scrapy 当当网 爬虫
前言
好久没有写实战博客了,因为前几个月在公司实习,博客更新就耽搁了下来,现在又受疫情影响无法返校,但是技能还是不能丢的,今天就写一篇使用scrapy爬取当当网的实战练习吧。
创建scrapy项目
目标站点: http://search.dangdang.com/?key=python&category_path=01.00.00.00.00.00&page_index=1 这是在当当网搜索关键字python得到的页面
第一步仍然是使用命令行切换到工作目录创建scrapy项目
- D:\pythonwork\cnblog>scrapy startproject cnblog_dangdang

然后使用cd命令进入项目中的spiders文件夹使用命令创建爬虫文件(注意:该命令后的网址跟的是目标网址域名,而不是整个网址)
- D:\pythonwork\cnblog\cnblog_dangdang\cnblog_dangdang\spiders>scrapy genspider dangdang_spider dangdang.com

此时我们的项目与基础爬虫文件已经创建完毕,接下来编写代码使用pycharm打开项目
内容分析
打开目标站点分析我们需要爬取什么内容
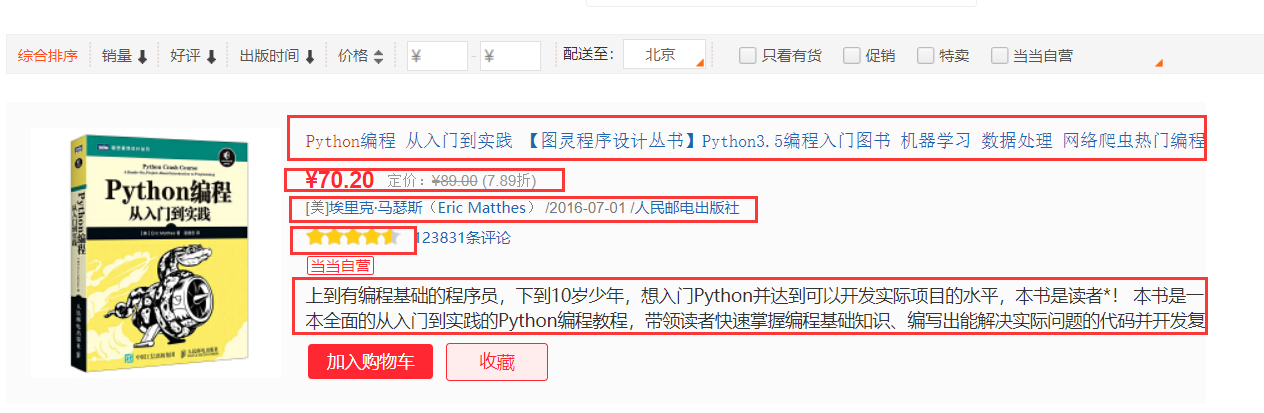
对于目标站点的商品图书而言,我们需要爬取它的标题、价格、作者、评分和概括五个部分
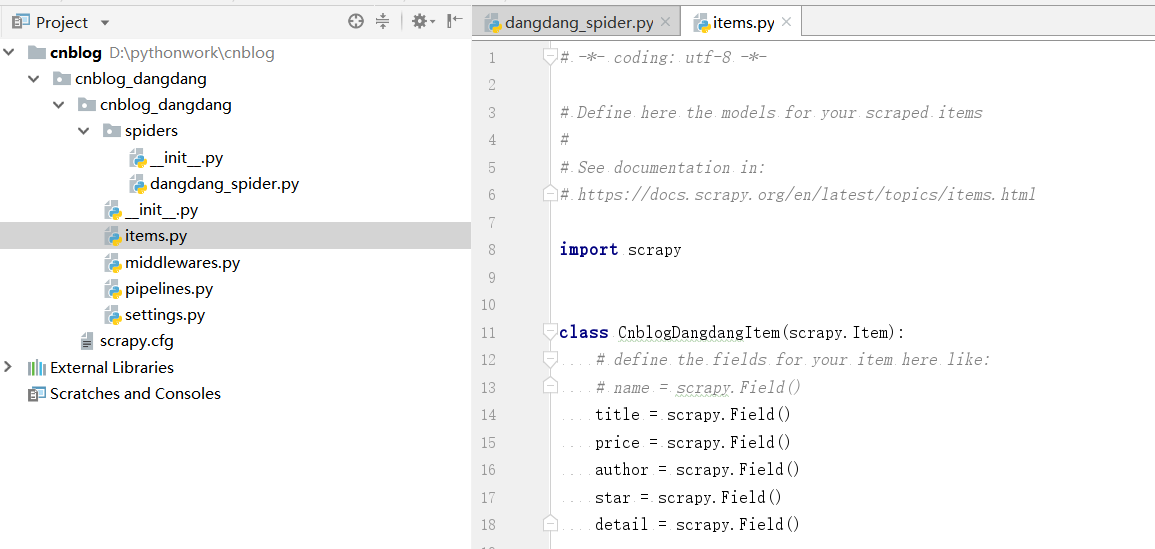
因此首先我们在项目的items.py文件中声明我们需要爬取的内容。
items.py
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html import scrapy class CnblogDangdangItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
price = scrapy.Field()
author = scrapy.Field()
star = scrapy.Field()
detail = scrapy.Field()
因此我们的数据表的sql语句创建如下:
CREATE TABLE IF NOT EXISTS dangdang_item (
id INT UNSIGNED AUTO_INCREMENT,
title CHAR(100) NOT NULL,
price CHAR(100) NOT NULL,
author CHAR(100) NOT NULL,
star CHAR(10) NOT NULL,
detail VARCHAR(1000),
PRIMARY KEY (id)
)ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
爬虫文件编写
内容分析完成之后我们到了最关键的爬虫文件编写部分,首先我们要测试下该网站有没有反爬措施。
这一步我们只需要简单的将spiders文件夹中的dangdang_spider.py文件进行简单的修改让其输出目标站点的响应内容即可
dangdang_spider.py
# -*- coding: utf-8 -*-
import scrapy class DangdangSpiderSpider(scrapy.Spider):
name = 'dangdang_spider'
allowed_domains = ['dangdang.com']
start_urls = ['http://search.dangdang.com/?key=python&category_path=01.00.00.00.00.00&page_index=1'] def parse(self, response):
print(response.text)
pass
为了方便我们进行调试,我们在项目下创建一个main.py文件用于启动爬虫,不然我们每次启动都需要在命令行中使用scrapy命令。
main.py
from scrapy import cmdline
cmdline.execute('scrapy crawl dangdang_spider'.split())
然后直接运行main.py文件,发现输出了目标网站的html源代码,所以目标网站并没有反爬措施,我们可以直接拿取内容,接下来就开始拿取内容了。
五部分内容使用xpath拿取,网页结构很简单,直接从源码分析xpath即可。
开始实际编写爬虫文件dangdang_spider.py
# -*- coding: utf-8 -*-
import scrapy
import re
from cnblog_dangdang.items import CnblogDangdangItem str_re = re.compile('\d+') class DangdangSpiderSpider(scrapy.Spider):
name = 'dangdang_spider'
allowed_domains = ['dangdang.com']
start_urls = ['http://search.dangdang.com/?key=python&category_path=01.00.00.00.00.00&page_index=1'] def parse(self, response):
book_item = CnblogDangdangItem()
items = response.xpath("//ul[@class='bigimg']/li")#不用加get 因为此步骤为了拿到一个xpath对象
for item in items:
book_item['title'] = item.xpath("./a/@title").get()
book_item['price'] = item.xpath("./p[@class='price']").xpath("string(.)").get()#使用string(.)方法为了拿取目标节点下的所有子节点文本
book_item['author'] = item.xpath("./p[@class='search_book_author']").xpath("string(.)").get()
book_item['star'] = int(str_re.findall(item.xpath("./p[@class='search_star_line']/span/span/@style").get())[0])/20
book_item['detail'] = item.xpath("./p[@class='detail']//text()").get()
print(book_item)
yield book_item next_url_end = response.xpath("//li[@class='next']/a/@href").get()
#如果拿到了下一页链接,则访问
if next_url_end:
next_url ='http://search.dangdang.com/'+ next_url_end
yield scrapy.Request(next_url,callback=self.parse)
再次运行爬虫,发现现在已经可以输出拿取到的信息

说明我们的爬虫文件编写成功,接下来就是对我们拿取到的数据进行处理。
数据的存储
此次我们选择使用mysql进行数据的存储,那么我们首先要干什么呢?是直接编写pipeline.py文件吗?并不是,我们还有一个很重要的地方没有弄,就是settings.py文件。
我们想要通过pipeline.py文件来处理爬取到的数据,首先就需要去settings.py中开启我们的pipeline选项,很简单只需要在settings.py中将ITEM_PIPELINES的注释消掉即可如下图

接下来就可以编写pipeline.py文件来对我们的数据进行操作了
pipeline.py
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html import pymysql number = 0
class DangdangPipeline(object): # open_spider()爬虫开启时执行一次
def open_spider(self,spider):
# 连接数据库
print("连接数据库,准备写入数据")
self.db = pymysql.connect('localhost', '你的mysql账户', '你的mysql密码', '你的数据库名称')
self.cursor = self.db.cursor() def process_item(self, item, spider):
global number
number = number+1
print('当前写入第'+str(number)+'个商品数据')
#使用replace是为了避免数据中存在引号与sql语句冲突
title=str(item['title']).replace("'","\\'").replace('"','\\"')
price=str(item['price']).replace("'","\\'").replace('"','\\"')
author=str(item['author']).replace("'","\\'").replace('"','\\"')
star=str(item['star']).replace("'","\\'").replace('"','\\"')
detail=str(item['detail']).replace("'","\\'").replace('"','\\"')
sql = f'INSERT INTO dangdang_item (title,price,author,star,detail) VALUES (\'{title}\',\'{price}\',\'{author}\',\'{star}\',\'{detail}\');'
#执行sql语句
self.cursor.execute(sql)
#数据库提交修改
self.db.commit()
return item # close_spider()爬虫关闭后执行
def close_spider(self,spider):
print('写入完成,一共'+str(number)+'个数据')
# 关闭连接
self.cursor.close()
self.db.close()
接下来再次运行main.py文件,看看爬虫效果。

我们去数据库中看一下我们刚刚爬取的数据
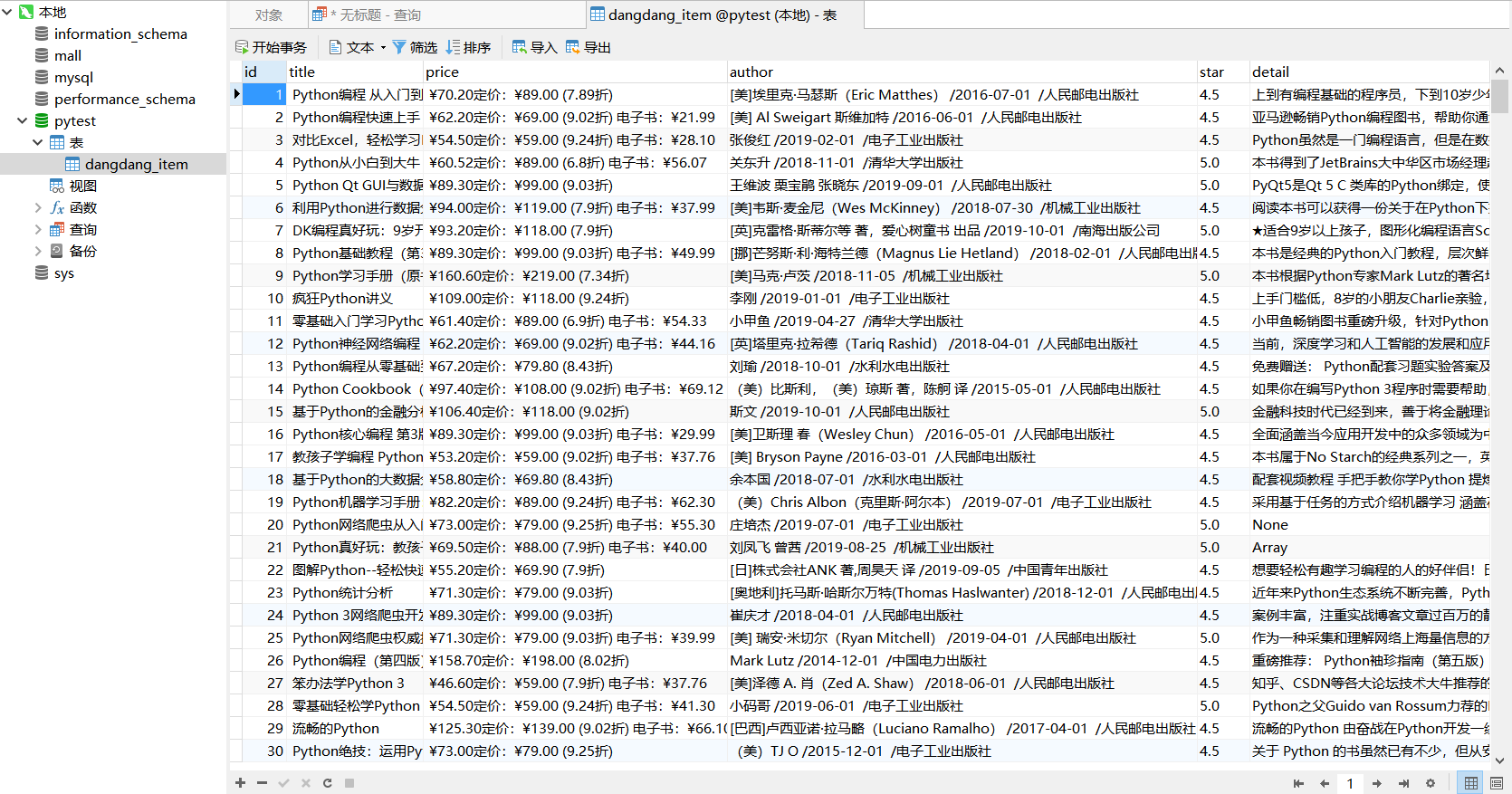
ok,大功完成了,我们的当当网scrapy爬虫就编写好了。
scrapy 当当网 爬虫的更多相关文章
- Python爬虫库Scrapy入门1--爬取当当网商品数据
1.关于scrapy库的介绍,可以查看其官方文档:http://scrapy-chs.readthedocs.io/zh_CN/latest/ 2.安装:pip install scrapy 注意这 ...
- Scrapy爬虫(5)爬取当当网图书畅销榜
本次将会使用Scrapy来爬取当当网的图书畅销榜,其网页截图如下: 我们的爬虫将会把每本书的排名,书名,作者,出版社,价格以及评论数爬取出来,并保存为csv格式的文件.项目的具体创建就不再多讲 ...
- Python 爬虫 当当网图书 scrapy
目标站点需求分析 获取当当网每个图书名字和评论数 涉及的库 scrapy,mysql 获取解析单页源码 保存到数据库中 结果
- scrapy项目3:爬取当当网中机器学习的数据及价格(spider类)
1.网页解析 当当网中,人工智能数据的首页url如下为http://category.dangdang.com/cp01.54.12.00.00.00.html 点击下方的链接,一次观察各个页面的ur ...
- scrapy获取当当网中数据
yield 1. 带有 yield 的函数不再是一个普通函数,而是一个生成器generator,可用于迭代 2. yield 是一个类似 return 的关键字,迭代一次遇到yield时就返回yiel ...
- 网络爬虫之定向爬虫:爬取当当网2015年图书销售排行榜信息(Crawler)
做了个爬虫,爬取当当网--2015年图书销售排行榜 TOP500 爬取的基本思想是:通过浏览网页,列出你所想要获取的信息,然后通过浏览网页的源码和检查(这里用的是chrome)来获相关信息的节点,最后 ...
- java爬虫,爬取当当网数据
背景:女票快毕业了(没错!我是有女票的!!!),写论文,主题是儿童性教育,查看儿童性教育绘本数据死活找不到,没办法,就去当当网查询下数据,但是数据怎么弄下来呢,首先想到用Python,但是不会!!百 ...
- python爬虫06 | 你的第一个爬虫,爬取当当网 Top 500 本五星好评书籍
来啦,老弟 我们已经知道怎么使用 Requests 进行各种请求骚操作 也知道了对服务器返回的数据如何使用 正则表达式 来过滤我们想要的内容 ... 那么接下来 我们就使用 requests 和 re ...
- 【转】java爬虫,爬取当当网数据
背景:女票快毕业了(没错!我是有女票的!!!),写论文,主题是儿童性教育,查看儿童性教育绘本数据死活找不到,没办法,就去当当网查询下数据,但是数据怎么弄下来呢,首先想到用Python,但是不会!!百 ...
随机推荐
- spring-cloud-gateway报错
2019-08-13 09:41:19.216 WARN [-,,,] 10084 --- [ main] ConfigServletWebServerApplicationContext : Exc ...
- EFCore-脚手架Scaffold发生Build Failed问题的终极解决
大家在使用EntityFrameworkCore的DBFirst的脚手架(Scaffolding)时应该遇到过Build Failed的错误,而没有任何提示,我也遇到过不少次,目前已经完美解决并将排查 ...
- openjudge 拯救公主
点击打开题目 看到这道题,第一感觉是我有一句m2p不知当讲不当讲 传送门就算了,你提莫还来宝石,还不给我每种最多有几个~~ 在一般的迷宫问题里,无论已经走了多少步,只要到达同一个点,状态便是等价的,但 ...
- centos7搭建hadoop2.10高可用(HA)
本篇介绍在centos7中搭建hadoop2.10高可用集群,首先准备6台机器:2台nn(namenode);4台dn(datanode):3台jns(journalnodes) IP hostnam ...
- GC原理---垃圾收集算法
垃圾收集算法 Mark-Sweep(标记-清除算法) 标记清除算法分为两个阶段,标记阶段和清除阶段.标记阶段任务是标记出所有需要回收的对象,清除阶段就是清除被标记对象的空间. 优缺点:实现简单,容易产 ...
- CF-528D Fuzzy Search(FFT字符串匹配)
Fuzzy Search 题意: 给定一个模式串和目标串按下图方式匹配,错开位置不多于k 解题思路: 总共只有\(A C G T\)四个字符,那么我们可以按照各个字符进行匹配,比如按照\(A\)进行匹 ...
- Nodejs实战系列:数据加密与crypto模块
博客地址:<NodeJS模块研究 - crypto> Github :https://github.com/dongyuanxin/blog nodejs 中的 crypto 模块提供了各 ...
- 深入源码解析spring aop实现的三个过程
Spring AOP的面向切面编程,是面向对象编程的一种补充,用于处理系统中分布的各个模块的横切关注点,比如说事务管理.日志.缓存等.它是使用动态代理实现的,在内存中临时为方法生成一个AOP对象,这个 ...
- OpenCV3入门(二)Mat操作
1.Mat结构 1.1.Mat数据 Mat本质上是由两个数据部分组成的类: 矩阵头:包含信息有矩阵的大小,用于存储的方法,矩阵存储的地址等 数据矩阵指针:指向包含了像素值的矩阵. 矩阵头部的大小是恒定 ...
- ATL的GUI程序设计(4)
第四章 对话框和控件 对于Win32 GUI的程序设计来说,其实大部分的情况下我们都不需要自己进行窗口类的设计,而是可以使用Win32中与用户交互的标准方式--对话框(Dialog Box).我们可以 ...