MySQL join buffer使用
对于join buffer实现,于是做了以下实验:

从sql的执行计划中我们可以看到mysql使用using join buffer算法来优化改sql的查询,那么他的原理是什么?又是怎么样来实现的?在sql中注意到我加了hint提示符straight_join让,强制mysql按照查询中出现的顺序来连接表,意思是让t1表作为驱动表,t1中有多少记录,那么就要对t2表关联多少次(由于t2表为为我们子查询中的结果集,mysql在处理子查询的时候,把他子查询的结果放到临时表中,把临时表当做普通通进行处理,也就是执行计划中出现derived2,注意这里的临时表不在有id的索引了);
那么t2表就被多次的扫描,如果t2表的结果集非常的大,那么就会造成性能上的问题,所以mysql在这里对其进行了优化,采用Block Nested-Loop Join (BNL),具体算法描述为:
for each row in t1 matching range {
for each row in t2 matching reference key {
store used columns from t1, t2 in join buffer if buffer is full {
flush_buffer();
}
empty buffer
}
}
flush_buffer() {
for each row in t3 {
for each t1, t2 combination in join buffer {
if row satisfies join conditions, send to client
}
}
}
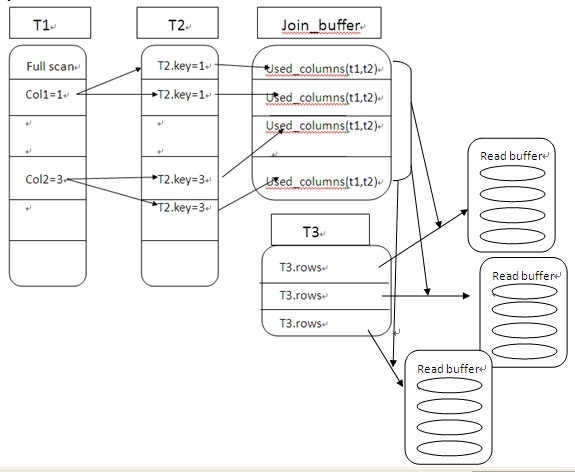
从图中可以看到把t1和t2的结果集放到join buffer中,而不用每次t1和t2关联后马上有和t3关联,这也是没有必要的,然后只需一次扫描t3即可完成这个查询;需要注意的是join buffer中只保留查询结果中出现的列值,它的大小不依赖于表的大小,我们在伪代码中看到当join buffer被填满后,mysql将会flush buffer。
注意:Join Buffer 只有当我们的 Join 类型为 ALL(如示例中),index,rang 或者是 index_merge 的时候 才能够使用
MySQL join buffer使用的更多相关文章
- MySQL join的实现原理及优化思路
Join 的实现原理 在MySQL 中,只有一种Join 算法,也就是Nested Loop Join,没有其他很多数据库所提供的Hash Join,也没有Sort Merge Join.顾名思义,N ...
- MySQL JOIN原理
先看一下实验的两张表: 表comments,总行数28856 表comments_for,总行数57,comments_id是有索引的,ID列为主键. 以上两张表是我们测试的基础,然后看一下索引,co ...
- MySQL Join算法与调优白皮书(二)
Index Nested-Loop Join (接上篇)由于访问的是辅助索引,如果查询需要访问聚集索引上的列,那么必要需要进行回表取数据,看似每条记录只是多了一次回表操作,但这才是INLJ算法最大 ...
- MySQL Join算法与调优白皮书(三)
Batched Key Access Join Index Nested-Loop Join虽好,但是通过辅助索引进行链接后需要回表,这里需要大量的随机I/O操作.若能优化随机I/O,那么就能极大的提 ...
- MySql join匹配原理
疑问 表:sl_sales_bill_head 订单抬头表 数据行:8474 表:sl_sales_bill 订单明细 数据行:8839 字段:SALES_BILL_NO 订单号 情 ...
- 神奇的 SQL 之 联表细节 → MySQL JOIN 的执行过程(一)
开心一刻 我:嗨,老板娘,有冰红茶没 老板娘:有 我:多少钱一瓶 老板娘:3块 我:给我来一瓶,给,3块 老板娘:来,你的冰红茶 我:玩呐,我要冰红茶,你给我个瓶盖干哈? 老板娘:这是再来一瓶,我家卖 ...
- MySQL JOIN原理(转)
先看一下实验的两张表: 表comments,总行数28856 表comments_for,总行数57,comments_id是有索引的,ID列为主键. 以上两张表是我们测试的基础,然后看一下索引,co ...
- MYSQL join 优化 --JOIN优化实践之快速匹配
MySQL的JOIN(四):JOIN优化实践之快速匹配 优化原则:小表驱动大表,被驱动表建立索引有效,驱动表建立索引基本无效果.A left join B :A是驱动表,B是被驱动表:A right ...
- 神奇的 SQL 之 联表细节 → MySQL JOIN 的执行过程(二)
开心一刻 一头母牛在吃草,突然一头公牛从远处狂奔而来说:“快跑啊!!楼主来了!” 母牛说:“楼主来了关我屁事啊?” 公牛急忙说:“楼主吹牛逼呀!” 母牛大惊,拔腿就跑,边跑边问:“你是公牛你怕什么啊? ...
随机推荐
- 开源侧滑菜单SlidingMenu主要方法介绍
SlidingMenu是一个很好使用的侧滑菜单开源项目,它的表现形式类似于DrawerLayout和SlidingDrawer,具体效果如下图所示,左侧为侧滑Menu菜单,右侧黑色部分为内容显示视图C ...
- 【Python】python读取文件操作mysql
尾大不掉,前阵子做检索测试时,总是因为需要业务端操作db和一些其他服务,这就使得检索测试对环境和数据依赖性特别高,极大提高了测试成本. Mock服务和mysql可以很好的解决这个问题,所以那阵子做了两 ...
- Selenium2Library系列 keywords 之 _SelectElementKeywords 之 page_should_not_contain_list(self, locator, message='', loglevel='INFO')
def page_should_not_contain_list(self, locator, message='', loglevel='INFO'): """Veri ...
- CSS:7个你可能不认识的单位
原文:7 CSS Units You Might Not Know About 众所周知,当使用CSS技术的时候,很容被一些奇异问题给困住.而当我们面对新的问题时,这会让我们处于非常不利的位置. 但是 ...
- 转】机器学习开源框架Mahout配置与入门研究
原博文出自于:http://www.ha97.com/5803.html 感谢! PS:机器学习这两年特别火,ATB使劲开百万到几百万年薪招美国牛校的机器学习方向博士,作为一个技术控,也得折腾下 ...
- Hibernate之管理session与批处理
1. Hibernate 自身提供了三种管理Session对象的方法 –Session对象的生命周期与本地线程绑定 –Session 对象的生命周期与JTA事务绑定 –Hibernate 委托程序管理 ...
- CentOs中iptables配置允许mysql远程访问
在CentOS系统中防火墙默认是阻止3306端口的,我们要是想访问mysql数据库,我们需要这个端口,命令如下: 1 /sbin/iptables -I INPUT -p tcp --dport 30 ...
- Codeforces Round #250 (Div. 1) D. The Child and Sequence (线段树)
题目链接:http://codeforces.com/problemset/problem/438/D 给你n个数,m个操作,1操作是查询l到r之间的和,2操作是将l到r之间大于等于x的数xor于x, ...
- POJ 3177 Redundant Paths(强连通分量)
题目链接:http://poj.org/problem?id=3177 题目大意是一个无向图给你n个点m条边,让你求出最少加多少条边 可以让任意两个点相通两条及以上的路线(每条路线点可以重复,但是每条 ...
- angular 管理后台
http://blog.csdn.net/iamnieo/article/details/50474399