python中常用的九种数据预处理方法分享
Spyder Ctrl + 4/5: 块注释/块反注释
本文总结的是我们大家在python中常见的数据预处理方法,以下通过sklearn的preprocessing模块来介绍;
1. 标准化(Standardization or Mean Removal and Variance Scaling)
变换后各维特征有0均值,单位方差。也叫z-score规范化(零均值规范化)。计算方式是将特征值减去均值,除以标准差。
sklearn.preprocessing.scale(X)
一般会把train和test集放在一起做标准化,或者在train集上做标准化后,用同样的标准化器去标准化test集,此时可以用scaler
scaler = sklearn.preprocessing.StandardScaler().fit(train)
scaler.transform(train)
scaler.transform(test)
实际应用中,需要做特征标准化的常见情景:SVM
2. 最小-最大规范化
最小-最大规范化对原始数据进行线性变换,变换到[0,1]区间(也可以是其他固定最小最大值的区间)
min_max_scaler = sklearn.preprocessing.MinMaxScaler()
min_max_scaler.fit_transform(X_train)
或者
import numpy as np
a = np.random.random((2, 3, 3))
def customMinMaxScaler(X):
return (X - X.min()) / (X.max() - X.min())
np.array([customMinMaxScaler(x) for x in a]) 3.规范化(Normalization)
规范化是将不同变化范围的值映射到相同的固定范围,常见的是[0,1],此时也称为归一化。
将每个样本变换成unit norm。
X = [[ 1, -1, 2],[ 2, 0, 0], [ 0, 1, -1]]
sklearn.preprocessing.normalize(X, norm='l2')
得到:
array([[ 0.40, -0.40, 0.81], [ 1, 0, 0], [ 0, 0.70, -0.70]])
可以发现对于每一个样本都有,0.4^2+0.4^2+0.81^2=1,这就是L2 norm,变换后每个样本的各维特征的平方和为1。类似地,L1 norm则是变换后每个样本的各维特征的绝对值和为1。还有max norm,则是将每个样本的各维特征除以该样本各维特征的最大值。
在度量样本之间相似性时,如果使用的是二次型kernel,需要做Normalization
4. 特征二值化(Binarization)
给定阈值,将特征转换为0/1
binarizer = sklearn.preprocessing.Binarizer(threshold=1.1)
binarizer.transform(X)
5. 标签二值化(Label binarization)
lb = sklearn.preprocessing.LabelBinarizer()
6. 类别特征编码
有时候特征是类别型的,而一些算法的输入必须是数值型,此时需要对其编码。
enc = preprocessing.OneHotEncoder()
enc.fit([[0, 0, 3], [1, 1, 0], [0, 2, 1], [1, 0, 2]])
enc.transform([[0, 1, 3]]).toarray() #array([[ 1., 0., 0., 1., 0., 0., 0., 0., 1.]])
上面这个例子,第一维特征有两种值0和1,用两位去编码。第二维用三位,第三维用四位。
另一种编码方式
newdf=pd.get_dummies(df,columns=["gender","title"],dummy_na=True)
7.标签编码(Label encoding)
le = sklearn.preprocessing.LabelEncoder()
le.fit([1, 2, 2, 6])
le.transform([1, 1, 2, 6]) #array([0, 0, 1, 2])
#非数值型转化为数值型
le.fit(["paris", "paris", "tokyo", "amsterdam"])
le.transform(["tokyo", "tokyo", "paris"]) #array([2, 2, 1])
8.特征中含异常值时
sklearn.preprocessing.robust_scale
9.生成多项式特征
这个其实涉及到特征工程了,多项式特征/交叉特征。
poly = sklearn.preprocessing.PolynomialFeatures(2)
poly.fit_transform(X)
原始特征: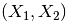
转化后: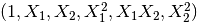
总结
以上就是为大家总结的python中常用的九种预处理方法分享,希望这篇文章对大家学习或者使用python能有一定的帮助,如果有疑问大家可以留言交流。
python中常用的九种数据预处理方法分享的更多相关文章
- python中常用的九种预处理方法
本文总结的是我们大家在python中常见的数据预处理方法,以下通过sklearn的preprocessing模块来介绍; 1. 标准化(Standardization or Mean Removal ...
- iOS中常用的四种数据持久化方法简介
iOS中常用的四种数据持久化方法简介 iOS中的数据持久化方式,基本上有以下四种:属性列表.对象归档.SQLite3和Core Data 1.属性列表涉及到的主要类:NSUserDefaults,一般 ...
- .NET中常用的几种解析JSON方法
一.基本概念 json是什么? JSON:JavaScript 对象表示法(JavaScript Object Notation). JSON 是一种轻量级的数据交换格式,是存储和交换文本信息的语法. ...
- Android中常用的五种数据存储方式
第一种: 使用SharedPreferences存储数据 适用范围: 保存少量的数据,且这些数据的格式非常简单:字符串型.基本类型的值.比如应用程序的各种配置信息(如是否打开音效.是否使用震动效果.小 ...
- iOS中常用的四种数据持久化技术
iOS中的数据持久化方式,基本上有以下四种:属性列表 对象归档 SQLite3和Core Data 1.属性列表涉及到的主要类:NSUserDefaults,一般 [NSUserDefaults st ...
- JavaScript中常用的几种类型检测方法
javascript中类型检测方法有很多: typeof instanceof Object.prototype.toString constructor duck type 1.typeof 最常见 ...
- iPhone开发 数据持久化总结(终结篇)—5种数据持久化方法对比
iPhone开发 数据持久化总结(终结篇)—5种数据持久化方法对比 iphoneiPhoneIPhoneIPHONEIphone数据持久化 对比总结 本篇对IOS中常用的5种数据持久化方法进行简单 ...
- 【转载】Python编程中常用的12种基础知识总结
Python编程中常用的12种基础知识总结:正则表达式替换,遍历目录方法,列表按列排序.去重,字典排序,字典.列表.字符串互转,时间对象操作,命令行参数解析(getopt),print 格式化输出,进 ...
- Python编程中常用的12种基础知识总结
原地址:http://blog.jobbole.com/48541/ Python编程中常用的12种基础知识总结:正则表达式替换,遍历目录方法,列表按列排序.去重,字典排序,字典.列表.字符串互转,时 ...
随机推荐
- metamask中的import account的代码实现
metamask-extension/app/scripts/account-import-strategies/index.js 这部分就是用户如果往metamask中import一个已有的账户调用 ...
- Bug 14143011 : ORA-19606: CANNOT COPY OR RESTORE TO SNAPSHOT CONTROL FILE
Bug 14143011 : ORA-19606: CANNOT COPY OR RESTORE TO SNAPSHOT CONTROL FILE [oracle@test]$ tail -f rma ...
- linux外接显示屏,关掉本身的笔记本电脑
https://blog.csdn.net/a2020883119/article/details/79561035 先用xrandr命令查看: eDP-1 connected eDP-1是连接着的 ...
- P2731 骑马修栅栏 欧拉函数
题目背景 Farmer John每年有很多栅栏要修理.他总是骑着马穿过每一个栅栏并修复它破损的地方. 题目描述 John是一个与其他农民一样懒的人.他讨厌骑马,因此从来不两次经过一个栅栏.你必须编一个 ...
- matlab fspecial
Matlab 的fspecial函数用法 fspecial函数用于建立预定义的滤波算子,其语法格式为:h = fspecial(type)h = fspecial(type,para)其中type指定 ...
- Gazebo仿真
1.建议在本地Ubuntu 16.04下运行仿真程序.目前Gazebo模拟器的兼容性是一大问题,在虚拟机或配置较低的电脑上可能无法运行.如果你的显卡是N卡,建议安装Ubuntu下的显卡驱动. 2.运行 ...
- Vue组件基础
<!DOCTYPE html><html> <head> <meta charset="utf-8"> ...
- VS2017上执行VS2013项目错误MSB802之解决方案
进行想把我编写的数字图像处理软件MagicHouse更新到最新的VS2017开发环境下,原来的开发环境是VS2013.但是用VS2017打开项目并编译时,系统报错误MSB802,如下图所示. 其实Vi ...
- Log4j2使用笔记
log4j2是log4j的最新版,现在已经有很多公司在使用了.log4j2和log4j的优缺点对比,请自行百度. 上一篇笔记讲了关于log4j的使用.这篇笔记主要讲解log4 ...
- 【php增删改查实例】第二十一节 - 用户修改功能
19.1 添加用户修改的按钮 打开userManage.html,找到新增按钮的地方: 我们不难发现,编辑按钮就差不多应该在新建用户的右边. 那么,假如我现在是新人,对这个项目本身就不太熟悉,那么我得 ...