Spark是什么
官方直达电梯
Spark一种基于内存的通用的实时大数据计算框架(作为MapReduce的另一个更优秀的可选的方案)
- 通用:Spark Core 用于离线计算,Spark SQL 用于交互式查询,Spark Streaming 用于实时流式计算,Spark Mlib 用于机器学习,Spark GraphX 用于图计算
- 实时:Run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk.
一、Spark和Storm的区别
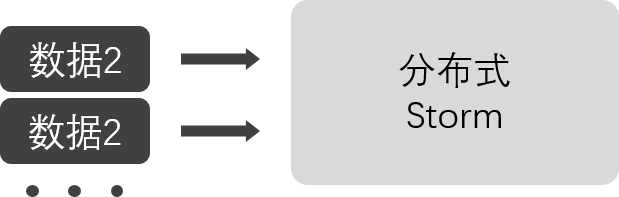
Storm的计算模型(实时)
- Storm是针对每条数据的流式实时计算框架,由于每条数据过来就直接处理,每条数据都会带来大量的资源消耗(传输,通信,校验等)吞吐量不高
- storm可以动态调整并行度
- Storm保证了更高的实时性,毫秒级延迟
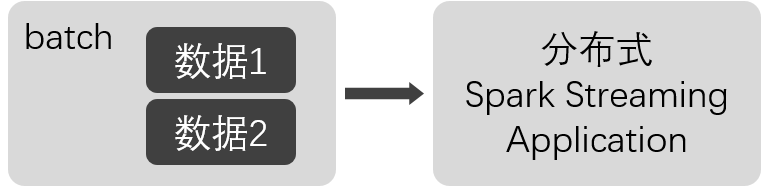
Spark Stream计算模型(准实时)
- 通过设置时间间隔 batch interval 一个时间间隔内的数据作为一个Batch收集起来给Spark Streaming Application处理(少了很多传输,校对开销),保证了高吞吐量
- 秒级延迟
- 结合Spark生态圈可以发挥很大的威力
二、Spark Streaming和MapReduce的对比
Shuffle以及MapReduce的计算模型决定了MapReduce只适合对速度要求不敏感的离线批处理任务
- Spark的多进程任务可能在同一个物理机器的内存上完成(Spark shuffle也会使用磁盘)
- MapReduce死板的模型必须基于磁盘和大量的网络传输
- MapReduce的程度编写复杂,Spark更容易上手,支持(Scale JAVA[8支持函数式编程] Python)
- Spark 在缺少调优时,会出现OOM(Out Of Memory)的问题,导致程序无法执行,而MapReduce就算是慢也能执行

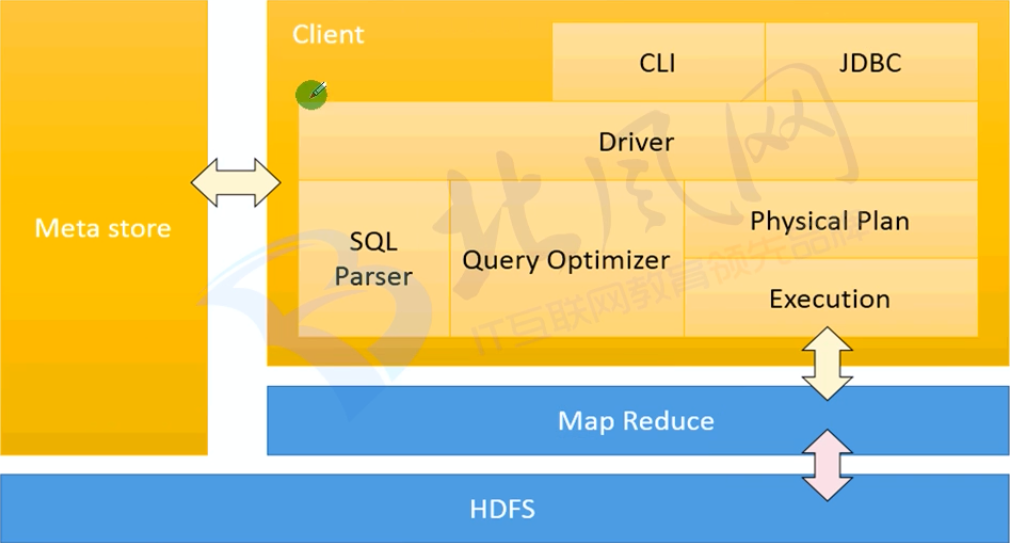
三、Spark SQL对比Hive
- Spark SQL实际上不能完全替代Hive,只是替代了Hive中的查询引擎,针对Hive数据仓库中的表进行SQL查询
- 由于Hive查询底层基于MapReduce决定了Hive的查询慢
- Hive中的一部分高级特性在Spark SQL 中未得到支持
- Spark SQL除了Hive还支持其他数据源(json parquet jdbc等),同时支持直接针对HDFS执行SQL查询
Spark是什么的更多相关文章
- Spark踩坑记——Spark Streaming+Kafka
[TOC] 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark strea ...
- Spark RDD 核心总结
摘要: 1.RDD的五大属性 1.1 partitions(分区) 1.2 partitioner(分区方法) 1.3 dependencies(依赖关系) 1.4 compute(获取分区迭代列表) ...
- spark处理大规模语料库统计词汇
最近迷上了spark,写一个专门处理语料库生成词库的项目拿来练练手, github地址:https://github.com/LiuRoy/spark_splitter.代码实现参考wordmaker ...
- Hive on Spark安装配置详解(都是坑啊)
个人主页:http://www.linbingdong.com 简书地址:http://www.jianshu.com/p/a7f75b868568 简介 本文主要记录如何安装配置Hive on Sp ...
- Spark踩坑记——数据库(Hbase+Mysql)
[TOC] 前言 在使用Spark Streaming的过程中对于计算产生结果的进行持久化时,我们往往需要操作数据库,去统计或者改变一些值.最近一个实时消费者处理任务,在使用spark streami ...
- Spark踩坑记——初试
[TOC] Spark简介 整体认识 Apache Spark是一个围绕速度.易用性和复杂分析构建的大数据处理框架.最初在2009年由加州大学伯克利分校的AMPLab开发,并于2010年成为Apach ...
- Spark读写Hbase的二种方式对比
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处 一.传统方式 这种方式就是常用的TableInputFormat和TableOutputForm ...
- (资源整理)带你入门Spark
一.Spark简介: 以下是百度百科对Spark的介绍: Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方 ...
- Spark的StandAlone模式原理和安装、Spark-on-YARN的理解
Spark是一个内存迭代式运算框架,通过RDD来描述数据从哪里来,数据用那个算子计算,计算完的数据保存到哪里,RDD之间的依赖关系.他只是一个运算框架,和storm一样只做运算,不做存储. Spark ...
- (一)Spark简介-Java&Python版Spark
Spark简介 视频教程: 1.优酷 2.YouTube 简介: Spark是加州大学伯克利分校AMP实验室,开发的通用内存并行计算框架.Spark在2013年6月进入Apache成为孵化项目,8个月 ...
随机推荐
- nautilus命令
nautilus 是图形程式效果是以当前用户打开图形界面所以如果想以root打开图形界面使用时记得先切为root,sudo没有用的
- bzoj3816 矩阵变换
Description 给出一个 N 行 M 列的矩阵A, 保证满足以下性质: M>N. 矩阵中每个数都是 [0,N] 中的自然数. 每行中, [1,N] 中每个自然数都恰好出现一次.这意味着每 ...
- UVa 1606 - Amphiphilic Carbon Molecules
链接: https://uva.onlinejudge.org/index.php?option=com_onlinejudge&Itemid=8&page=show_problem& ...
- Uva 12298 超级扑克2
题目链接:https://vjudge.net/problem/UVA-12298 题意: 1.超级扑克,每种花色有无数张牌,但是,这些牌都是合数:比如黑桃:4,6,8,9,10,,,, 2.现在拿走 ...
- 记一次pda(安卓)环境配置流程
将git项目git clone下来,接下来就是环境的配置 sdk,jdk,蓝牙插件,热更新 这个顺序 一.java JDK 安装及环境变量配置 https://blog.csdn.net/de ...
- POJ1990 MooFest
嘟嘟嘟 题目大意:一群牛参加完牛的节日后都有了不同程度的耳聋(汗……),第i头牛听见别人的讲话,别人的音量必须大于v[i],当两头牛i,j交流的时候,交流的最小声音为max{v[i],v[j]}*他们 ...
- 转载 【MySql】Update批量更新与批量更新多条记录的不同值实现方法
批量更新 mysql更新语句很简单,更新一条数据的某个字段,一般这样写: UPDATE mytable SET myfield = 'value' WHERE other_field = 'other ...
- 【luogu P1962 斐波那契数列】 题解
题目链接:https://www.luogu.org/problemnew/show/P1962 给你篇dalao的blog自己看吧,把矩阵快速幂的板子一改就OK #include <algor ...
- Android学习笔记_10_ContentProvider内容提供者的使用
一.使用ContentProvider共享数据 当应用继承ContentProvider类,并重写该类用于提供数据和存储数据的方法,就可以向其他应用共享其数据.以前我们学习过文件的操作模式,通过指定文 ...
- Retain NULL values vs Keep NULLs in SSIS Dataflows - Which To Use? (转载)
There is some confusion as to what the various NULL settings all do in SSIS. In fact in one team whe ...