Python写爬虫爬妹子
1.下载数据

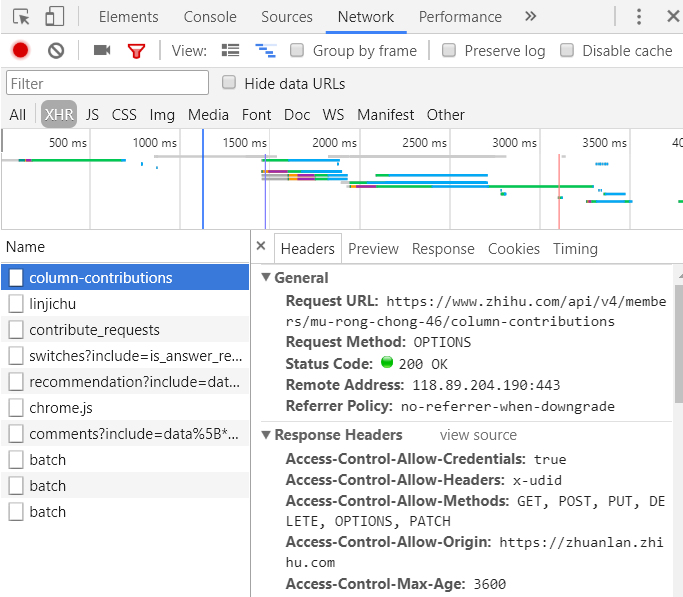
有的网站做了反爬的处理,可以添加User-Agent :判断浏览器
self.user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
# 初始化 headers
self.headers = {'User-Agent': self.user_agent}
如果不行,在Chrome上按F12分析请求头、请求体,看需不需要添加别的信息,例如有的网址添加了referer:记住当前网页的来源,那么我们在请求的时候就可以带上。按Ctrl + Shift + C,可以定位元素在HTML上的位置
动态网页
下载数据的模块有urllib、urllib2及Requests
html = requests.get(url, headers=headers) #没错,就是这么简单
urllib2以我爬取淘宝的妹子例子来说明:
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = {'User-Agent': user_agent}
# 注意:form data请求参数
params = 'q&viewFlag=A&sortType=default&searchStyle=&searchRegion=city%3A&searchFansNum=¤tPage=1&pageSize=100' def getHome():
url = 'https://mm.taobao.com/tstar/search/tstar_model.do?_input_charset=utf-8'
req = urllib2.Request(url, headers=headers)
# decode(’utf - 8’)解码 把其他编码转换成unicode编码
# encode(’gbk’) 编码 把unicode编码转换成其他编码
# ”gbk”.decode(’gbk’).encode(’utf - 8')
# unicode = 中文
# gbk = 英文
# utf - 8 = 日文
# 英文一 > 中文一 > 日文,unicode相当于转化器
html = urllib2.urlopen(req, data=params).read().decode('gbk').encode('utf-8')
# json转对象
peoples = json.loads(html)
for i in peoples['data']['searchDOList']:
#去下一个页面获取数据
getUseInfo(i['userId'], i['realName'])
2.解析数据
def getUseInfo(userId, realName):
url = 'https://mm.taobao.com/self/aiShow.htm?userId=' + str(userId)
req = urllib2.Request(url)
html = urllib2.urlopen(req).read().decode('gbk').encode('utf-8') pattern = re.compile('<img.*?src=(.*?)/>', re.S)
items = re.findall(pattern, html)
x = 0
for item in items:
if re.match(r'.*(.jpg")$', item.strip()):
tt = 'http:' + re.split('"', item.strip())[1]
down_image(tt, x, realName)
x = x + 1
print('下载完毕')
正则表达式说明
search:在string中进行搜索,成功返回Match object, 失败返回None, 只匹配一个。
findall:在string中查找所有 匹配成功的组, 即用括号括起来的部分。返回list对象,每个list item是由每个匹配的所有组组成的list。
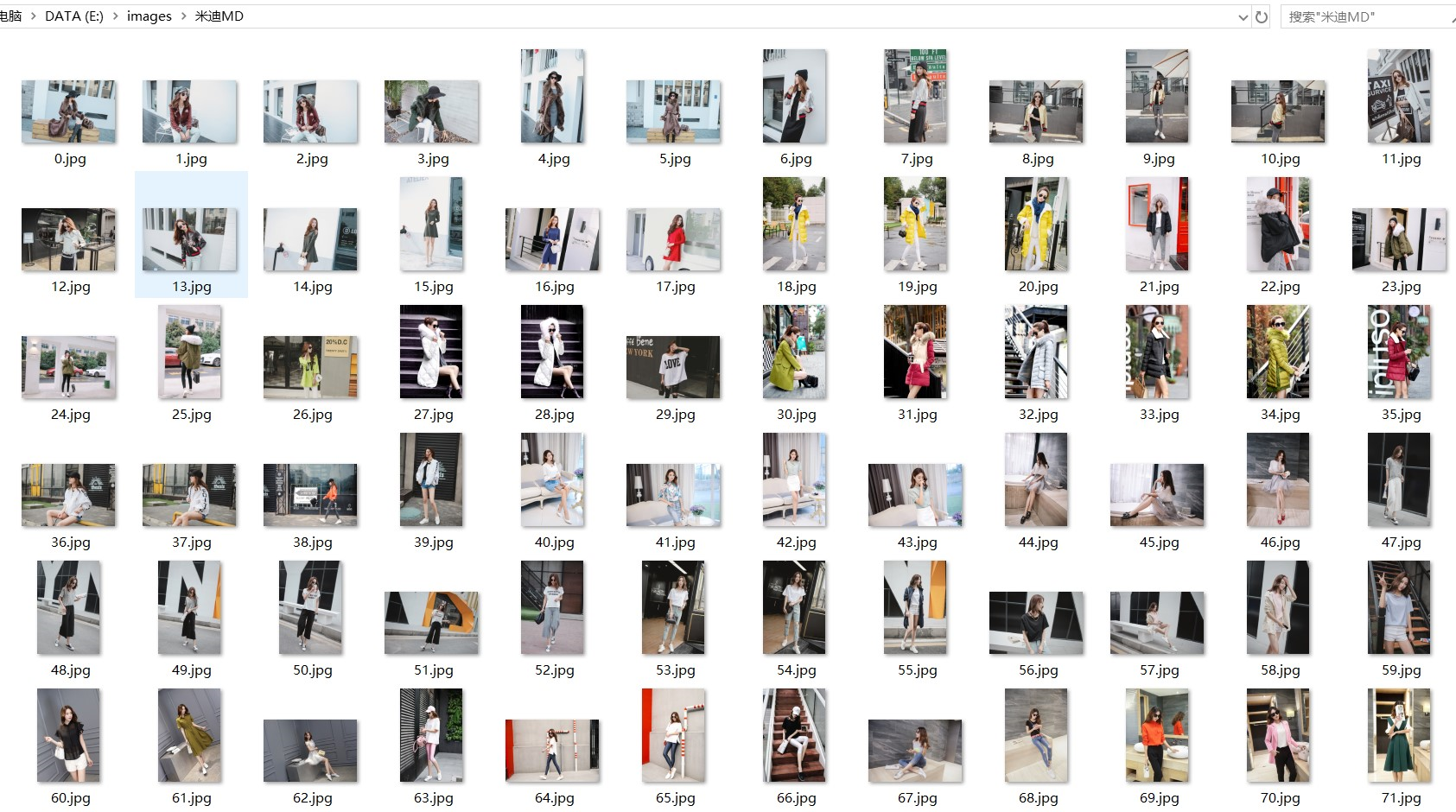
3.保存数据
def down_image(url, filename, realName):
req = urllib2.Request(url=url)
folder = 'e:\\images\\%s' % realName
if os.path.isdir(folder):
pass
else:
os.makedirs(folder) f = folder + '\\%s.jpg' % filename
if not os.path.isfile(f):
print f
binary_data = urllib2.urlopen(req).read()
with open(f, 'wb') as temp_file:
temp_file.write(binary_data)
GitHub地址,还有其他网站爬虫,欢迎star:https://github.com/peiniwan/Spider2
Python写爬虫爬妹子的更多相关文章
- Python写爬虫-爬甘农大学校新闻
Python写网络爬虫(一) 关于Python: 学过C. 学过C++. 最后还是学Java来吃饭. 一直在Java的小世界里混迹. 有句话说: "Life is short, you ne ...
- 用Python写爬虫爬取58同城二手交易数据
爬了14W数据,存入Mongodb,用Charts库展示统计结果,这里展示一个示意 模块1 获取分类url列表 from bs4 import BeautifulSoup import request ...
- python写爬虫时的编码问题解决方案
在使用Python写爬虫的时候,常常会遇到各种令人抓狂的编码错误问题.下面给出一些简单的解决编码错误问题的思路,希望对大家有所帮助. 首先,打开你要爬取的网站,右击查看源码,查看它指定的编码是什么,如 ...
- 如何利用Python网络爬虫爬取微信朋友圈动态--附代码(下)
前天给大家分享了如何利用Python网络爬虫爬取微信朋友圈数据的上篇(理论篇),今天给大家分享一下代码实现(实战篇),接着上篇往下继续深入. 一.代码实现 1.修改Scrapy项目中的items.py ...
- 利用Python网络爬虫爬取学校官网十条标题
利用Python网络爬虫爬取学校官网十条标题 案例代码: # __author : "J" # date : 2018-03-06 # 导入需要用到的库文件 import urll ...
- 《用Python写爬虫》学习笔记(一)
注:纯文本内容,代码独立另写,属于本人学习总结,无任何商业用途,在此分享,如有错误,还望指教. 1.为什么需要爬虫? 答:目前网络API未完全放开,所以需要网络爬虫知识. 2.爬虫的合法性? 答:爬虫 ...
- 怎么用Python写爬虫抓取网页数据
机器学习首先面临的一个问题就是准备数据,数据的来源大概有这么几种:公司积累数据,购买,交换,政府机构及企业公开的数据,通过爬虫从网上抓取.本篇介绍怎么写一个爬虫从网上抓取公开的数据. 很多语言都可以写 ...
- 开发记录_自学Python写爬虫程序爬取csdn个人博客信息
每天刷开csdn的博客,看到一整个页面,其实对我而言,我只想看看访问量有没有上涨而已... 于是萌生了一个想法: 想写一个爬虫程序把csdn博客上边的访问量和评论数都爬下来. 打算通过网络各种搜集资料 ...
- Python练习册 第 0013 题: 用 Python 写一个爬图片的程序,爬 这个链接里的日本妹子图片 :-),(http://tieba.baidu.com/p/2166231880)
这道题是一道爬虫练习题,需要爬链接http://tieba.baidu.com/p/2166231880里的所有妹子图片,点进链接看一下,这位妹子是日本著名性感女演员--杉本由美,^_^好漂亮啊,赶紧 ...
随机推荐
- Ubuntu 18.04 on Windows 10 更改 Oh-My-Zsh agnoster 主题下的目录背景色
题外话 我的 MacBook Pro 已经使用了6年多的时间,尽管作为一个 .NET 程序员绝大部分时间都是在 Windows 下工作,直到 .NET Core 的逐步成熟.要说 Mac OS,最满意 ...
- HttpMessageConverter 专题
配置HttpMessageConverterHttpMessageConverter是对http的request和response进行自动转换配置HttpMessageConverter可重载下面两个 ...
- scrapy顺序执行多个爬虫
# -*- coding:utf-8 -*- from scrapy import cmdline from scrapy.cmdline import execute import sys,time ...
- Guava新增集合类型-Multiset
Guava新增集合类型-Multiset Guava引进了JDK里没有的,但是非常有用的一些新的集合类型.所有这些新集合类型都能和JDK里的集合平滑集成.Guava集合非常精准地实现了JDK定义的接口 ...
- 如果裸写一个goroutine pool
引言 在上文中,我说到golang的原生http server处理client的connection的时候,每个connection起一个goroutine,这是一个相当粗暴的方法.为了感受更深一点, ...
- java equals和tostring
Object类概述 是所有类中的父类,最大的超类,所有的类都继承他. equals方法 比较2个对象是否相同,其实他是在比较两个对象的地址是否相同,在equals方法中我们用==来判断 但是比较2个地 ...
- 拯救莫莉斯 状压dp
题目大意:每个点有费用,要求选出花费最少的一些点,使得全部点都满足:他被选或与他相邻的任意点被选. 没看清数据范围233333 和翻格子游戏一样,考虑上中下三行,可行才能转移 f[i][j][k]表示 ...
- java.lang.NoSuchMethodError: org.springframework.boot.builder.SpringApplicationBuilder.<init>([Ljava
搭建spring cloud的时候,报以下错误: java.lang.NoSuchMethodError: org.springframework.boot.builder.SpringApplica ...
- 什么是语义化的HTML?为什么要做到语义化?
一.什么是语义化的HTML? 语义化的HTML就是写出的HTML代码,符合内容的结构化(内容语义化),选择合适的标签(代码语义化),能够便于开发者阅读和写出更优雅的代码的同时让浏览器的爬虫和机器很好地 ...
- 带logo图片或不带logo图片的二维码生成与解析,亲测成功
最近公司需要实现二维码功能,本人经过一顿百度,终于实现了,因有3个功能:不带logo图片.带logo图片.解析二维码,篇幅较长,请耐心读之,直接复制粘贴即可. 前提:myeclipse10:jar包: ...