python3--网络爬虫--爬取图片
网上大多爬虫仍旧是python2的urllib2写的,不过,坚持用python3(3.5以上版本可以使用异步I/O)
相信有不少人爬虫第一次爬的是Mm图,网上很多爬虫的视频教程也是爬mm图,看了某人的视频后,把这个爬虫给完成了
因为爬取的内容涉及个人隐私,所以,爬取的代码及网址不在此公布,不过介绍一下爬取的经验:
1.我们首先得了解我们要爬取的是什么,在哪爬取这些信息,不要着急想用什么工具,怎么搞,怎么搞得
2.手动操作一遍爬虫要完成的任务,我这个就是爬图片的,可以自己操作一遍
3.打开抓包软件或者Google的F12调试工具,查看数据,了解请求过程中的信息,如网址,发送请求的数据
大概了解以上信息后,可以开始编写爬虫了(个人经验,大牛勿喷,,,)
介绍python3用于爬虫的模块及方法:
可以查看官方的API文档,看懂文档,下面的就不用看了
urllib包:在python2中urllib和urllib2是分开的,python3合并在了一起,强调,这是个包,所以很多函数不一样了,但是还是那个味道
urllib.requestfor opening and reading URLsurllib.errorcontaining the exceptions raised byurllib.requesturllib.parsefor parsing URLsurllib.robotparserfor parsingrobots.txtfiles
这四个模块中urllib.request是常用的,urllib.parse中urlencode()也是会用到的
在urllib.request中,常用的方法:
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
class urllib.request.Request(url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)
headers参数,如果不想很容易被服务器发现,那么最起码加个user-agent吧,当然,你可以设置代理ip
urllib.parse.urlencode(query, doseq=False, safe='', encoding=None, errors=None, quote_via=quote_plus)
将请求发送的data字典转化为str,经过编码,data成了(get请求不用)
在爬取的过程中,正则表达式一定会用到,推荐一款软件:MTracer,可以自己尝试写正则: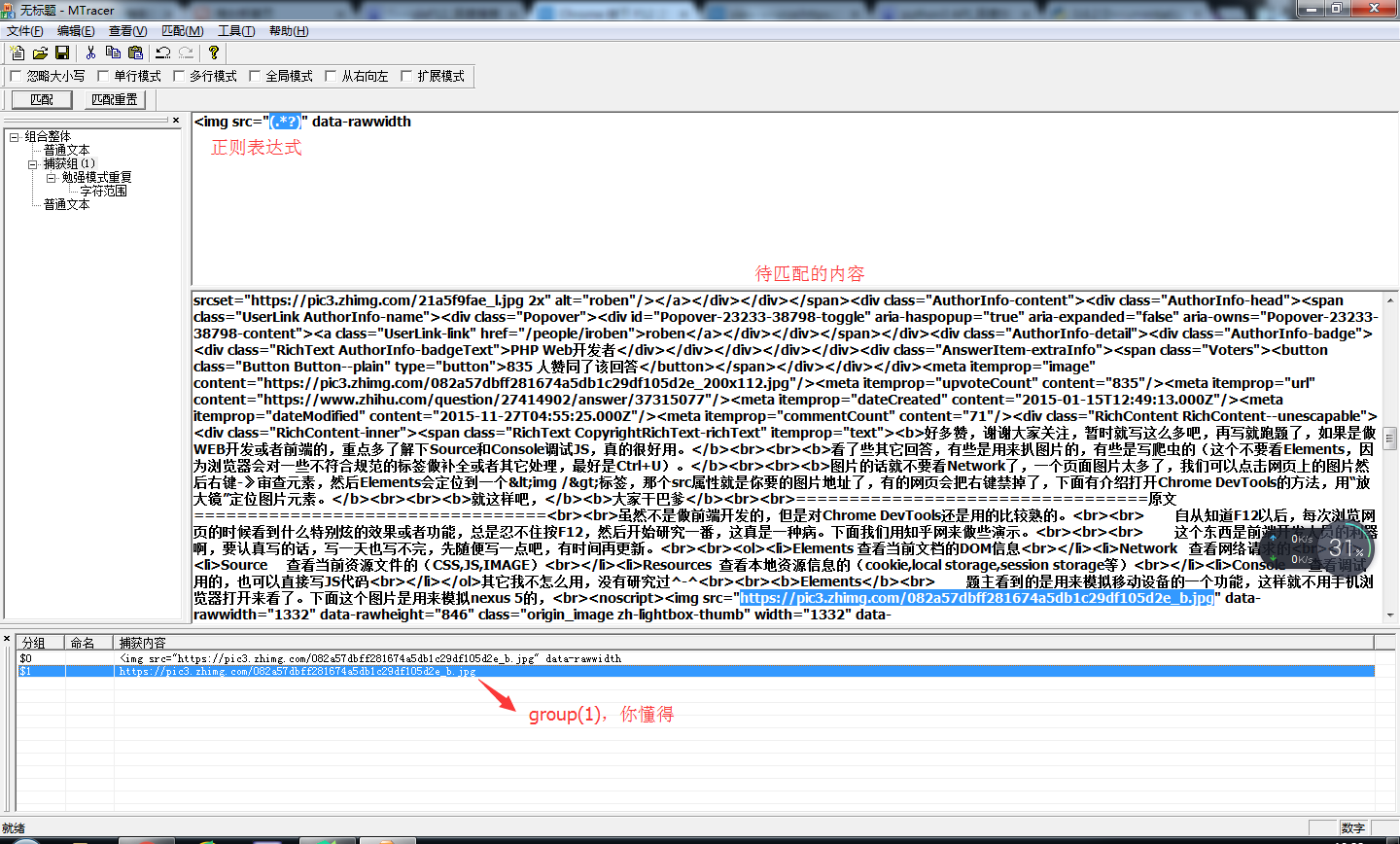
还是很不错的,谁爬谁知道
python3--网络爬虫--爬取图片的更多相关文章
- python网络爬虫&&爬取图片
爬取学院官网数据from urllib.request import * #导入所有request urllib文件夹,request只是里面的一个模块from lxml import etree # ...
- Python3 网络爬虫(请求库的安装)
Python3 网络爬虫(请求库的安装) 爬虫可以简单分为几步:抓取页面,分析页面和存储数据 在页面爬取的过程中我们需要模拟浏览器向服务器发送请求,所以需要用到一些python库来实现HTTP的请求操 ...
- 崔庆才Python3网络爬虫开发实战电子版书籍分享
资料下载地址: 链接:https://pan.baidu.com/s/1WV-_XHZvYIedsC1GJ1hOtw 提取码:4o94 <崔庆才Python3网络爬虫开发实战>高清中文版P ...
- Python3网络爬虫开发实战PDF高清完整版免费下载|百度云盘
百度云盘:Python3网络爬虫开发实战高清完整版免费下载 提取码:d03u 内容简介 本书介绍了如何利用Python 3开发网络爬虫,书中首先介绍了环境配置和基础知识,然后讨论了urllib.req ...
- 如何利用Python网络爬虫爬取微信朋友圈动态--附代码(下)
前天给大家分享了如何利用Python网络爬虫爬取微信朋友圈数据的上篇(理论篇),今天给大家分享一下代码实现(实战篇),接着上篇往下继续深入. 一.代码实现 1.修改Scrapy项目中的items.py ...
- 利用Python网络爬虫爬取学校官网十条标题
利用Python网络爬虫爬取学校官网十条标题 案例代码: # __author : "J" # date : 2018-03-06 # 导入需要用到的库文件 import urll ...
- 《Python3 网络爬虫开发实战》开发环境配置过程中踩过的坑
<Python3 网络爬虫开发实战>学习资料:https://www.cnblogs.com/waiwai14/p/11698175.html 如何从墙内下载Android Studio: ...
- 《Python3 网络爬虫开发实战》学习资料
<Python3 网络爬虫开发实战> 学习资料 百度网盘:https://pan.baidu.com/s/1PisddjC9e60TXlCFMgVjrQ
- 转:【Python3网络爬虫开发实战】 requests基本用法
1. 准备工作 在开始之前,请确保已经正确安装好了requests库.如果没有安装,可以参考1.2.1节安装. 2. 实例引入 urllib库中的urlopen()方法实际上是以GET方式请求网页,而 ...
- Python3网络爬虫(四):使用User Agent和代理IP隐藏身份《转》
https://blog.csdn.net/c406495762/article/details/60137956 运行平台:Windows Python版本:Python3.x IDE:Sublim ...
随机推荐
- grid栅格布局
前面的话 Grid布局方式借鉴了平面装帧设计中的格线系统,将格线运用在屏幕上,而不再是单一的静态页面,可以称之为真正的栅格.本文将详细介绍grid布局 引入 对于Web开发者来说,网页布局一直是个比较 ...
- hibernate查询部分字段转换成实体bean
//hibernate查询部分字段转换成实体bean /** * 查询线路信息 */ @Override public List<Line> getSimpleLineListByTj(M ...
- 基于Java SE的模拟双色球彩票系统
1.双色球规则: ①双色球分为红球和蓝球,红球选择的范围为1-33,而且红球选择6个数字:蓝球选择的范围为1-16,而且只能选择1个数字. ②选择方式为随机选择号码和手动输入选择号码. ③生成号码的顺 ...
- 如何维持App拥护登录状态(仅仅理论)
这个问题太过于常见,也过于简单,以至于大部分开发者根本没有关注过这个问题,我根据和我沟通的开发者中,总结出来常用的方法有以下几种: 一:服务端默认的session 这种方式最大的优点是服务端不用增加任 ...
- 矩阵的f范数及其求偏导法则
转载自: http://blog.csdn.net/txwh0820/article/details/46392293 矩阵的迹求导法则 1. 复杂矩阵问题求导方法:可以从小到大,从scalar到 ...
- JAVA基础——变量和常量
JAVA的变量和常量知识总结 一.认识java标识符 标识符就是用于给 Java 程序中变量.类.方法等命名的符号. 使用标识符时,需要遵守几条规则: 1. 标识符可以由字母.数字.下划线(_).美 ...
- Thrift总结(二)创建RPC服务
前面介绍了thrift 基础的东西,怎么写thrift 语法规范编写脚本,如何生成相关的语言的接口.不清楚的可以看这个<Thrift总结(一)介绍>.做好之前的准备工作以后,下面就开始如何 ...
- 青出于蓝而胜于蓝 — Vue.js对Angular.js的那些进步
Angular.js与Vue.js是非常有渊源的两款前端框架,据Vue.js的官方网站描述,在其早期开发时,灵感来源就是Angular.js.而在很多方面,Vue.js也正像是中国的那句古话,&quo ...
- JVM总结之GC
哪些内存需要回收 在Java堆中存放着几乎所有的对象实例,垃圾收集器在对堆进行回收前,第一件事情就是要知道哪些对象还"存活着",哪些对象已经"死去". 引用计数 ...
- dynamic-load-apk 插件与宿主方法互调
新建项目 DlPluginHost,下载dynamic-load-apk源码 1.将dynamic-load-apk 文件夹中的lib做为module导入到DlPlginHost 2.导入到Plugi ...