spark分区数,task数目,core数,worker节点个数,excutor数量梳理
作者:王燚光
链接:https://www.zhihu.com/question/33270495/answer/93424104
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
梳理一下Spark中关于并发度涉及的几个概念File,Block,Split,Task,Partition,RDD以及节点数、Executor数、core数目的关系。
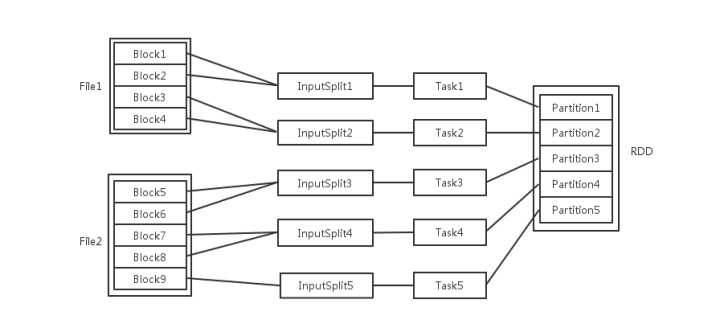
当Spark读取这些文件作为输入时,会根据具体数据格式对应的InputFormat进行解析,一般是将若干个Block合并成一个输入分片,称为InputSplit,注意InputSplit不能跨越文件。
随后将为这些输入分片生成具体的Task。InputSplit与Task是一一对应的关系。
随后这些具体的Task每个都会被分配到集群上的某个节点的某个Executor去执行。
- 每个节点可以起一个或多个Executor。
- 每个Executor由若干core组成,每个Executor的每个core一次只能执行一个Task。
- 每个Task执行的结果就是生成了目标RDD的一个partiton。
作者:王燚光
链接:https://www.zhihu.com/question/33270495/answer/93424104
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
spark分区数,task数目,core数,worker节点个数,excutor数量梳理的更多相关文章
- Spark使用CombineTextInputFormat缓解小文件过多导致Task数目过多的问题
目前平台使用Kafka + Flume的方式进行实时数据接入,Kafka中的数据由业务方负责写入,这些数据一部分由Spark Streaming进行流式计算:另一部分数据则经由Flume存储至HDFS ...
- Spark分区数、task数目、core数目、worker节点数目、executor数目梳理
Spark分区数.task数目.core数目.worker节点数目.executor数目梳理 spark隐式创建由操作组成的逻辑上的有向无环图.驱动器执行时,它会把这个逻辑图转换为物理执行计划,然后将 ...
- Spark中Task,Partition,RDD、节点数、Executor数、core数目的关系和Application,Driver,Job,Task,Stage理解
梳理一下Spark中关于并发度涉及的几个概念File,Block,Split,Task,Partition,RDD以及节点数.Executor数.core数目的关系. 输入可能以多个文件的形式存储在H ...
- Spark中Task,Partition,RDD、节点数、Executor数、core数目(线程池)、mem数
Spark中Task,Partition,RDD.节点数.Executor数.core数目的关系和Application,Driver,Job,Task,Stage理解 from:https://bl ...
- Spark中Task数量的分析
本文主要说一下Spark中Task相关概念.RDD计算时Task的数量.Spark Streaming计算时Task的数量. Task作为Spark作业执行的最小单位,Task的数量及运行快慢间接决定 ...
- SPARK如何使用AKKA实现进程、节点通信
SPARK如何使用AKKA实现进程.节点通信 <深入理解Spark:核心思想与源码分析>一书前言的内容请看链接<深入理解SPARK:核心思想与源码分析>一书正式出版上市 < ...
- Spark之Task原理分析
在Spark中,一个应用程序要想被执行,肯定要经过以下的步骤: 从这个路线得知,最终一个job是依赖于分布在集群不同节点中的task,通过并行或者并发的运行来完成真正的工作.由此可见 ...
- spark出现task不能序列化错误的解决方法
应用场景:使用JavaHiveContext执行SQL之后,希望能得到其字段名及相应的值,但却出现"Caused by: java.io.NotSerializableException: ...
- 如何优雅的维护 K8S Worker 节点
前言 正常维护工作节点的流程 当我们要进行 K8S 节点维护时往往需要执行 kubectl drain, 等待节点上的 Pod 被驱逐后再进行维护动作. 命令行如下: kubectl drain NO ...
随机推荐
- 1-1 struts2 基本配置 struts.xml配置文件详解
详见http://www.cnblogs.com/dooor/p/5323716.html 一. struts2工作原理(网友总结,千遍一律) 1 客户端初始化一个指向Servlet容器(例如Tomc ...
- 基于JavaMail向邮箱发送邮件
参考:http://blog.csdn.net/ghsau/article/details/17839983 http://blog.csdn.net/never_cxb/article/detail ...
- 使用 win10 的正确姿势
17年9月初,写了第一篇<使用 win10 的正确姿势>,而现在半年多过去,觉得文章得更新一些了,索性直接来个第二版吧. -----2018.3.24 写 一. 重新定义桌面 我的桌面: ...
- 二分查找(binary search)java实现及时间复杂度
概述 在一个已排序的数组seq中,使用二分查找v,假如这个数组的范围是[low...high],我们要的v就在这个范围里.查找的方法是拿low到high的正中间的值,我们假设是m,来跟v相比,如果m& ...
- Django之ORM基础
ORM简介 ORM概念 对象关系映射(Object Relational Mapping,简称ORM)模式是一种为了解决面向对象与关系数据库存在的互不匹配的现象的技术. 简单的说,ORM是通过使用描述 ...
- 利用spring AOP实现每个请求的日志输出
前提条件: 除了spring相关jar包外,还需要引入aspectj包. <dependency> <groupId>org.aspectj</groupId> & ...
- 【Python】 关于import和package结构
关于import语句 python程序需要使用某个第三方模块的话要用import语句,其实就是把目标模块的内容加载到内存里.当然,在加载之前,python会按照一定的顺序寻找sys.path中的目录. ...
- 如何在http请求中使用线程池(干货)
这段时间对网络爬虫比较感兴趣,实现起来实际上比较简单.无非就是http的web请求,然后对返回的html内容进行内容筛选.本文的重点不在于这里,而在于多线程做http请求.例如我要实现如下场景:我有N ...
- 2017-2018-1 20155215 第九周 加分项 PWD命令的实现
1 学习pwd命令 Linux中用 pwd 命令来查看"当前工作目录"的完整路径. 简单得说,每当你在终端进行操作时,你都会有一个当前工作目录. 在不太确定当前位置时,就会使用pw ...
- Beta冲刺第二天
一.昨天的困难 没困难 二.今天进度 局部测试并修复出现的bug 1.林洋洋:修复登录页面显示问题,修复日程查询问题 2.黄腾达:修复创建协作开始时间和结束时间没做检验的问题 3.张合胜:修复页面内容 ...