Zookeeper简介与集群搭建【转】
Zookeeper简介
Zookeeper是一个高效的分布式协调服务,可以提供配置信息管理、命名、分布式同步、集群管理、数据库切换等服务。它不适合用来存储大量信息,可以用来存储一些配置、发布与订阅等少量信息。Hadoop、Storm、消息中间件、RPC服务框架、分布式数据库同步系统,这些都是Zookeeper的应用场景。
Zookeeper集群中节点个数一般为奇数个(>=3),若集群中Master挂掉,剩余节点个数在半数以上时,就可以推举新的主节点,继续对外提供服务。
客户端发起事务请求,事务请求的结果在整个Zookeeper集群中所有机器上的应用情况是一致的。不会出现集群中部分机器应用了该事务,而存在另外一部分集群中机器没有应用该事务的情况。在Zookeeper集群中的任何一台机器,其看到的服务器的数据模型是一致的。Zookeeper能够保证客户端请求的顺序,每个请求分配一个全局唯一的递增编号,用来反映事务操作的先后顺序。Zookeeper将全量数据保存在内存中,并直接服务于所有的非事务请求,在以读操作为主的场景中性能非常突出。
Zookeeper使用的数据结构为树形结构,根节点为"/"。Zookeeper集群中的节点,根据其身份特性分为leader、follower、observer。leader负责客户端writer类型的请求;follower负责客户端reader类型的请求,并参与leader选举;observer是特殊的follower,可以接收客户端reader请求,但是不会参与选举,可以用来扩容系统支撑能力,提高读取速度。
Zookeeper是一个基于观察者模式设计的分布式服务管理框架,负责存储和管理相关数据,接收观察者的注册。一旦这些数据的状态发生变化,zookeeper就负责通知那些已经在zookeeper集群进行注册并关心这些状态发生变化的观察者,以便观察者执行相关操作。
Zookeeper使用的是ZAB原子消息广播协议,节点之间的一致性算法为Paxos,能够保障分布式环境中数据的一致性。分布式场景下高可用是Zookeeper的特性,可以采用第三方客户端的实现,即Curator框架。
memory)和消息传递(Messages passing)。Paxos 算法就是一种基于消息传递模型的一致性算法。
Zookeeper集群搭建
在本文中Zookeeper节点个数(奇数)为3个。Zookeeper默认对外提供服务的端口号2181 。Zookeeper集群内部3个节点之间通信默认使用2888:3888
192.168.0.217 192.168.0.218 192.168.0.219
下载zookeeper对应的tar包
分别上传tar包到192.168.0.217
192.168.0.218 192.168.0.219
在217、218、219三个zookeeper节点上分别执行下行指令,然后将解压后的文件名zookeeper-3.4.10修改为zookeeper。
tar -zxvf zookeeper-3.4.10.tar.gz -C /usr/local/
在三个zookeeper节点配置环境变量
vim /etc/profile
添加export ZOOKEEPER_HOME=/usr/local/zookeeper
在path中添加$ZOOKEEPER_HOME/bin
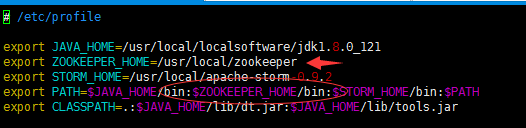
执行source /etc/profile 使环境变量立即生效
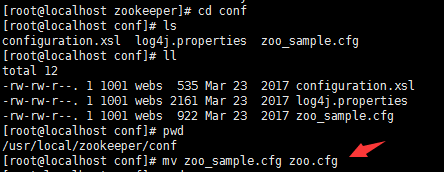
修改zookeeper中conf目录下的zoo_sample.cfg为zoo.cfg
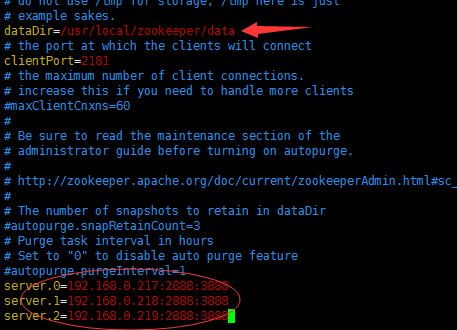
修改三个zookeeper节点中的zoo.cfg文件,修改dataDir,添加server.0、server.1、server.2
在zookeeper目录下,创建data目录。在3个zookeeper节点中data目录下分别创建myid文件,并分别添加内容0、1、2



启动zookeeper
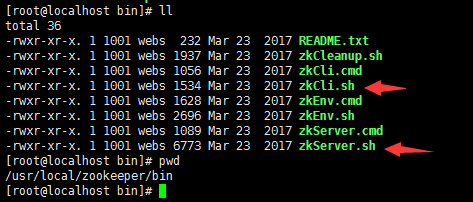
zkServer.sh start
zkServer.sh status
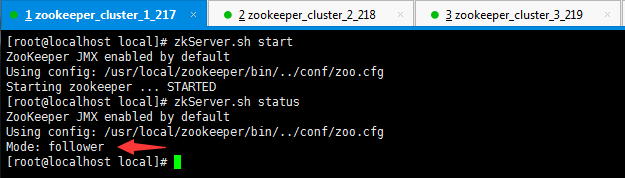
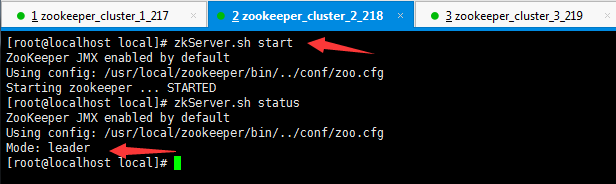
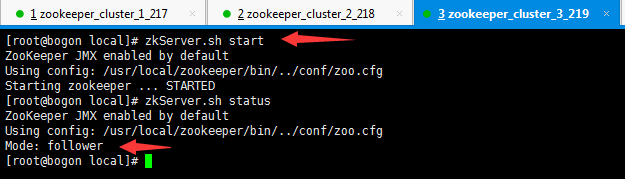
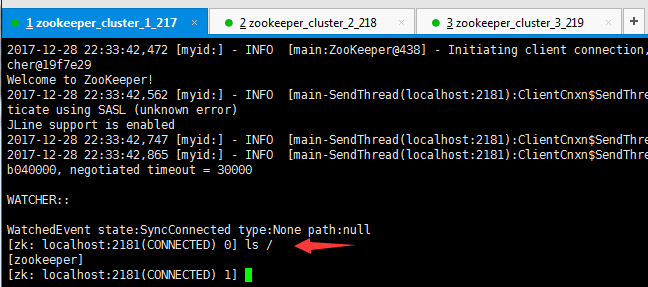
在zookeeper中任意一个节点,执行指令zkCli.sh
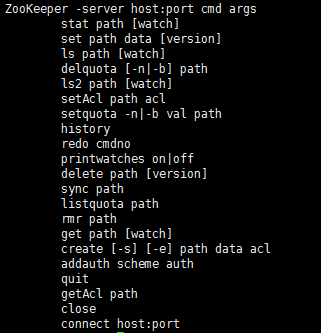
执行指令zkCli.sh help ,查看帮助信息
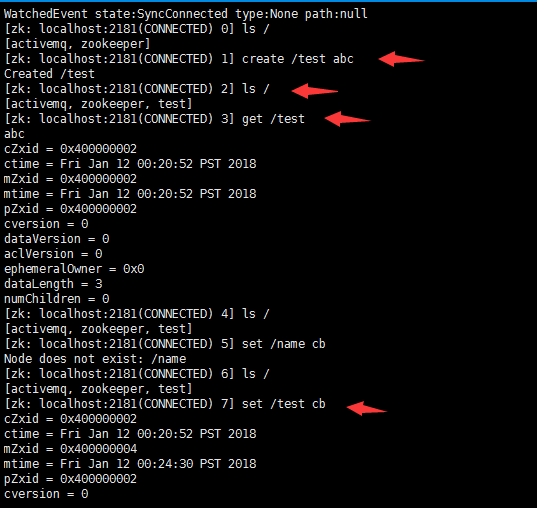
ls / 查找根目录
create /test abc 创建节点并赋值
get /test 获取指定节点的值
set /test cb 设置已存在节点的值
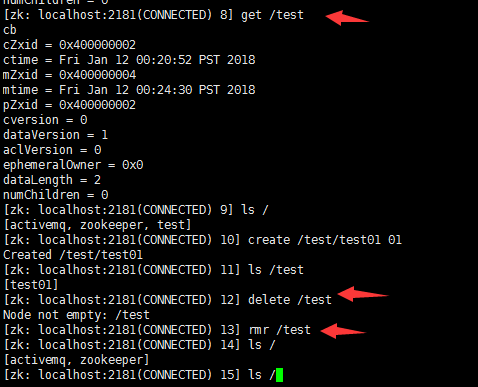
rmr /test 递归删除节点
delete /test/test01 删除不存在子节点的节点
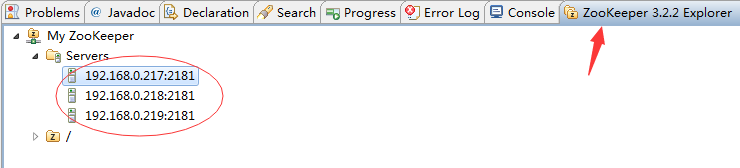
在Eclipse中查看Zookeeper集群节点
也可以使用ZooInspector查看。

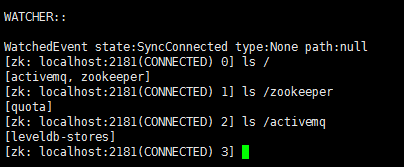
此时,在Xshell中执行zkCli.sh,查看Zookeeper集群中树形结构的内容
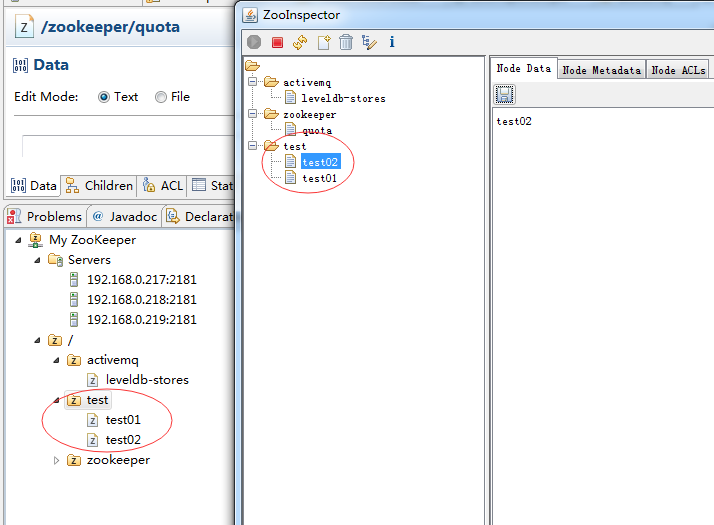
在Eclipse、ZooInspector中均可以添加、删除Zookeeper集群的节点
转自
Zookeeper简介与集群搭建 - CSDN博客 https://blog.csdn.net/qiushisoftware/article/details/79043379
Zookeeper简介与集群搭建【转】的更多相关文章
- Zookeeper简介与集群搭建
Zookeeper简介 Zookeeper是一个高效的分布式协调服务,可以提供配置信息管理.命名.分布式同步.集群管理.数据库切换等服务.它不适合用来存储大量信息,可以用来存储一些配置.发布与订阅等少 ...
- 基于zookeeper的Swarm集群搭建
简介 Swarm:docker原生的集群管理工具,将一组docker主机作为一个虚拟的docker主机来管理. 对客户端而言,Swarm集群就像是另一台普通的docker主机. Swarm集群中的每台 ...
- zookeeper及kafka集群搭建
zookeeper及kafka集群搭建 1.有关zookeeper的介绍可参考:http://www.cnblogs.com/wuxl360/p/5817471.html 2.zookeeper安装 ...
- 【运维技术】Zookeeper单机以及集群搭建教程
Zookeeper单机以及集群搭建教程 单机搭建 单机安装以及启动 安装zookeeper的前提是必须有java环境 # 选择目录进行下载安装 cd /app # 下载zk,可以去官方网站下载,自己上 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- zookeeper高可用集群搭建
前提:已经在master01配置好hadoop:在各个slave节点配置好hadoop和zookeeper: (该文是将zookeeper配置在各slave节点上的,其实也可以配置在各master上, ...
- HADOOP+SPARK+ZOOKEEPER+HBASE+HIVE集群搭建(转)
原文地址:https://www.cnblogs.com/hanzhi/articles/8794984.html 目录 引言 目录 一环境选择 1集群机器安装图 2配置说明 3下载地址 二集群的相关 ...
- zookeeper 高可用集群搭建
前言 记录Zookeeper集群搭建的过程! 什么是 Zookeeper ? ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hado ...
- zookeeper安装与集群搭建
此处以centos系统下zookeeper安装为例,详细步骤可参考官网文档:zookeeper教程 一.单节点部署 1.下载zookeeper wget http://mirrors.hust.edu ...
随机推荐
- linux 分区、目录及用途
主要分区: 目录 建议大小 格式 描述 / 10G-20G ext4 根目录 swap <2048M swap 交换空间 /boot 200M左右 ext4 Linux的内核及引导系统程序所需要 ...
- 超越LLMNR /NBNS欺骗 - 利用Active Directory集成的DNS
利用名称解析协议中的缺陷进行内网渗透是执行中间人(MITM)攻击的常用技术.有两个特别容易受到攻击的名称解析协议分别是链路本地多播名称解析(LLMNR)和NetBIOS名称服务(NBNS).攻击者可以 ...
- Elasticsearch利用cat api快速查看集群状态、内存、磁盘使用情况
使用场景 当Elasticsearch集群中有节点挂掉,我们可以去查看集群的日志信息查找错误,不过在查找错误日志之前,我们可以通过elasticsearch的cat api简单判断下各个节点的状态,包 ...
- Logstash解析Json array
logstash解析json数组是一种常见的需求,我以网上一组数据为例来描述 我们的数据test.json内容如下:(此处我linux上的json文本需要是compact的) {"type& ...
- 【POJ3694】Network
题目大意:给定一个 N 个点,M 条边的无向图,支持 Q 次操作,每次可以向该无向图中加入一条边,并需要回答当前无向图中桥的个数. 题解:(暴力:Q 次 Tarjan) 先进行一次 Tarjan 求出 ...
- spring 项目分开发和生产环境
1.pom 文件修改 <profile> <!-- 本地开发环境 --> <id>dev</id> <properties> <pro ...
- HTTP协议和SOCKS5协议
HTTP协议和SOCKS5协议 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 我们平时上网的时候基本上是离不开浏览器的,尤其是搜索资料的时候,那么这个浏览器是如何工作的呢?用的又是 ...
- android allowbackup
allowbackup 属性是在application 节点下,作用的设置为true,人们可以通过adb 命令备份一份应用的信息,然后在另外一个设备上,还原这份信息,是一种危险操作,所以,我们一般设为 ...
- 插入排序算法的JAVA实现
1,对元素进行排列时,元素之间需要进行比较,因此需要实现Comparable<T>接口.即,<T extends Comparable<T>>. 更进一步,如果允许 ...
- 解决从本地文件系统上传到HDFS时的权限问题
当使用 hadoop fs -put localfile /user/xxx 时提示: put: Permission denied: user=root, access=WRITE, inode=& ...