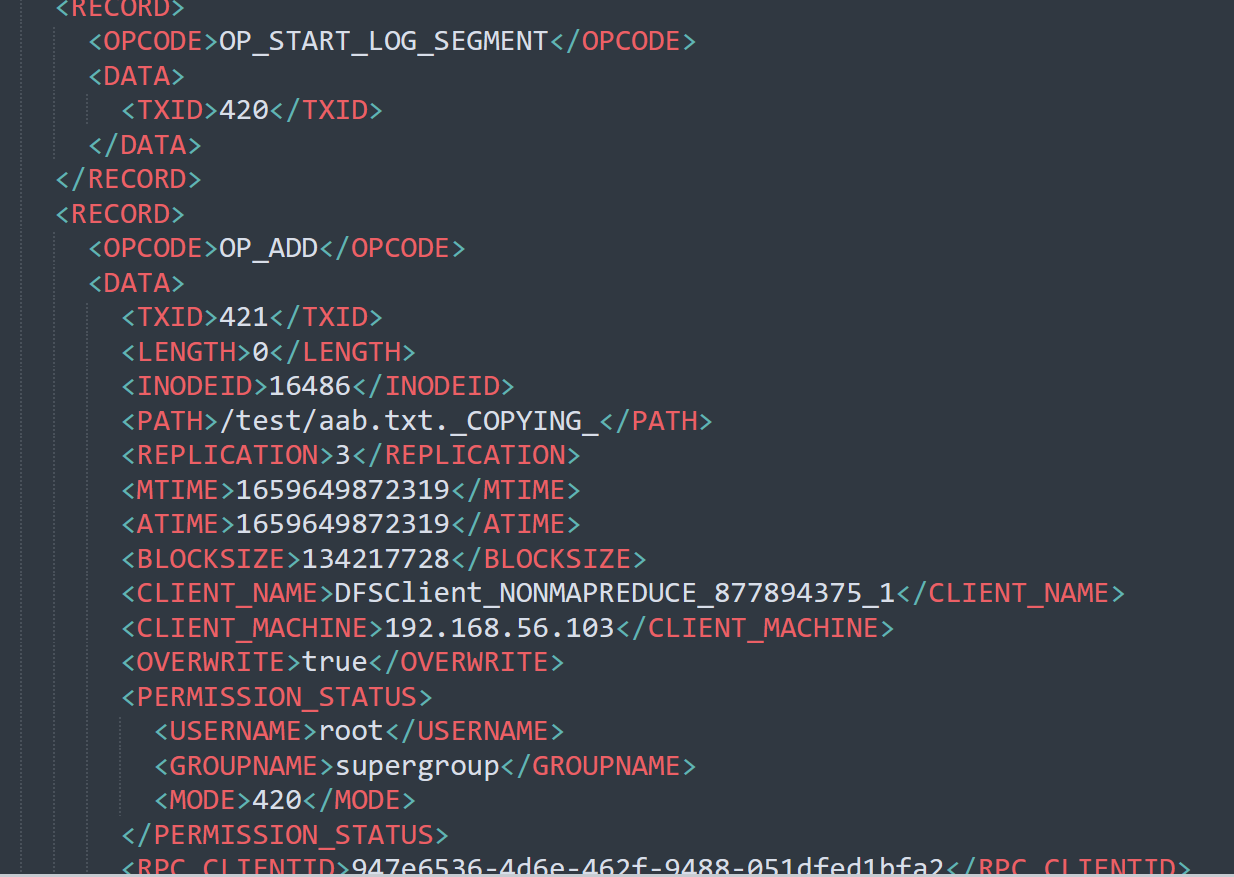
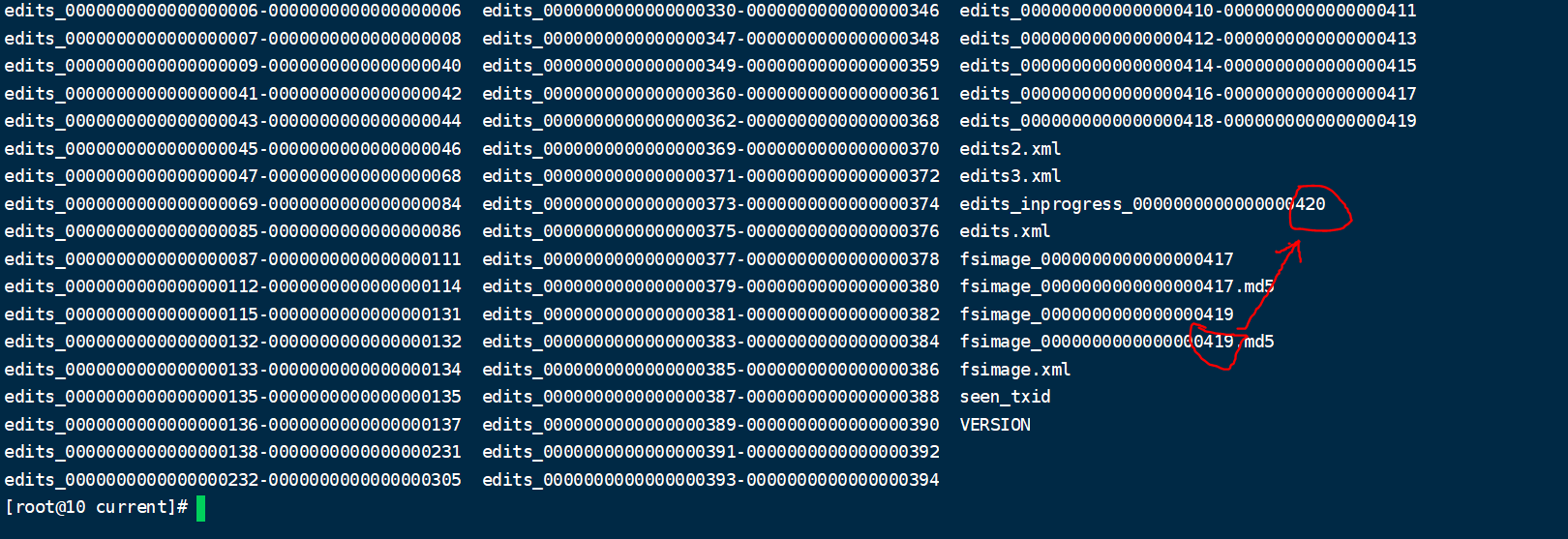
这个文件记录了我们的增删改的一些操作。我们如何确认哪些 Edits 文件没有被合并过呢?
可以通过 fsimage 文件自身的编号来确定。大于这个编号的 edits 文件就是没有合并的。
3. chekpoint 周期
周期配置我们可以在默认配置文件 hdfs-default.xml 里找到。
<!-- 定时一小时 -->
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600</value>
</property>
<!-- 一分钟检查一次操作次数,当操作次数达到1百万时,SecondaryNameNode执行一次 -->
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
<description>操作动作次数</description>
</property>
<property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>60</value>
<description> 1分钟检查一次操作次数</description>
</property >
4. NameNode 故障处理
NameNode 保存着所有的元数据信息,如果故障,整个 HDFS 集群都无法正常工作。
如果元数据出现丢失或损坏怎么恢复呢?
- 将 2nn 的元数据拷贝到 nn 下(存在一定数量的元数据丢失)
- 搭建 HDFS 的高可用集群,借助 Zookeeper 实现 HA,一个 Active 的 NameNode,一个是 Standby 的 NameNode,解决 NameNode 单点故障问题。
Hadoop 高级命令
1. HDFS 文件限额配置
HDFS 文件的限额配置允许我们以文件的大小或文件的个数来限制我们在某个目录上传的文件数量或文件大小。
- 数量限额
#设置2个的数量限制,代表只能上传一个文件
hdfs dfsadmin -setQuota 2 /west
上传第二个的时候报错:
put: The NameSpace quota (directories and files) of directory /west is exceeded: quota=2 file count=3
清除数量限制
hdfs dfsadmin -clrQuota /west
- 空间限额
#限定1k的空间
hdfs dfsadmin -setSpaceQuota 1k /west
# 清除限额
hdfs dfsadmin -clrSpaceQuota /west
#查看限额
hdfs dfs -count -q -h /west
2. HDFS 的安全模式
安全模式是 HDFS 所处的一种特殊状态,这种状态下,文件系统只能接受读请求。
在 NameNode 主节点启动时,HDFS 首先进入安全模式,DataNode 在启动的时候会向 NameNode 汇报可用的 block 等状态,当整个系统达到安全标准时,HDFS 自动离开安全模式。如果 HDFS 出于安全模式下,则文件 block 不能进行任何的副本复制操作,因此达到最小的副本数量要求是基于 DataNode 启动的状态来判定的。启动时不会再做任何复制,HDFS 集群刚启动的时候,默认 30S 的时间是处于安全期的,只有过了安全期,才可以对集群进行操作。
#进入安全模式
hdfs dfsadmin -safemode enter
#离开安全模式
hdfs dfsadmin -safemode leave
3. Hadoop 归档技术
主要解决 HDFS 集群存在大量小文件的问题。由于大量小文件占用 NameNode 的内存,因此对于 HDFS 来说存储大量小文件造成 NameNode 内存资源的浪费。
Hadoop 存档文件 HAR 文件,是一个更高效的文件存档工具,HAR 文件是由一组文件通过 archive 工具创建而来,在减少了 NameNode 的内存使用的同时,可以对文件进行透明的访问,通俗来说就是 HAR 文件对 NameNode 来说是一个文件减少了内存的浪费,对于实际操作处理文件依然是一个个独立的文件。

示例:
- 先启动 yarn
start-yarn.sh
- 归档文件
hadoop archive -archiveName input.har -p /west /westAr
- 查看归档
hadoop fs -lsr /user/root/output/input.har
- 解归档文件
hadoop fs -cp har:/// user/root/output/input.har/* /user/root
HDFS核心原理的更多相关文章
- HDFS 核心原理
HDFS 核心原理 2016-01-11 杜亦舒 HDFS(Hadoop Distribute File System)是一个分布式文件系统文件系统是操作系统提供的磁盘空间管理服务,只需要我们指定把文 ...
- 《大型网站技术架构:核心原理与案例分析》【PDF】下载
<大型网站技术架构:核心原理与案例分析>[PDF]下载链接: https://u253469.pipipan.com/fs/253469-230062557 内容简介 本书通过梳理大型网站 ...
- 大数据体系概览Spark、Spark核心原理、架构原理、Spark特点
大数据体系概览Spark.Spark核心原理.架构原理.Spark特点 大数据体系概览(Spark的地位) 什么是Spark? Spark整体架构 Spark的特点 Spark核心原理 Spark架构 ...
- 【算法】(查找你附近的人) GeoHash核心原理解析及代码实现
本文地址 原文地址 分享提纲: 0. 引子 1. 感性认识GeoHash 2. GeoHash算法的步骤 3. GeoHash Base32编码长度与精度 4. GeoHash算法 5. 使用注意点( ...
- docker核心原理
容器概念. docker是一种容器,应用沙箱机制实现虚拟化.能在一台宿主机里面独立多个虚拟环境,互不影响.在这个容器里面可以运行着我饿们的业务,输入输出.可以和宿主机交互. 使用方法. 拉取镜像 do ...
- 剖析SSH核心原理(一)
在我前面的文章中,也试图总结过SSH,见 http://blog.csdn.net/shan9liang/article/details/8803989 ,随着知识的积累,总感觉以前说得比较笼统, ...
- 关于Ajax的技术组成与核心原理
1.Ajax 特点: 局部刷新.提高用户的体验度,数据从服务器商加载 2.AJax的技术组成 不是新技术,而是之前技术的整合 Ajax: Asynchronous Javascript And Xml ...
- Libevent核心原理
Libevent 是一个事件驱动框架, 不能仅说他是一个网络库. notejs就是采用与libevent类似的libev来做核心驱动的. Libevent支持三种事件:io事件.信号事件.时间事件 ...
- 高性能消息队列 CKafka 核心原理介绍(上)
欢迎大家前往腾讯云技术社区,获取更多腾讯海量技术实践干货哦~ 作者:闫燕飞 1.背景 Ckafka是基础架构部开发的高性能.高可用消息中间件,其主要用于消息传输.网站活动追踪.运营监控.日志聚合.流式 ...
随机推荐
- 使用MinIO搭建对象存储服务
1.MinIO是什么? MinIO 是一款高性能.分布式的对象存储系统. 它是一款软件产品, 可以100%的运行在标准硬件.即X86等低成本机器也能够很好的运行MinIO. MinIO与传统的存储和其 ...
- Git标签用法
我们通常会在项目开发到一定阶段时给代码打上标签. 1.Git查看所有标签及其描述信息 git tag -l -n 2.Git创建标签 创建标签并添加描述信息 git tag -a v1.0.0 -m ...
- 浏览器上写代码,4核8G微软服务器免费用,Codespaces真香
欢迎访问我的GitHub 这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos 一图胜千言 先上图,下面是欣宸在自己的iPad Pro ...
- js颜色调试器
1 /* ColorTestViewer 颜色调试器 2 3 attribute: 4 onchange: Function; //颜色改变回调; 默认null 5 6 //以下属性不建议直接修改 7 ...
- 聊聊C#中的Mixin
写在前面 Mixin本意是指冰淇淋表面加的那些草莓酱,葡萄干等点缀物,它们负责给冰淇淋添加风味.在OOP里面也有Mixin这个概念,和它的本意相似,OOP里面的Mixin意在为类提供一些额外功能--在 ...
- 【freertos】009-任务控制
目录 前言 9.1 相对延时 9.1.1 函数原型 9.1.2 函数说明 9.1.3 参考例子 9.2 绝对延时 9.2.1 函数原型 9.2.2 函数说明 9.2.3 参考例子 9.3 获取任务优先 ...
- Linux下添加MySql组件后报无权限问题解决
Tomcat日志报错如下: Caused by: java.sql.SQLException: Access denied for user 'root'@'localhost' (using pas ...
- 小样本利器1.半监督一致性正则 Temporal Ensemble & Mean Teacher代码实现
这个系列我们用现实中经常碰到的小样本问题来串联半监督,文本对抗,文本增强等模型优化方案.小样本的核心在于如何在有限的标注样本上,最大化模型的泛化能力,让模型对unseen的样本拥有很好的预测效果.之前 ...
- 【Github】 Github访问不是私密连接问题
前言 GitHub是一个软件项目的托管平台,是我们经常需要访问的,我原本在学校时候虽然网速比较慢,但是还以能够满足一些代码下载和上传的,在暑假回到家,再去访问的时候就出现了不能访问的问题. 问题描述 ...
- 论文阅读 Real-Time Streaming Graph Embedding Through Local Actions 11
9 Real-Time Streaming Graph Embedding Through Local Actions 11 link:https://scholar.google.com.sg/sc ...