Python爬虫学习(6): 爬取MM图片
为了有趣我们今天就主要去爬取以下MM的图片,并将其按名保存在本地。要爬取的网站为: 大秀台模特网
1. 分析网站
进入官网后我们发现有很多分类:

而我们要爬取的模特中的女模内容,点进入之后其网址为:http://www.daxiutai.com/mote/5.html ,这也将是我们爬取的入口点,为了方便,我们只是爬取其推荐的部分的模特的信息和图片。

当我们点击其中的一个人物的时候就会进入他们的个人主页中,里边包括个人的详细信息以及各种图片。模特的详细都将从这里爬取。
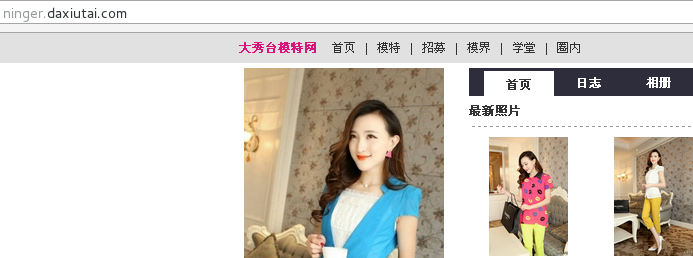
上述的个人主页中的模特图片不全,所以模特的图片将从其照片展示网页中爬取,而其照片的展示网页可以通过点击任意主页上的图片进入,如下图所示:

我们要实现的效果就是每个模特一个文件夹,特定模特文件夹下包括一个模特信息说明的txt文档以及其所有爬取到图片
2. 爬取过程
2.1 爬取各个模特的主页地址
在点击女性模特页面中的模特头像的时候就会进入此模特的主页之中,而各个模特的主页中包含模特的主要信息,所以要先在http://www.daxiutai.com/mote/5.html中获得每个模特的主页地址。

其最里边的<li>标签中就包含模特的主页地址信息,通过蓝色选中部分中地址就可以获取模特主页地址,但却不是图片的地址,应为其是被重定向过。

In [93]: url_femal = "http://www.daxiutai.com/mote/5.html"
In [94]: request = urllib2.Request(url_femal)
In [95]: response = urllib2.urlopen(request)
In [96]: content = response.read()
#绿色部分就是获取到的地址
In [105]: pattern = re.compile(r"(?:<li\s+class=\"li_01\">).*?<a\s+href=\"(.*?)\".*?>",re.S)
In [106]: result = re.findall(pattern,content)
In [107]: result[0]
Out[107]: 'http://www.daxiutai.com/mote_profile/13517.html'
# 总共抓取了60条数据
In [108]: len(result)
Out[108]: 60
艾,写网页的那个家伙太懒了没有把女模特和其它的模特区分开来,所以只能把其他的都抓取下来,而且有重复地址,所以还要去重。
# 去除重复
In [110]: result = list(set(result))
In [111]: len(result)
Out[111]: 57
因为上述这些抓取到的地址在访问的时候会重定向,所以我们需要一一获取其重定后的地址,这一阶段比较费时间,得等一会儿。
#重定位后的地址放在main_url中
In [124]: main_url = []
# 循环获取重定位后的地址
In [125]: for item in result:
...: res = urllib2.urlopen(item)
...: main_url.append(res.geturl())
...: print res.geturl()
http://www.daxiutai.com/mote_profile/13523.html
http://heijin.daxiutai.com/
http://fuxinyu.daxiutai.com/
http://152nicai.daxiutai.com/
http://lfh0706.daxiutai.com/
http://649629484.daxiutai.com/
........................
上述打印的地址中红色类型的地址不是重定位后的地址,且是不可访问的,如果在浏览器中输入此地址会出现如下反应:
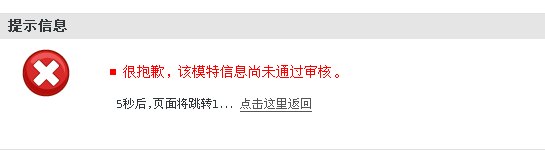
所以这样的地址是需要剔除的,剔除时所依据的特性就是//后边是否接着www。
In [135]: main = [] In [136]: for item in main_url:
...: mat = re.match(".*?www.*?",item)
...: if not mat:
...: main.append(item)
# 剔除之后还有55条数据
In [137]: len(main)
Out[137]: 55
2.2 爬取模特的个人信息
模特的个人信息显示如图所示:
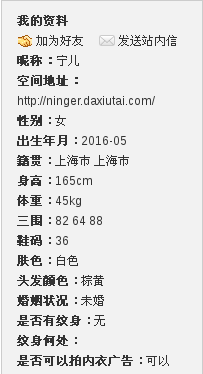
HTML源码情况为:

粗略提取一个模特的信息:
In [184]: response = urllib2.urlopen(main[10],timeout=5)
...: content = response.read() In [185]: pattern = re.compile(r"<strong>(.*?)</strong>(.+?)<br\s*/>")
In [186]: result = re.findall(pattern,content)
In [187]: for item in result:
...: print item[0],item[1] 昵称: 我才是宝宝
空间地址: <br /><a href="http://babysix.daxiutai.com/">http://babysix.daxiutai.com/</a>
性别 :女
出生年月 :2016-03
籍贯 :天津市 天津市
身高 :166cm
体重 :45kg
三围 :82 63 88
鞋码 :38
肤色 :黄色
头发颜色 :黑
婚姻状况 :未婚
是否有纹身 :无
纹身何处 :
是否可以拍内衣广告 :不可以
我们发现在匹配过程中中文的:符号也被匹配出来了,而这个在匹配过程中应该去掉。同时空间地址一项的结果明显混乱,但是为了不增加正则表达式的难度,我们在后续处理中直接用我们重定向后的地址取代这个地址即可。
因为包含中文符号的情况可能是这样的:

也会是这样的:

所以明显感觉到了网页的作者的慢慢的恶意。。。。。,所以我们用 (?::)? 来解决这个问题。分组中?:表示匹配但不计入结果,接下来的:是要匹配到的中文冒号,一定要是中文的,分组外边的?表示这个分组可以匹配到也可以匹配不到都行。
In [205]: response = urllib2.urlopen(main[10],timeout=5)
In [206]: content = response.read() In [207]: pattern = re.compile(r"<strong>(.*?)(?::)?</strong>(?::)?(.+?)<br\s*/>") In [208]: result = re.findall(pattern,content) In [209]: for item in result:
...: print item[0],item[1]
...:
昵称 我才是宝宝
空间地址 <br /><a href="http://babysix.daxiutai.com/">http://babysix.daxiutai.com/</a>
性别 女
出生年月 2016-03
籍贯 天津市 天津市
身高 166cm
体重 45kg
三围 82 63 88
鞋码 38
肤色 黄色
头发颜色 黑
婚姻状况 未婚
是否有纹身 无
纹身何处 : # 这里还是有些问题,为了简单我们就不再更改内容了
是否可以拍内衣广告 不可以
上边仅仅是获取一个模特的详细信息,接下来我们将获取所有的模特的信息:
In [90]: result = []
In [90]: for item in main:
response = urllib2.urlopen(item,timeout=8)
content = response.read()
temp = re.findall(pattern,content)
result.append(temp)
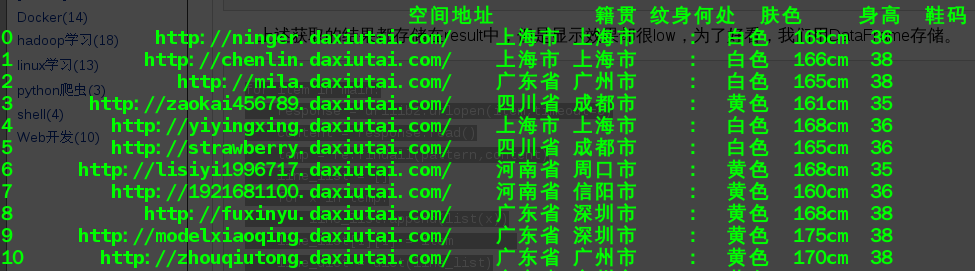
上述获取的结果都存储在result中,但是显示效果却很low,为了好看,我们用DataFrame存储。
注意:下边的代码如果直接copy到ipython中执行会有错误,最好是自己按照代码层级自己敲入:
for item in main:
response = urllib2.urlopen(item,timeout=8)
content = response.read()
temp = re.findall(pattern,content)
line_list = []
for x in temp:
line_list.append(list(x))
# 这里
line_list[1][1] = item
line_dict = dict(line_list)
result.append(line_dict)
frame = DataFrame(result)
效果如下图所表示(只是截取了前10个信息):
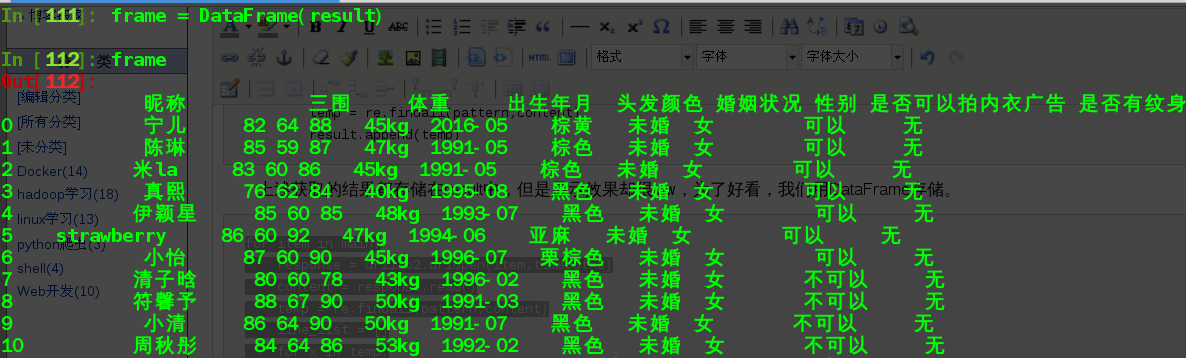
为了方便,我们将这个过程写为一个python可执行文件,内容如下:
#!/usr/bin/python
#! -*- coding:utf-8 -*- import urllib
import urllib2
import re
import numpy as np
import pandas as pd
from pandas import DataFrame,Series class ScrapModel:
def __init__(self):
self.entry_url = "http://www.daxiutai.com/mote/5.html"
def get_personal_address(self):
try:
print "进入主页中..."
request = urllib2.Request(self.entry_url)
response = urllib2.urlopen(request,timeout=5)
content = response.read()
pattern = re.compile(r"(?:<li\s+class=\"li_01\">).*?<a\s+href=\"(.*?)\".*?>",re.S)
original_add = re.findall(pattern,content)
# 去重复
original_add = list(set(original_add))
redirect_add = []
print "获取重定向地址中..."
for item in original_add:
res = urllib2.urlopen(item,timeout=5)
url = res.geturl()
# 去除不可访问地址
mat = re.match(r".*?www.*?",url)
if not mat:
redirect_add.append(url)
print url
return redirect_add
except Exception,e:
if hasattr(e,"reason"):
print u"连接失败,原因:",e.reason
if hasattr(e,"code"):
print "code:",e.code
return None
def get_personal_info(self,redirect_add):
if (len(redirect_add) == 0):
print "传入参数长度为0"
return None
try:
pattern = re.compile(r"<strong>(.*?)(?::)?</strong>(?::)?(.+?)<br\s*/>")
print "获取模特信息中..."
result = []
for item in redirect_add:
response = urllib2.urlopen(item,timeout=8)
content = response.read()
temp = re.findall(pattern,content)
line_list = []
for x in temp:
# list(x) 是将匹配到的二元组变换为二元的list
line_list.append(list(x))
print "获取到 %s 的信息"%line_list[0][1]
# 这里重新设置模特的空间地址
line_list[1][1] = item
# 这个做法会将二元list的第一个元素变成字典的类型的key,对应的第二个会变成value
line_dict = dict(line_list)
result.append(line_dict)
# 将结果转换为DataFrame类型
frame = DataFrame(result)
print frame
return frame
except Exception,e:
print Exception,e
if hasattr(e,"reason"):
print u"连接失败,原因:",e.reason
if hasattr(e,"code"):
print "code:",e.code
return None spider = ScrapModel()
redirect_add = spider.get_personal_address()
spider.get_personal_info(redirect_add)
2.3 爬取模特的图片
在模特的个人主页中点击相册就会进入相册界面,其地址格式为: 个人主页/album.html

而点击其中的任意一个相册就会进入其图片展示页面,而我们的图片也将从这里抓取

所以接下来我们要获取每一个相册的地址,我们从每个模特的相册集页面中进入,也就是地址格式为: 个人主页地址/album.html 的形式:
In [226]: url = "http://yiyingxing.daxiutai.com/album.html" In [227]: response =urllib2.urlopen(urllib2.Request(url)) In [228]: content = response.read() In [229]: pattern = re.compile(r"<p><a.*?href=\"(.*?)\".*?img.*?/a></p>") In [230]: albums = re.findall(pattern,content) In [231]: albums
Out[231]:
['http://yiyingxing.daxiutai.com/photo/14422.html',
'http://yiyingxing.daxiutai.com/photo/14421.html']
接下来我们获取所有模特的相册地址
# model_info就是前边一节中get_personal_info返回的结果
def get_albums_address(modle_info):
albums_addr = {}
try:
redirect_add = modle_info.index.tolist()
pattern = re.compile(r"<p><a.*?href=\"(.*?)\".*?img.*?/a></p>")
for item in redirect_add:
response = urllib2.urlopen(item + "album.html",timeout=10)
content = response.read()
albums = re.findall(pattern,content)
print "the albums is:",albums
albums_addr[item] = albums
return albums_addr
except Exception,e:
print Exception,e
if hasattr(e,"reason"):
print u"连接失败,原因:",e.reason
if hasattr(e,"code"):
print "code:",e.code
return None
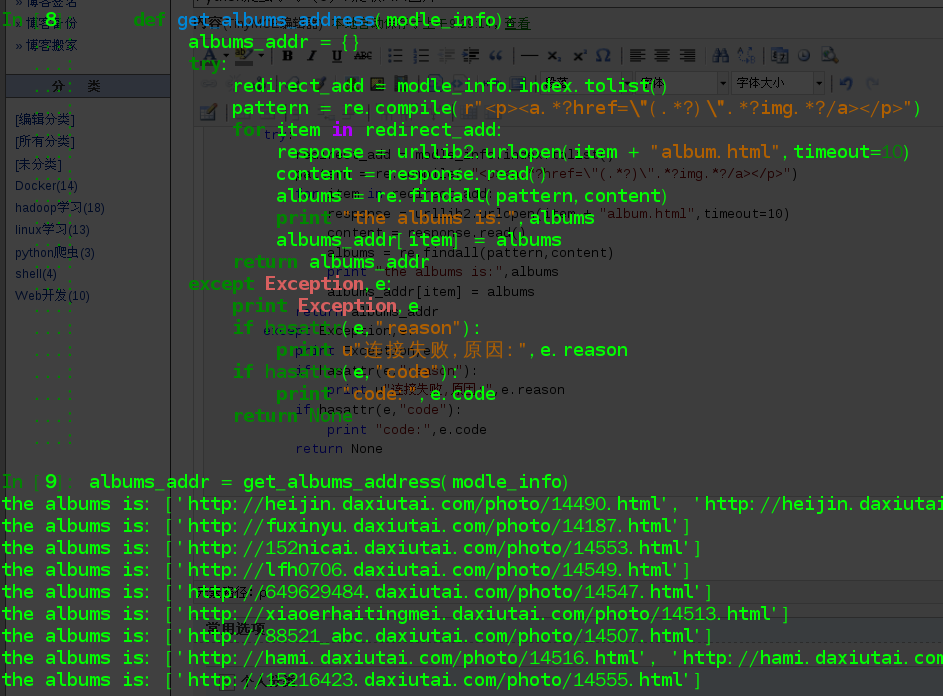
获取到的地址放在字典类型中,其中的每一项的key值是模特的个人主页,value就是相册地址构成的列表。
获取到了相册地址之后就该进入每一个相册中获取其图片,但是有的时候其相册页面中的图片就是原图,像这样的:

但有的时候却又是缩略图,是这样的:

实际上去掉图片名中 _thumb 就会是原图地址,所以这两种都按照一种形式抓取,然后去掉缩略图中的 _thumb:
def get_album_photos(address):
print "获取一个新模特的图片中..."
photos = []
try:
pattern = re.compile(r"<p><a.*?rel=\"(.*?)\".*?/a></p>")
for item in address:
response = urllib2.urlopen(item,timeout=10)
content = response.read()
temp = re.findall(pattern,content)
if temp:
print "获得了MM的%d张照片",len(temp)
photos = photos + temp
if not photos:
print "这家伙太懒了,什么图片都没有留下.."
return None
return photos
except Exception,e:
print Exception,e
if hasattr(e,"reason"):
print u"连接失败,原因:",e.reason
if hasattr(e,"code"):
print "code:",e.code
return None
用获取到的模特相册地址测试调用:
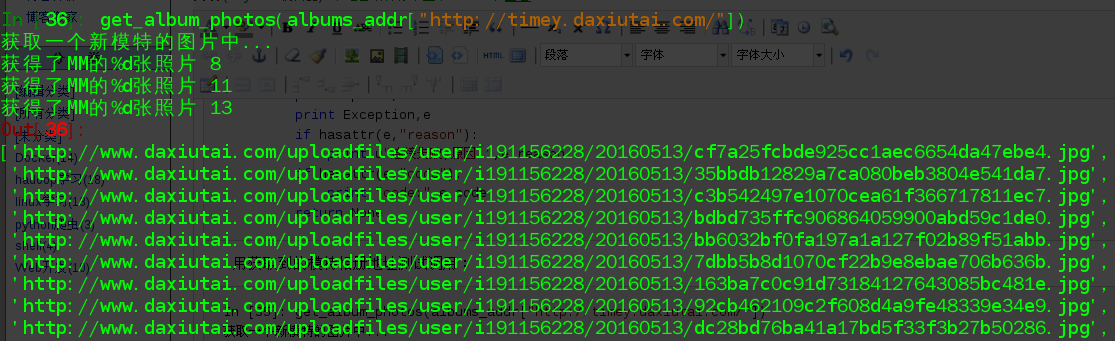
In [35]: get_album_photos(albums_addr["http://timey.daxiutai.com/"])
获取一个新模特的图片中...
获得了MM的%d张照片 8
获得了MM的%d张照片 11
获得了MM的%d张照片 13
Out[35]:
['http://www.daxiutai.com/uploadfiles/user/i191156228/20160513/cf7a25fcbde925cc1aec6654da47ebe4.jpg',
'http://www.daxiutai.com/uploadfiles/user/i191156228/20160513/35bbdb12829a7ca080beb3804e541da7.jpg',
获取所有的图片,并将放入字典类型中
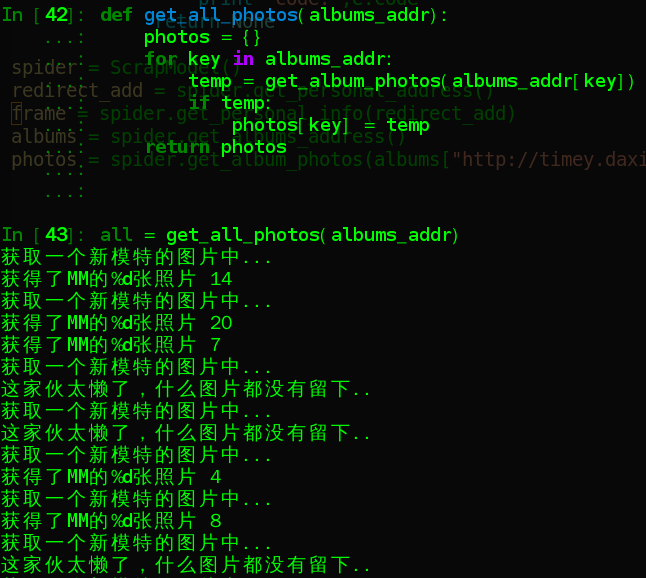
def get_all_photos(albums_addr):
photos = {}
for key in albums_addr:
temp = get_album_photos(albums_addr[key])
if temp:
photos[key] = temp
return photos
2.4 信息保存
模特的图片和个人信息已经有了,接下来我们就将其保存在本地。
def save_one_info(self,info,photos):
dir_name = info[" 昵称"]
exists = os.path.exists(dir_name)
if not exists:
print "创建模特文件夹:"+dir_name
os.makedirs(dir_name)
print "保存模特信息中: "+dir_name
one.to_csv(dir_name+"/"+dir_name+".txt",sep=":")
for photo in photos:
photo = re.sub("_thumb","",photo)
file_name = dir_name+"/"+re.split("/",photo)[-1]
print "正在保存图片: "+file_name
res = urllib.urlopen(photo)
data = res.read()
f = open(file_name,"wb")
f.write(data)
f.close()
测试一个人的保存:
save_one_info(modle_info.ix["http://zaokai456789.daxiutai.com/"],all["http://zaokai456789.daxiutai.com/"])
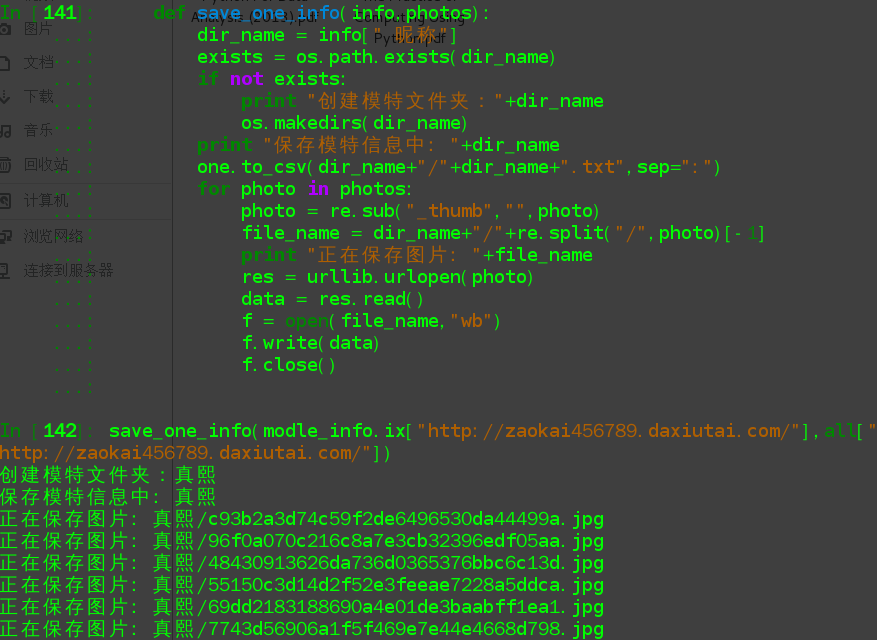
保存后的结果:

好了,接下来我们将保存所有人的图片以及信息:
def save_all_info(modle_info,modles_photos):
for item in modles_photos:
save_one_info(modle_info.ix[item],modles_photos[item])

3. 完整的爬取过程
python 入手不久,欢迎大神莫喷
#!/usr/bin/python
#! -*- coding:utf-8 -*- import os
import urllib
import urllib2
import re
import numpy as np
import pandas as pd
from pandas import DataFrame,Series class ScrapModel:
def __init__(self):
self.entry_url = "http://www.daxiutai.com/mote/5.html"
self.modle_info = DataFrame()
self.albums_addr = {}
def get_personal_address(self):
try:
print "进入主页中..."
request = urllib2.Request(self.entry_url)
response = urllib2.urlopen(request,timeout=5)
content = response.read()
pattern = re.compile(r"(?:<li\s+class=\"li_01\">).*?<a\s+href=\"(.*?)\".*?>",re.S)
original_add = re.findall(pattern,content)
# 去重复
original_add = list(set(original_add))
redirect_add = []
print "获取重定向地址中..."
for item in original_add:
res = urllib2.urlopen(item,timeout=5)
url = res.geturl()
# 去除不可访问地址
mat = re.match(r".*?www.*?",url)
if not mat:
redirect_add.append(url)
print url
return redirect_add
except Exception,e:
if hasattr(e,"reason"):
print u"连接失败,原因:",e.reason
if hasattr(e,"code"):
print "code:",e.code
return None def get_personal_info(self,redirect_add):
if (len(redirect_add) == 0):
print "传入参数长度为0"
return None
try:
pattern = re.compile(r"<strong>(.*?)(?::)?</strong>(?::)?(.+?)<br\s*/>")
print "获取模特信息中..."
result = []
for item in redirect_add:
response = urllib2.urlopen(item,timeout=10)
content = response.read()
temp = re.findall(pattern,content)
line_list = []
for x in temp:
# list(x) 是将匹配到的二元组变换为二元的list
line_list.append(list(x))
print "获取到 %s 的信息"%line_list[0][1]
# 这里重新设置模特的空间地址
line_list[1][1] = item
# 这个做法会将二元list的第一个元素变成字典的类型的key,对应的第二个会变成value
line_dict = dict(line_list)
result.append(line_dict)
# 将结果转换为DataFrame类型
self.modle_info = DataFrame(result)
self.modle_info = self.modle_info.set_index("空间地址")
print self.modle_info
return self.modle_info
except Exception,e:
print Exception,e
if hasattr(e,"reason"):
print u"连接失败,原因:",e.reason
if hasattr(e,"code"):
print "code:",e.code
return None
#获取每个模特的每个相册的地址,每个模特都会有一个默认相册地址,但是里边可能没有图片
def get_albums_address(self):
try:
redirect_add = self.modle_info.index.tolist()
pattern = re.compile(r"<p><a.*?href=\"(.*?)\".*?img.*?/a></p>")
for item in redirect_add:
response = urllib2.urlopen(item + "album.html",timeout=10)
content = response.read()
albums = re.findall(pattern,content)
print "the albums is:",albums
self.albums_addr[item] = albums
return self.albums_addr
except Exception,e:
print Exception,e
if hasattr(e,"reason"):
print u"连接失败,原因:",e.reason
if hasattr(e,"code"):
print "code:",e.code
return None # 获取一个模特的所有图片地址
def get_album_photos(self,address):
print "获取一个新模特的图片中..."
photos = []
try:
pattern = re.compile(r"<p><a.*?rel=\"(.*?)\".*?/a></p>")
for item in address:
response = urllib2.urlopen(item,timeout=10)
content = response.read()
temp = re.findall(pattern,content)
if temp:
print "获得了MM的%d张照片",len(temp)
photos = photos + temp
if not photos:
print "这家伙太懒了,什么图片都没有留下.."
return None
return photos
except Exception,e:
print Exception,e
if hasattr(e,"reason"):
print u"连接失败,原因:",e.reason
if hasattr(e,"code"):
print "code:",e.code
return None # 获取所有模特的图片地址
def get_all_photos(self,albums_addr):
photos = {}
for key in albums_addr:
temp = self.get_album_photos(albums_addr[key])
if temp:
photos[key] = temp
return photos # 保存一个模特的信息
def save_one_info(self,info,photos):
dir_name = info[" 昵称"]
exists = os.path.exists(dir_name)
if not exists:
print "创建模特文件夹:"+dir_name
os.makedirs(dir_name)
print "保存模特信息中: "+dir_name
info.to_csv(dir_name+"/"+dir_name+".txt",sep=":")
for photo in photos:
photo = re.sub("_thumb","",photo)
file_name = dir_name+"/"+re.split("/",photo)[-1]
print "正在保存图片: "+file_name
res = urllib.urlopen(photo)
data = res.read()
f = open(file_name,"wb")
f.write(data)
f.close()
# 保存所有模特的信息
def save_all_info(self,modle_info,modles_photos):
for item in modles_photos:
self.save_one_info(modle_info.ix[item],modles_photos[item]) spider = ScrapModel()
redirect_add = spider.get_personal_address()
frame = spider.get_personal_info(redirect_add)
albums = spider.get_albums_address()
all_photos = spider.get_all_photos(albums)
spider.save_all_info(frame,all_photos)
Python爬虫学习(6): 爬取MM图片的更多相关文章
- python学习(十七) 爬取MM图片
这一篇巩固前几篇文章的学到的技术,利用urllib库爬取美女图片,其中采用了多线程,文件读写,目录匹配,正则表达式解析,字符串拼接等知识,这些都是前文提到的,综合运用一下,写个爬虫示例爬取美女图片.先 ...
- python爬虫学习(7) —— 爬取你的AC代码
上一篇文章中,我们介绍了python爬虫利器--requests,并且拿HDU做了小测试. 这篇文章,我们来爬取一下自己AC的代码. 1 确定ac代码对应的页面 如下图所示,我们一般情况可以通过该顺序 ...
- Python爬虫学习(二) ——————爬取前程无忧招聘信息并写入excel
作为一名Pythoner,相信大家对Python的就业前景或多或少会有一些关注.索性我们就写一个爬虫去获取一些我们需要的信息,今天我们要爬取的是前程无忧!说干就干!进入到前程无忧的官网,输入关键字&q ...
- python爬虫学习之爬取全国各省市县级城市邮政编码
实例需求:运用python语言在http://www.ip138.com/post/网站爬取全国各个省市县级城市的邮政编码,并且保存在excel文件中 实例环境:python3.7 requests库 ...
- python 爬虫之requests爬取页面图片的url,并将图片下载到本地
大家好我叫hardy 需求:爬取某个页面,并把该页面的图片下载到本地 思考: img标签一个有多少种类型的src值?四种:1.以http开头的网络链接.2.以“//”开头网络地址.3.以“/”开头绝对 ...
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- Python 爬虫入门之爬取妹子图
Python 爬虫入门之爬取妹子图 来源:李英杰 链接: https://segmentfault.com/a/1190000015798452 听说你写代码没动力?本文就给你动力,爬取妹子图.如果 ...
- Python爬虫实战之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 对百度贴吧的任意帖子进行抓取 指定是否只抓取楼主发帖 ...
- Python爬虫实例:爬取B站《工作细胞》短评——异步加载信息的爬取
很多网页的信息都是通过异步加载的,本文就举例讨论下此类网页的抓取. <工作细胞>最近比较火,bilibili 上目前的短评已经有17000多条. 先看分析下页面 右边 li 标签中的就是短 ...
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
随机推荐
- MySQL插入数据返回id
按照应用需要,常常要取得刚刚插入数据库表里的记录的ID值,在MYSQL中可以使用LAST_INSERT_ID()函数,在MSSQL中使用 @@IDENTITY.挺方便的一个函数.但是,这里需要注意的是 ...
- PHP 文件管理
主页面: <?php session_start(); $filename=""; if(!empty($_SESSION["lujing"])) { $ ...
- shell判断条件整理
1.字符串判断 str1 = str2 当两个字符串串有相同内容.长度时为真 str1 != str2 当字符串str1和str2不等时为真 -n str1 当字符串的长度大于0时为真(串非空) -z ...
- 要学Java,怎么高效地学习,怎么规划
要学Java,怎么高效地学习,怎么规划? 题主是一个个例,99%的人(包括我自己)都没有题主这样的经历,也很难提出具有很强参考性的java学习建议.我倒是之前面试过一个跟题主有点类似的人,拿出来分 ...
- [译]使用branch
这篇文章将介绍Git分支. 首先, 看看如果创建分支, 这就像是request一个新的项目历史. 接着, 来看看git checkout是如果能被用来选择一个分支的. 最后, 学习用git merge ...
- 微信安卓版下载 Android微信各版本列表
前面ytkah弄了一个iso微信各版本列表,现在就来整一个微信 for Android各版本列表,方便大伙下载.每个版本都放出一些新的功能或修复相关错误,详情可以点击下面的版本链接进行查看.资源收集于 ...
- HDU 2376 树形dp|树上任意两点距离和的平均值
原题:http://acm.hdu.edu.cn/showproblem.php?pid=2376 经典问题,求的是树上任意两点和的平均值. 这里我们不能枚举点,这样n^2的复杂度.我们可以枚举每一条 ...
- C#高级编程笔记 Delegate 的粗浅理解 2016年9月 13日
Delegate [重中之重] 委托 定义一:(参考)http://www.cnblogs.com/zhangchenliang/archive/2012/09/19/2694430.html 完全可 ...
- PHP 动态生成验证码
……机器人会在网站中搜寻允许他们插入广告的输入表单,在虚拟世界没有什么能阻挡它们胡作非为.这些机器人效率极高,完全不关心所攻击的表单的本来用途.它们唯一的目标就是用它们的垃圾广告覆盖你的内容,残忍地为 ...
- OOCSS的概念和思路
<概念> <思路> 面向对象的CSS有两个原则: 独立的结构和样式 独立的容器和内容 以下几点是创建OOCSS的关键部分: 创建一个组件库 独立的容器和内容,并且避免样式来依赖 ...