数据预处理中归一化(Normalization)与损失函数中正则化(Regularization)解惑
背景:数据挖掘/机器学习中的术语较多,而且我的知识有限。之前一直疑惑正则这个概念。所以写了篇博文梳理下
摘要:
1.正则化(Regularization)
1.1 正则化的目的
1.2 正则化的L1范数(lasso),L2范数(ridge)
2.归一化 (Normalization)
2.1归一化的目的
2.1归一化计算方法
2.2.spark ml中的归一化
2.3 python中skelearn中的归一化
知识总结:
1.正则化(Regularization)
1.1 正则化的目的:我的理解就是平衡训练误差与模型复杂度的一种方式,通过加入正则项来避免过拟合(over-fitting)。
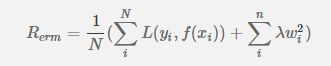
后面的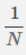
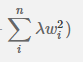 就是正则化项,其中λ越大表明惩罚粒度越大,等于0表示不做惩罚,N表示所有样本的数量,n表示参数的个数。
就是正则化项,其中λ越大表明惩罚粒度越大,等于0表示不做惩罚,N表示所有样本的数量,n表示参数的个数。

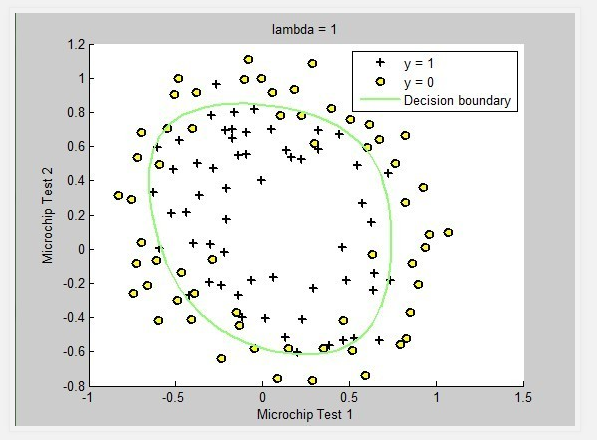
上图的 lambda = 0表示未做正则化,模型过于复杂(存在过拟合)
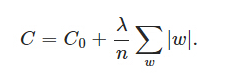 ,其中C0是代价函数,
,其中C0是代价函数,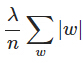 是L1正则项,lambda是正则化参数
是L1正则项,lambda是正则化参数
L2正则化:
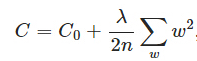 ,其中
,其中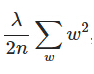 是L2正则项,lambda是正则化参数
是L2正则项,lambda是正则化参数
L1与L2正则化的比较:
1.L1会趋向于产生少量的特征,而其他的特征都是0,而L2会选择更多的特征,这些特征都会接近于0。
2.Lasso在特征选择时候非常有用,而Ridge就只是一种规则化而已。
2.归一化 (Normalization)
2.1归一化的目的:
1)归一化后加快了梯度下降求最优解的速度;
2)归一化有可能提高精度。详解可查看
2.2归一化计算方法
2.3.spark ml中的归一化
newNormalizer(p: Double) ,其中p就是计算公式中的向量绝对值的幂指数
可以使用transform方法对Vector类型或者RDD[Vector]类型的数据进行正则化
下面举一个简单的例子:
scala> val dv: Vector = Vectors.dense(3.0,4.0)
dv: org.apache.spark.mllib.linalg.Vector = [3.0,4.0]
scala> val l2 = new Normalizer(2)
scala> l2.transform(dv)
res8: org.apache.spark.mllib.linalg.Vector = [0.6,0.8]
或者直接使用Vertors的norm方法:val norms = data.map(Vectors.norm(_, 2.0))
2.4 python中skelearn中的归一化
from sklearn.preprocessing import Normalizer
#归一化,返回值为归一化后的数据
Normalizer().fit_transform(iris.data)
数据预处理中归一化(Normalization)与损失函数中正则化(Regularization)解惑的更多相关文章
- 数据预处理 | 使用 Pandas 统一同一特征中不同的数据类型
出现的问题:如图,总消费金额本应该为float类型,此处却显示object 需求:将 TotalCharges 的类型转换成float 使用 pandas.to_numeric(arg, errors ...
- python中常用的九种数据预处理方法分享
Spyder Ctrl + 4/5: 块注释/块反注释 本文总结的是我们大家在python中常见的数据预处理方法,以下通过sklearn的preprocessing模块来介绍; 1. 标准化(St ...
- sklearn中的数据预处理和特征工程
小伙伴们大家好~o( ̄▽ ̄)ブ,沉寂了这么久我又出来啦,这次先不翻译优质的文章了,这次我们回到Python中的机器学习,看一下Sklearn中的数据预处理和特征工程,老规矩还是先强调一下我的开发环境是 ...
- 机器学习实战基础(九):sklearn中的数据预处理和特征工程(二) 数据预处理 Preprocessing & Impute 之 数据无量纲化
1 数据无量纲化 在机器学习算法实践中,我们往往有着将不同规格的数据转换到同一规格,或不同分布的数据转换到某个特定分布的需求,这种需求统称为将数据“无量纲化”.譬如梯度和矩阵为核心的算法中,譬如逻辑回 ...
- 文本数据预处理:sklearn 中 CountVectorizer、TfidfTransformer 和 TfidfVectorizer
文本数据预处理的第一步通常是进行分词,分词后会进行向量化的操作.在介绍向量化之前,我们先来了解下词袋模型. 1.词袋模型(Bag of words,简称 BoW ) 词袋模型假设我们不考虑文本中词与词 ...
- 深度挖坑:从数据角度看人脸识别中Feature Normalization,Weight Normalization以及Triplet的作用
深度挖坑:从数据角度看人脸识别中Feature Normalization,Weight Normalization以及Triplet的作用 周翼南 北京大学 工学硕士 373 人赞同了该文章 基于深 ...
- Python初探——sklearn库中数据预处理函数fit_transform()和transform()的区别
敲<Python机器学习及实践>上的code的时候,对于数据预处理中涉及到的fit_transform()函数和transform()函数之间的区别很模糊,查阅了很多资料,这里整理一下: ...
- postgreSQL使用sql归一化数据表的某列,以及出现“字段 ‘xxx’ 必须出现在 GROUP BY 子句中或者在聚合函数中”错误的可能原因之一
前言: 归一化(区别于标准化)一般是指,把数据变换到(0,1)之间的小数.主要是为了方便数据处理,或者把有量纲表达式变成无量纲表达式,便于不同单位或量级的指标能够进行比较和加权. 不过还是有很多人使用 ...
- 借助 SIMD 数据布局模板和数据预处理提高 SIMD 在动画中的使用效率
原文链接 简介 为发挥 SIMD1 的最大作用,除了对其进行矢量化处理2外,我们还需作出其他努力.可以尝试为循环添加 #pragma omp simd3,查看编译器是否成功进行矢量化,如果性能有所提升 ...
随机推荐
- 最近帮客户实施的基于SQL Server AlwaysOn跨机房切换项目
最近帮客户实施的基于SQL Server AlwaysOn跨机房切换项目 最近一个来自重庆的客户找到走起君,客户的业务是做移动互联网支付,是微信支付收单渠道合作伙伴,数据库里存储的是支付流水和交易流水 ...
- ASP.NET Core MVC/WebAPi 模型绑定探索
前言 相信一直关注我的园友都知道,我写的博文都没有特别枯燥理论性的东西,主要是当每开启一门新的技术之旅时,刚开始就直接去看底层实现原理,第一会感觉索然无味,第二也不明白到底为何要这样做,所以只有当你用 ...
- 梅须逊雪三分白,雪却输梅一段香——CSS动画与JavaScript动画
CSS动画并不是绝对比JavaScript动画性能更优越,开源动画库Velocity.js等就展现了强劲的性能. 一.两者的主要区别 先开门见山的说说两者之间的区别. 1)CSS动画: 基于CSS的动 ...
- 在Linux虚拟机下配置tomcat
1.到Apache官网下载tomcat http://tomcat.apache.org/download-80.cgi 博主我下载的是tomcat8 博主的jdk是1.8 如果你们的jdk是1.7或 ...
- MFC中如何画带实心箭头的直线
工作中遇到话流程图的项目,需要画带箭头的直线,经过摸索,解决:思路如下: (1) 两个点(p1,p2)确定一个直线,以直线的一个端点(假设p2)为原点,设定一个角度 (2)以P2为原点得到向量P2P1 ...
- 如何利用ansible callback插件对执行结果进行解析
最近在写一个批量巡检工具,利用ansible将脚本推到各个机器上执行,然后将执行的结果以json格式返回来. 如下所示: # ansible node2 -m script -a /root/pyth ...
- 为IEnumerable<T>添加RemoveAll<IEnumerable<T>>扩展方法--高性能篇
最近写代码,遇到一个问题,微软基于List<T>自带的方法是public bool Remove(T item);,可是有时候我们可能会用到诸如RemoveAll<IEnumerab ...
- 破解SQLServer for Linux预览版的3.5GB内存限制 (RHEL篇)
微软发布了SQLServer for Linux,但是安装竟然需要3.5GB内存,这让大部分云主机用户都没办法尝试这个新东西 这篇我将讲解如何破解这个内存限制 要看关键的可以直接跳到第6步,只需要替换 ...
- [Nginx笔记]关于线上环境CLOSE_WAIT和TIME_WAIT过高
运维的同学和Team里面的一个同学分别遇到过Nginx在线上环境使用中会遇到TIME_WAIT过高或者CLOSE_WAIT过高的状态 先从原因分析一下为什么,问题就迎刃而解了. 首先是TIME_WAI ...
- C#——传值参数(1)
//我的C#是跟着猛哥(刘铁猛)(算是我的正式老师)<C#语言入门详解>学习的,微信上猛哥也给我讲解了一些不懂得地方,对于我来说简直是一笔巨额财富,难得良师! 这次与大家一起学习C#中的值 ...