Flink 和 Iceberg 如何解决数据入湖面临的挑战
简介: 4.17 上海站 Meetup 胡争老师分享内容:数据入湖的挑战有哪些,以及如何用 Flink + Iceberg 解决此类问题。
一、数据入湖的核心挑战
数据实时入湖可以分成三个部分,分别是数据源、数据管道和数据湖(数仓),本文的内容将围绕这三部分展开。

1. Case #1:程序 BUG 导致数据传输中断
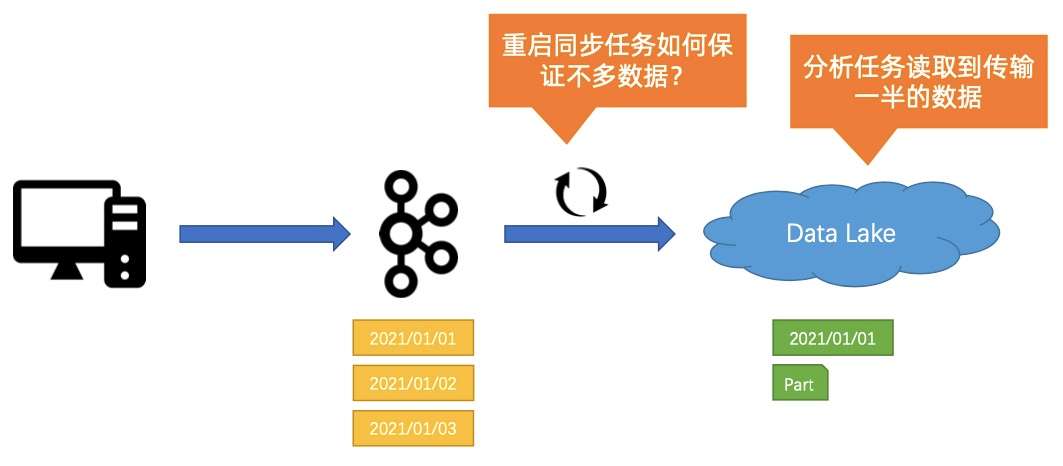
- 首先,当数据源通过数据管道传到数据湖(数仓)时,很有可能会遇到作业有 BUG 的情况,导致数据传到一半,对业务造成影响;
- 第二个问题是当遇到这种情况的时候,如何重起作业,并保证数据不重复也不缺失,完整地同步到数据湖(数仓)中。
2. Case #2:数据变更太痛苦
- 数据变更
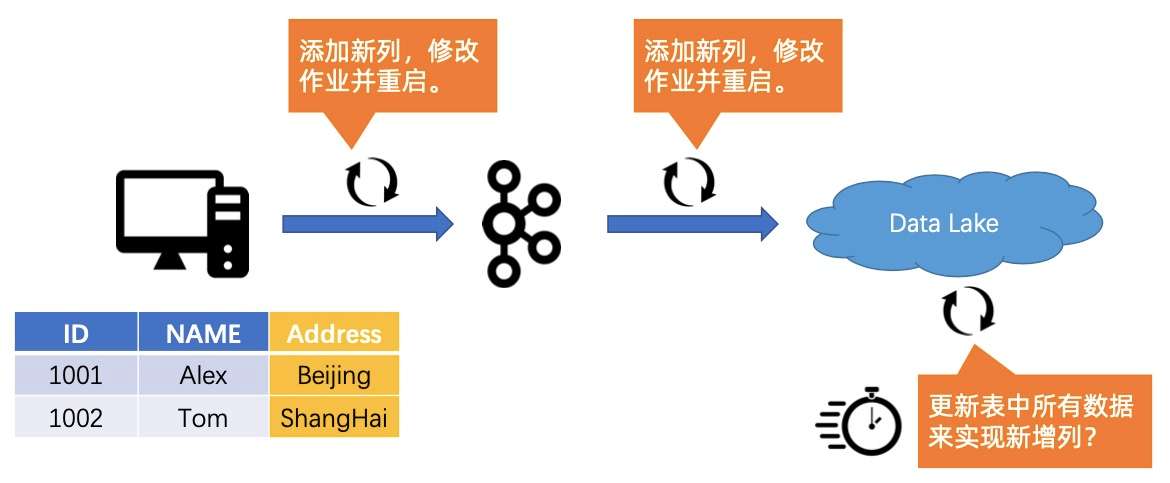
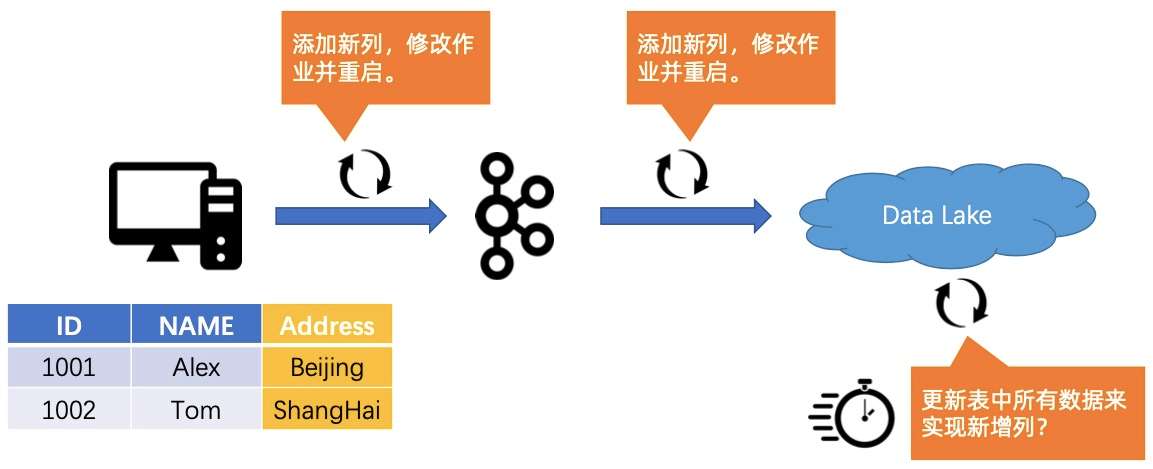
当发生数据变更的情况时,会给整条链路带来较大的压力和挑战。以下图为例,原先是一个表定义了两个字段,分别是 ID 和 NAME。此时,业务方面的同学表示需要将地址加上,以方便更好地挖掘用户的价值。
首先,我们需要把 Source 表加上一个列 Address,然后再把到 Kafka 中间的链路加上链,然后修改作业并重启。接着整条链路得一路改过去,添加新列,修改作业并重启,最后把数据湖(数仓)里的所有数据全部更新,从而实现新增列。这个过程的操作不仅耗时,而且会引入一个问题,就是如何保证数据的隔离性,在变更的过程中不会对分析作业的读取造成影响。
- 分区变更
如下图所示,数仓里面的表是以 “月” 为单位进行分区,现在希望改成以 “天” 为单位做分区,这可能就需要将很多系统的数据全部更新一遍,然后再用新的策略进行分区,这个过程十分耗时。

3. Case #3:越来越慢的近实时报表?
当业务需要更加近实时的报表时,需要将数据的导入周期,从 “天” 改到 “小时”,甚至 “分钟” 级别,这可能会带来一系列问题。
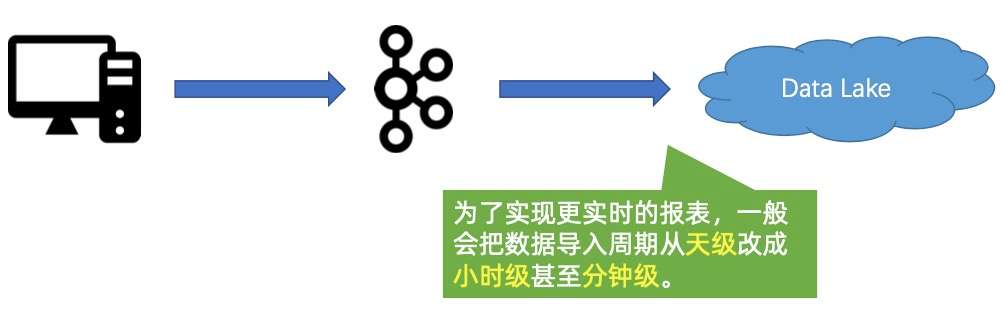

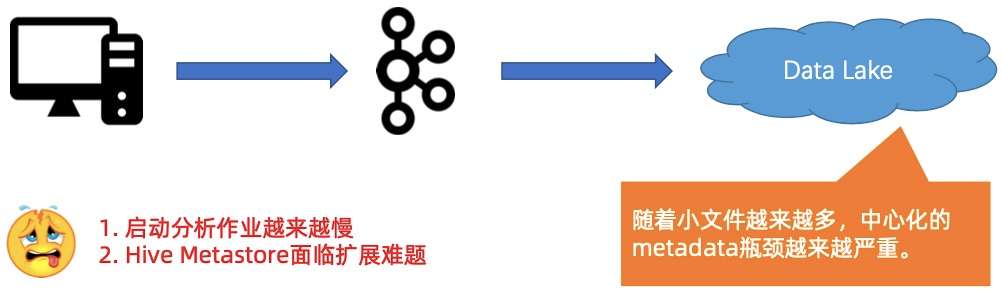
如上图所示,首先带来的第一个问题是:文件数以肉眼可见的速度增长,这将对外面的系统造成越来越大的压力。压力主要体现在两个方面:
第一个压力是,启动分析作业越来越慢,Hive Metastore 面临扩展难题,如下图所示。
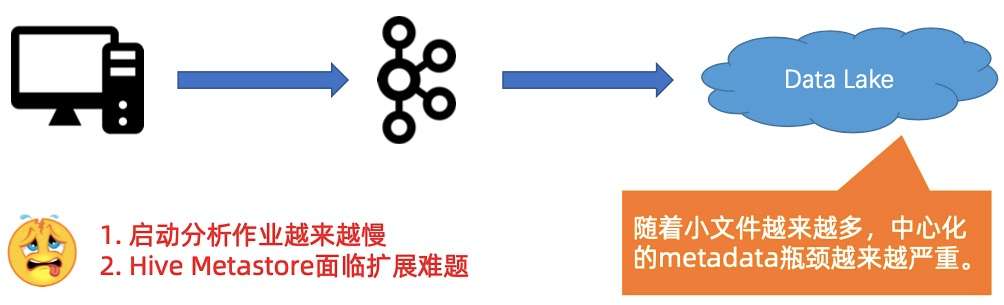
- 随着小文件越来越多,使用中心化的 Metastore 的瓶颈会越来越严重,这会造成启动分析作业越来越慢,因为启动作业的时候,会把所有的小文件原数据都扫一遍。
- 第二是因为 Metastore 是中心化的系统,很容易碰到 Metastore 扩展难题。例如 Hive,可能就要想办法扩后面的 MySQL,造成较大的维护成本和开销。
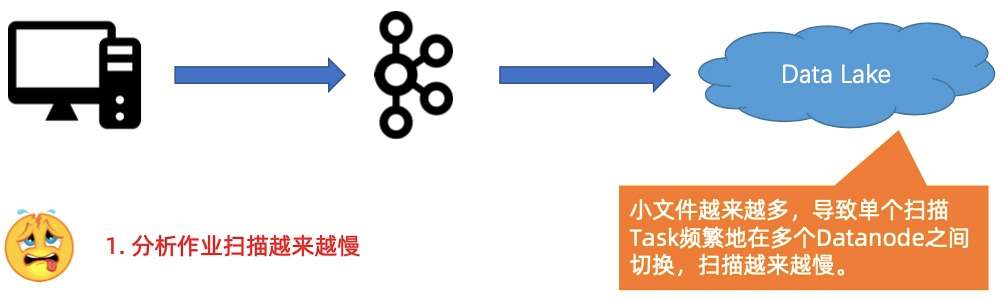
- 第二个压力是扫描分析作业越来越慢。
随着小文件增加,在分析作业起来之后,会发现扫描的过程越来越慢。本质是因为小文件大量增加,导致扫描作业在很多个 Datanode 之间频繁切换。

4. Case #4:实时地分析 CDC 数据很困难
大家调研 Hadoop 里各种各样的系统,发现整个链路需要跑得又快又好又稳定,并且有好的并发,这并不容易。
- 首先从源端来看,比如要将 MySQL 的数据同步到数据湖进行分析,可能会面临一个问题,就是 MySQL 里面有存量数据,后面如果不断产生增量数据,如何完美地同步全量和增量数据到数据湖中,保证数据不多也不少。

- 此外,假设解决了源头的全量跟增量切换,如果在同步过程中遇到异常,如上游的 Schema 变更导致作业中断,如何保证 CDC 数据一行不少地同步到下游。

- 整条链路的搭建,需要涉及源头全量跟同步的切换,包括中间数据流的串通,还有写入到数据湖(数仓)的流程,搭建整个链路需要写很多代码,开发门槛较高。
- 最后一个问题,也是关键的一个问题,就是我们发现在开源的生态和系统中,很难找到高效、高并发分析 CDC 这种变更性质的数据。

5. 数据入湖面临的核心挑战
数据同步任务中断
- 无法有效隔离写入对分析的影响;
- 同步任务不保证 exactly-once 语义。
端到端数据变更
- DDL 导致全链路更新升级复杂;
- 修改湖/仓中存量数据困难。
越来越慢的近实时报表
- 频繁写入产生大量小文件;
- Metadata 系统压力大, 启动作业慢;
- 大量小文件导致数据扫描慢。
无法近实时分析 CDC 数据
- 难以完成全量到增量同步的切换;
- 涉及端到端的代码开发,门槛高;
- 开源界缺乏高效的存储系统。
二、Apache Iceberg 介绍
1. Netflix:Hive 上云痛点总结
Netflix 做 Iceberg 最关键的原因是想解决 Hive 上云的痛点,痛点主要分为以下三个方面:
1.1 痛点一:数据变更和回溯困难
- 不提供 ACID 语义。在发生数据改动时,很难隔离对分析任务的影响。典型操作如:INSERT OVERWRITE;修改数据分区;修改 Schema;
- 无法处理多个数据改动,造成冲突问题;
- 无法有效回溯历史版本。
1.2 痛点二:替换 HDFS 为 S3 困难
- 数据访问接口直接依赖 HDFS API;
- 依赖 RENAME 接口的原子性,这在类似 S3 这样的对象存储上很难实现同样的语义;
- 大量依赖文件目录的 list 接口,这在对象存储系统上很低效。
1.3 痛点三:太多细节问题
- Schema 变更时,不同文件格式行为不一致。不同 FileFormat 甚至连数据类型的支持都不一致;
- Metastore 仅维护 partition 级别的统计信息,造成不 task plan 开销; Hive Metastore 难以扩展;
- 非 partition 字段不能做 partition prune。
2. Apache Iceberg 核心特性
通用化标准设计
- 完美解耦计算引擎
- Schema 标准化
- 开放的数据格式
- 支持 Java 和 Python
完善的 Table 语义
- Schema 定义与变更
- 灵活的 Partition 策略
- ACID 语义
- Snapshot 语义
丰富的数据管理
- 存储的流批统一
- 可扩展的 META 设计支持
- 批更新和 CDC
- 支持文件加密
性价比
- 计算下推设计
- 低成本的元数据管理
- 向量化计算
- 轻量级索引
3. Apache Iceberg File Layout
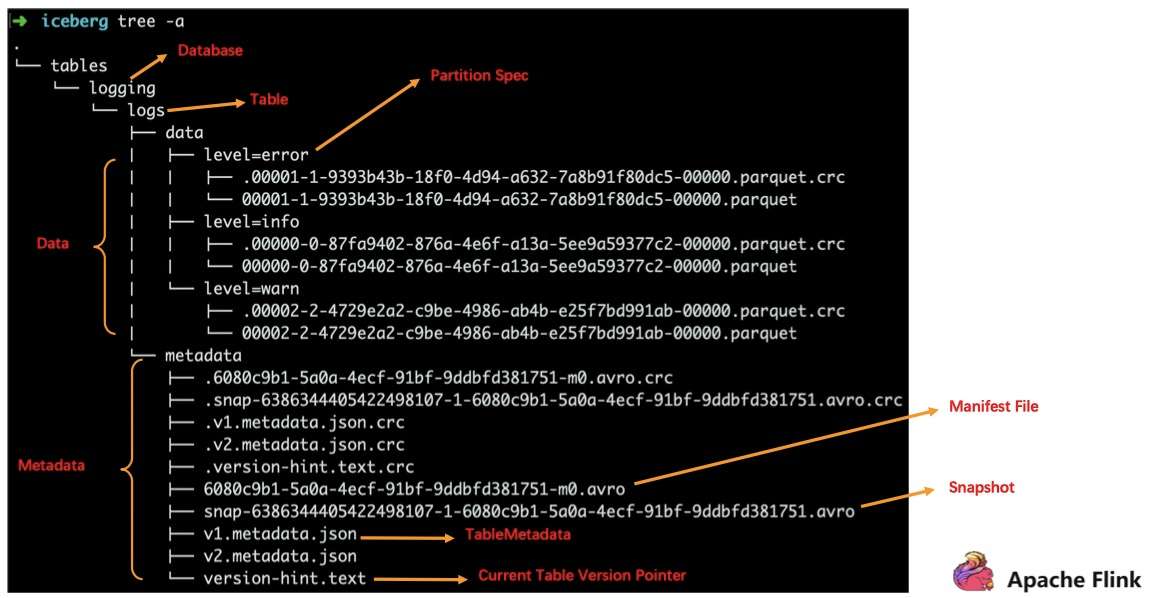
上方为一个标准的 Iceberg 的 TableFormat 结构,核心分为两部分,一部分是 Data,一部分是 Metadata,无论哪部分都是维护在 S3 或者是 HDFS 之上的。
4. Apache Iceberg Snapshot View
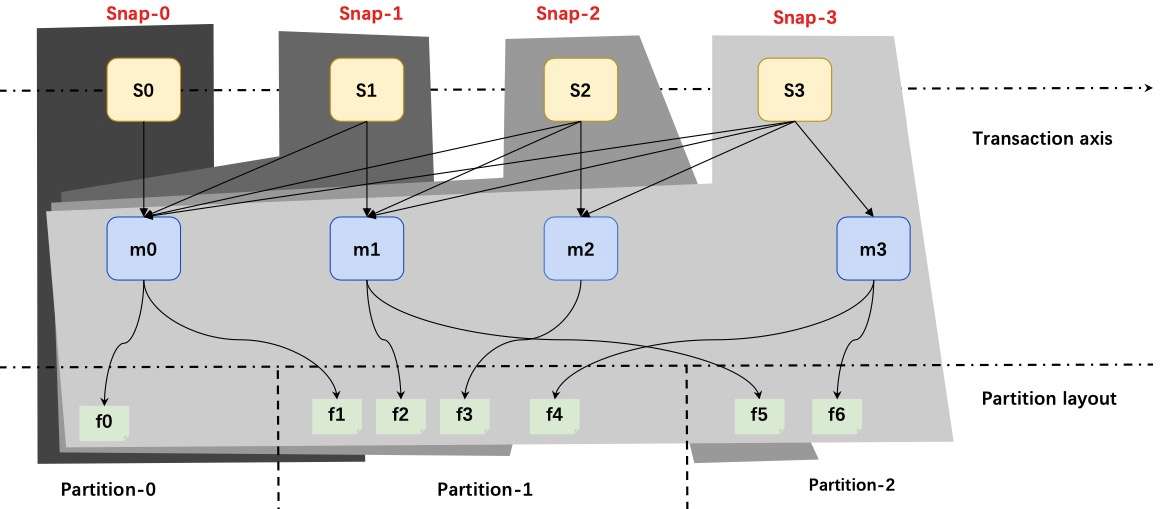
上图为 Iceberg 的写入跟读取的大致流程。
可以看到这里面分三层:
- 最上面黄色的是快照;
- 中间蓝色的是 Manifest;
- 最下面是文件。
每次写入都会产生一批文件,一个或多个 Manifest,还有快照。
比如第一次形成了快照 Snap-0,第二次形成快照 Snap-1,以此类推。但是在维护原数据的时候,都是增量一步一步做追加维护的。
这样的话可以帮助用户在一个统一的存储上做批量的数据分析,也可以基于存储之上去做快照之间的增量分析,这也是 Iceberg 在流跟批的读写上能够做到一些支持的原因。
5. 选择 Apache Iceberg 的公司

上图为目前在使用 Apache Iceberg 的部分公司,国内的例子大家都较为熟悉,这里大致介绍一下国外公司的使用情况。
- NetFlix 现在是有数百PB的数据规模放到 Apache Iceberg 之上,Flink 每天的数据增量是上百T的数据规模。
- Adobe 每天的数据新增量规模为数T,数据总规模在几十PB左右。
- AWS 把 Iceberg 作为数据湖的底座。
- Cloudera 基于 Iceberg 构建自己整个公有云平台,像 Hadoop 这种 HDFS 私有化部署的趋势在减弱,上云的趋势逐步上升,Iceberg 在 Cloudera 数据架构上云的阶段中起到关键作用。
苹果有两个团队在使用:
- 一是整个 iCloud 数据平台基于 Iceberg 构建;
- 二是人工智能语音服务 Siri,也是基于 Flink 跟 Iceberg 来构建整个数据库的生态。
三、Flink 和 Iceberg 如何解决问题
回到最关键的内容,下面阐述 Flink 和 Iceberg 如何解决第一部分所遇到的一系列问题。
1. Case #1:程序 BUG 导致数据传输中断
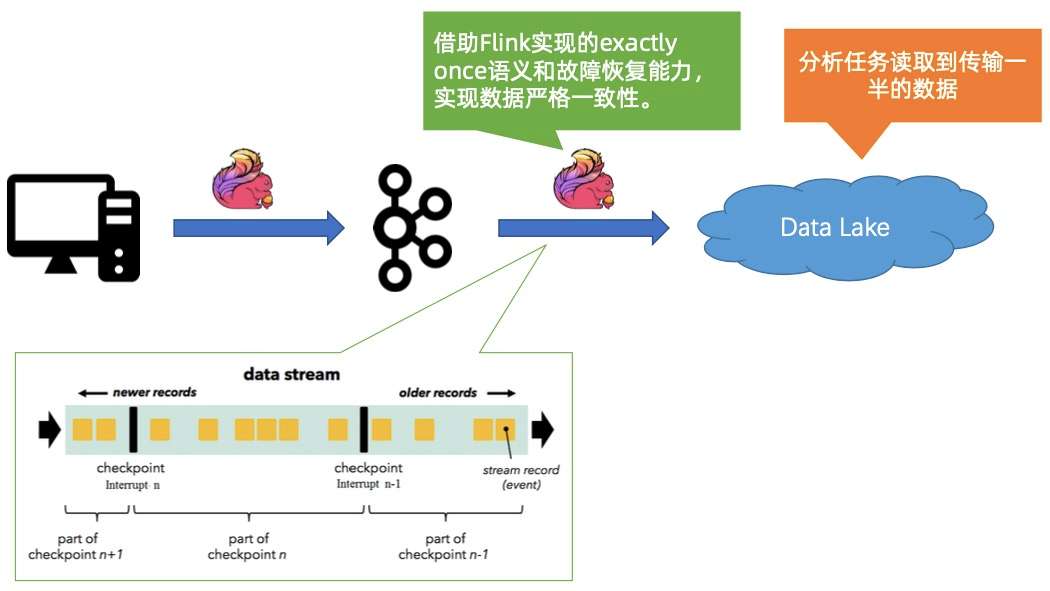
首先,同步链路用 Flink,可以保证 exactly once 的语义,当作业出现故障时,能够做严格的恢复,保证数据的一致性。
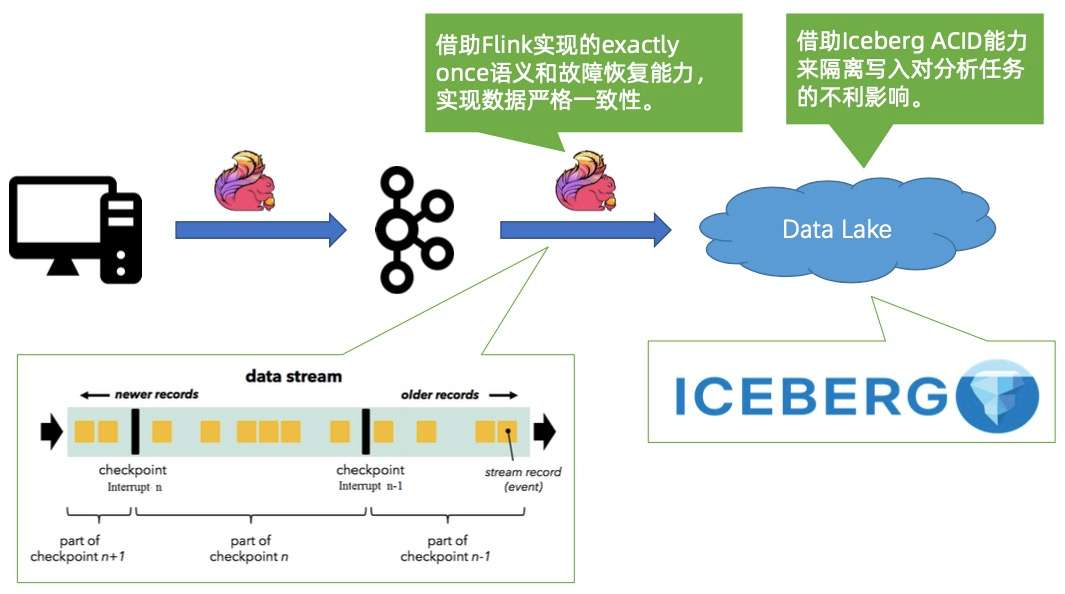
第二个是 Iceberg,它提供严谨的 ACID 语义,可以帮用户轻松隔离写入对分析任务的不利影响。
2. Case #2:数据变更太痛苦
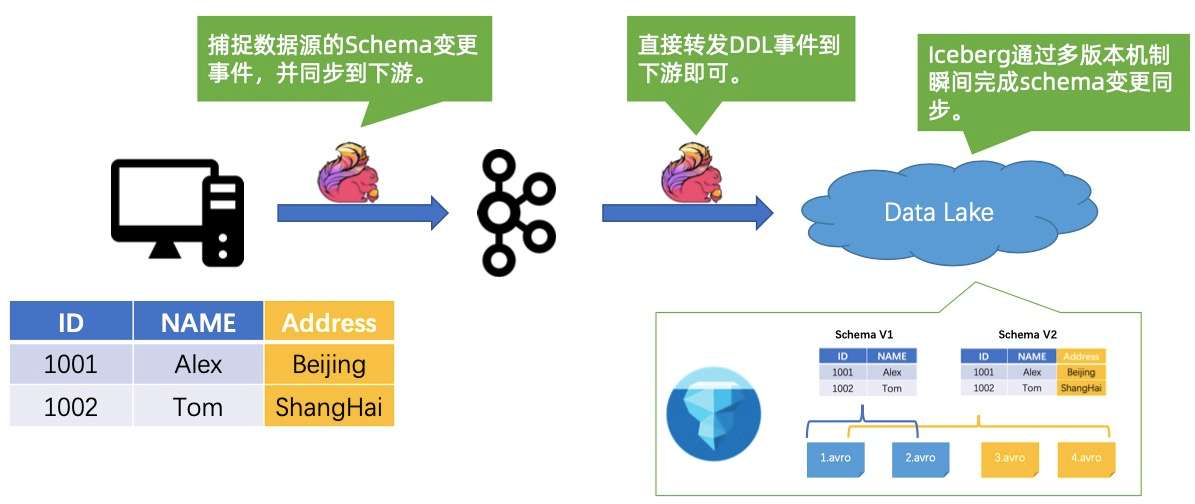
如上所示,当发生数据变更时,用 Flink 和 Iceberg 可以解决这个问题。
Flink 可以捕捉到上游 Schema 变更的事件,然后把这个事件同步到下游,同步之后下游的 Flink 直接把数据往下转发,转发之后到存储,Iceberg 可以瞬间把 Schema 给变更掉。
当做 Schema 这种 DDL 的时候,Iceberg 直接维护了多个版本的 Schema,然后老的数据源完全不动,新的数据写新的 Schema,实现一键 Schema 隔离。

另外一个例子是分区变更的问题,Iceberg 做法如上图所示。
之前按 “月” 做分区(上方黄色数据块),如果希望改成按 “天” 做分区,可以直接一键把 Partition 变更,原来的数据不变,新的数据全部按 “天” 进行分区,语义做到 ACID 隔离。
3. Case #3:越来越慢的近实时报表?

第三个问题是小文件对 Metastore 造成的压力。
首先对于 Metastore 而言,Iceberg 是把原数据统一存到文件系统里,然后用 metadata 的方式维护。整个过程其实是去掉了中心化的 Metastore,只依赖文件系统扩展,所以扩展性较好。
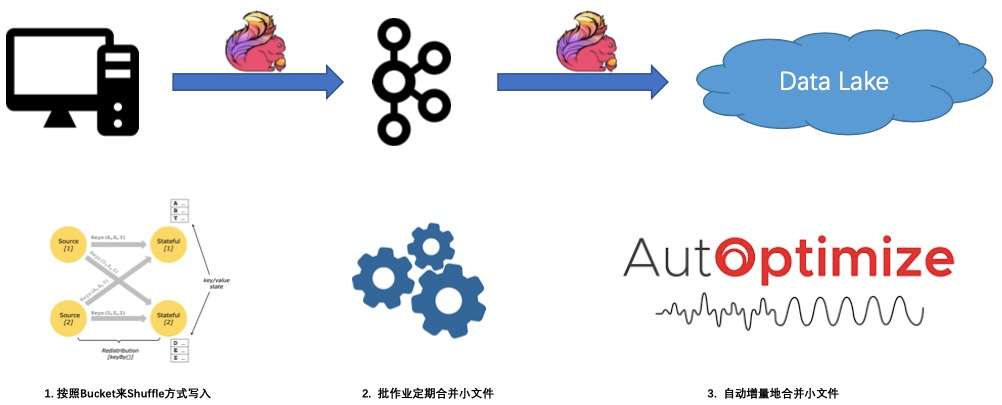
另一个问题是小文件越来越多,导致数据扫描会越来越慢。在这个问题上,Flink 和 Iceberg 提供了一系列解决方案:
- 第一个方案是在写入的时候优化小文件的问题,按照 Bucket 来 Shuffle 方式写入,因为 Shuffle 这个小文件,写入的文件就自然而然的小。
- 第二个方案是批作业定期合并小文件。
- 第三个方案相对智能,就是自动增量地合并小文件。
4. Case #4:实时地分析CDC数据很困难


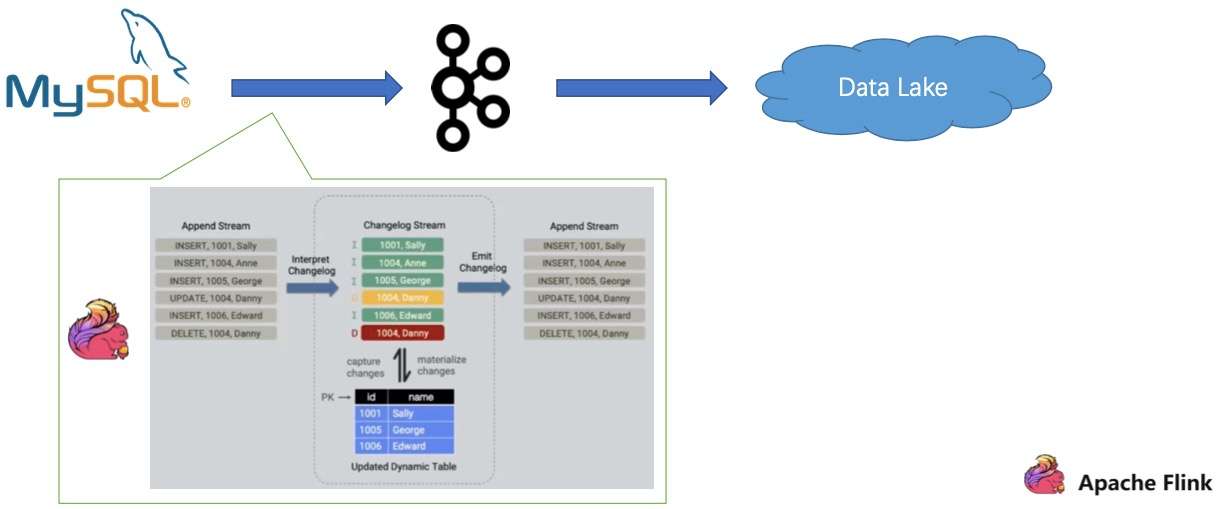
- 首先是是全量跟增量数据同步的问题,社区其实已有 Flink CDC Connected 方案,就是说 Connected 能够自动做全量跟增量的无缝衔接。
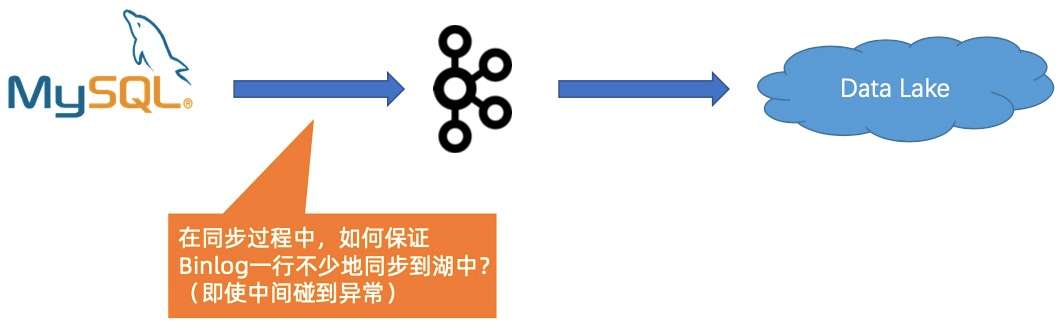
- 第二个问题是在同步过程中,如何保证 Binlog 一行不少地同步到湖中, 即使中间碰到异常。
对于这个问题,Flink 在 Engine 层面能够很好地识别不同类型的事件,然后借助 Flink 的 exactly once 的语义,即使碰到故障,它也能自动做恢复跟处理。
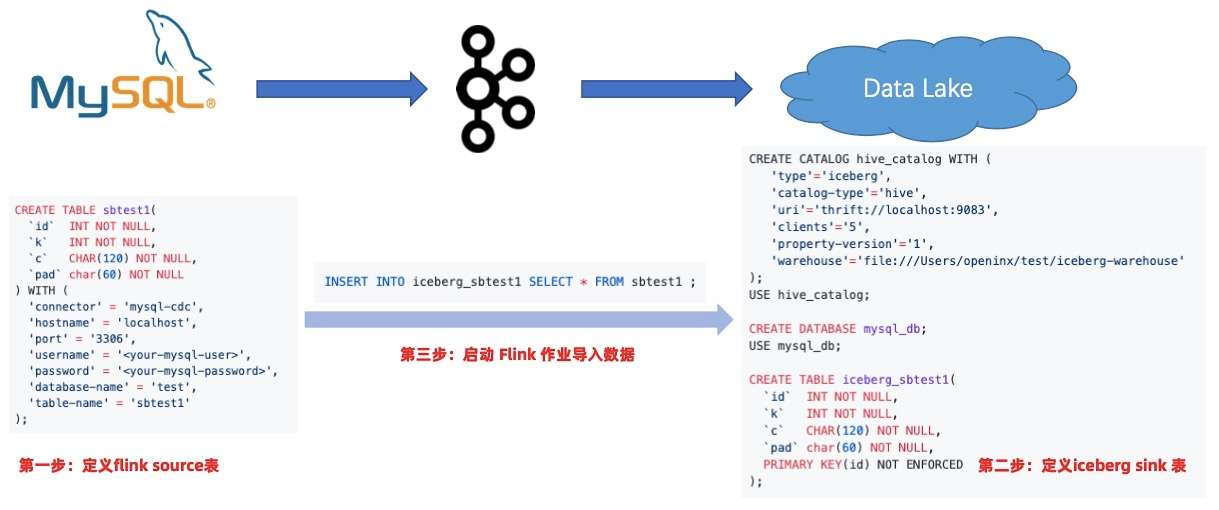
- 第三个问题是搭建整条链路需要做不少代码开发,门槛太高。
在用了 Flink 和 Data Lake 方案后,只需要写一个 source 表和 sink 表,然后一条 INSERT INTO,整个链路就可以打通,无需写任何业务代码。

- 最后是存储层面如何支持近实时的 CDC 数据分析。
四、社区 Roadmap
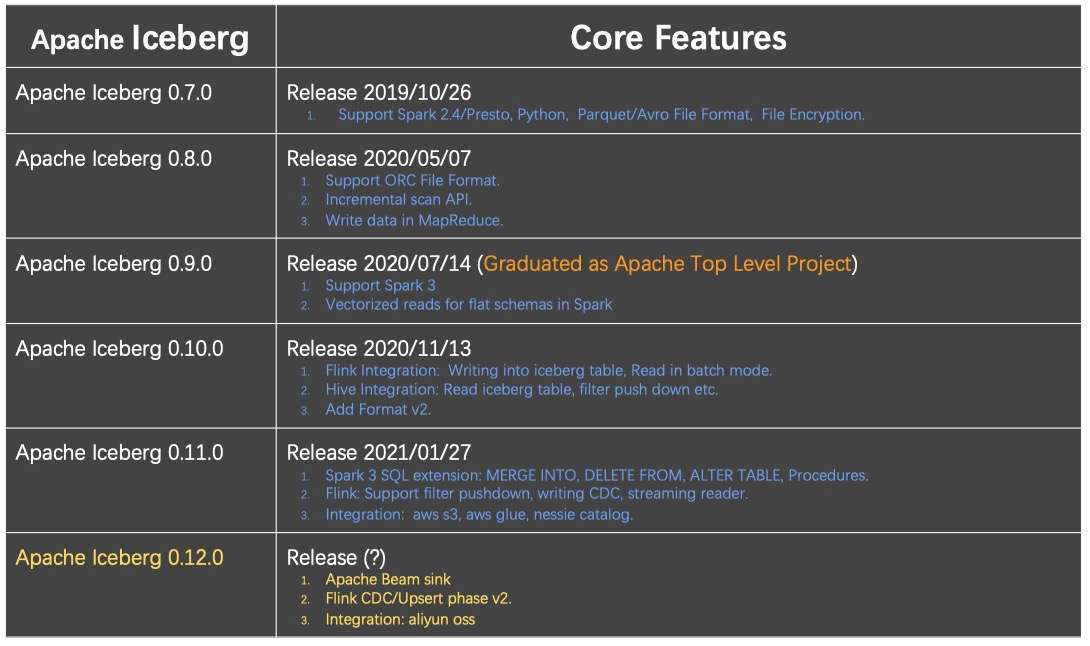
上图为 Iceberg 的 Roadmap,可以看到 Iceberg 在 2019 年只发了一个版本, 却在 2020 年直接发了三个版本,并在 0.9.0 版本就成为顶级项目。
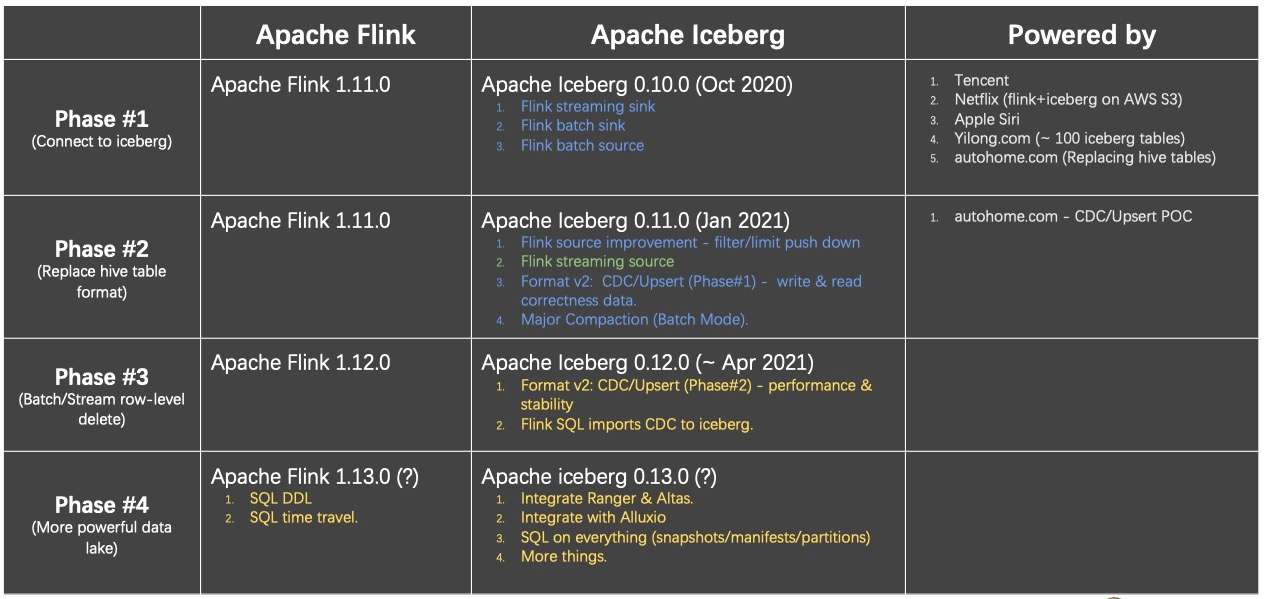
上图为 Flink 与 Iceberg 的 Roadmap,可以分为 4 个阶段。
- 第一个阶段是 Flink 与 Iceberg 建立连接。
- 第二阶段是 Iceberg 替换 Hive 场景。在这个场景下,有很多公司已经开始上线,落地自己的场景。
- 第三个阶段是通过 Flink 与 Iceberg 解决更复杂的技术问题。
- 第四个阶段是把这一套从单纯的技术方案,到面向更完善的产品方案角度去做。
本文为阿里云原创内容,未经允许不得转载。
Flink 和 Iceberg 如何解决数据入湖面临的挑战的更多相关文章
- 基于Apache Hudi 的CDC数据入湖
作者:李少锋 文章目录: 一.CDC背景介绍 二.CDC数据入湖 三.Hudi核心设计 四.Hudi未来规划 1. CDC背景介绍 首先我们介绍什么是CDC?CDC的全称是Change data Ca ...
- COS 数据湖最佳实践:基于 Serverless 架构的入湖方案
01 前言 数据湖(Data Lake)概念自2011年被推出后,其概念定位.架构设计和相关技术都得到了飞速发展和众多实践,数据湖也从单一数据存储池概念演进为包括 ETL 分析.数据转换及数据处理的下 ...
- C#中Timer使用及解决重入问题
C#中Timer使用及解决重入问题 ★介绍 首先简单介绍一下timer,这里所说的timer是指的System.Timers.timer,顾名思义,就是可以在指定的间隔是引发事件.官方介绍在这里,摘抄 ...
- Hadoop_22_MapReduce map端join实现方式解决数据倾斜(DistributedCache)
1.Map端Join解决数据倾斜 1.Mapreduce中会将map输出的kv对,按照相同key分组(调用getPartition),然后分发给不同的reducetask 2.Map输出结果的时候 ...
- Flink 实战:如何解决生产环境中的技术难题?
大数据作为未来技术的基石已成为国家基础性战略资源,挖掘数据无穷潜力,将算力推至极致是整个社会面临的挑战与难题. Apache Flink 作为业界公认为最好的流计算引擎,不仅仅局限于做流处理,而是一套 ...
- 压缩Sqlite数据文件大小,解决数据删除后占用空间不变的问题
最近有一网站使用Sqlite数据库作为数据临时性的缓存,对多片区进行划分 Sqlite数据库文件,每天大概新增近1万的数据量,起初效率有明显的提高,但历经一个多月后数据库文件从几K也上升到了近160M ...
- CodeFirst解决数据迁移问题
CodeFirst解决数据迁移问题 分类: 数据库 设计模式 c#2013-04-24 17:56 137人阅读 评论(0) 收藏 举报 工程用的MVC + Entity Framework,根据Co ...
- Spark性能调优之解决数据倾斜
Spark性能调优之解决数据倾斜 数据倾斜七种解决方案 shuffle的过程最容易引起数据倾斜 1.使用Hive ETL预处理数据 • 方案适用场景:如果导致数据倾斜的是Hive表.如果该Hiv ...
- [MapReduce_add_3] MapReduce 通过分区解决数据倾斜
0. 说明 数据倾斜及解决方法的介绍与代码实现 1. 介绍 [1.1 数据倾斜的含义] 大量数据发送到同一个节点进行处理,造成此节点繁忙甚至瘫痪,而其他节点资源空闲 [1.2 解决数据倾斜的方式] 重 ...
- react-native-echarts 解决数据刷新闪烁,不能动态连续绘制问题(转载)
最终能实现效果:动态绘制K线图,安卓,iOS正常显示 替换node_modules/native-echarts/src/components/Echarts/中的index.js和renderCha ...
随机推荐
- Django 使用 Nginx + uWSGI 启动
一.前言 购买了腾讯云服务器练习 Django 项目时, # 最开始用的启动 Django 项目命令 python3 manage.py runserver 0.0.0.0:80 后面发现我一旦把 x ...
- python高级技术(线程)
一 线程理论 1 有了进程为什么要有线程 进程有很多优点,它提供了多道编程,让我们感觉我们每个人都拥有自己的CPU和其他资源,可以提高计算机的利用率.很多人就不理解了,既然进程这么优秀,为什么还要线程 ...
- 为什么延迟删除可以保证MYSQL 与redis的一致性?
看过很多保持MYSQL 与redis保持一致性的文章都提到了延迟删除,其实脱离任何业务场景的设计都是不切实际的,所以我会本着一个通用的读写场景去分析为什么延迟删除大概率可以保证MYSQL与redis的 ...
- .net 开源混淆器 ConfuserEx
官网:http://yck1509.github.io/ConfuserEx/ 下载地址:https://github.com/yck1509/ConfuserEx/releases 使用参考:htt ...
- Linux Mint下Qt Creator无法输入中文解决办法
注,本文所指的是linux中使用fcitx输入框架下,Qt程序输入中文的解决办法 如果是ibus输入框架,则不需要任何操作,可以直接输入中文 但是微信使用的是fcitx输入框架,且比较常用,故只能使用 ...
- Windows下获取设备管理器列表信息-setupAPI
背景及问题: 在与硬件打交道时,经常需要知道当前设备连接的硬件信息,以便连接正确的硬件,比如串口通讯查询连接的硬件及端口,一般手工的方式就是去设备管理器查看相应的信息,应用程序如何读取这一部分信息呢, ...
- HTTP长连接和短链接代理与网关
长连接和短链接 代理与网关 HTTP/)服务器端网关:网关与客户端使用HTTP协议通信,使用其他协议与服务端通信 (/HTTP)客户端网关:网关与客户端使用其他协议通信,使用HTTP协议与服务端通信 ...
- #dp#洛谷 3473 [POI2008] UCI-The Great Escape JZOJ 4019 Path
题目 \(n*m\)的地图,计算从\((n,1)\)到第\(x\)列的第\(y\)行的路径条数\(\bmod k\) , 走过的点不能再走,转弯只能向右转.转弯完之后必须往前走一格 分析 可以发现,走 ...
- #KD-Tree#洛谷 4849 寻找宝藏
题目传送门 题目大意 在一个四维坐标系中,给定 \(n\) 个点,问有多少种选择点的方案, 使得这些点排序后任意坐标单调不降,并且选择的点权和最大,同时输出最大值 分析 设 \(f[i]\) 表示最后 ...
- 密码学系列之:IDEA
密码学系列之:IDEA 目录 简介 IDEA简介 IDEA原理 IDEA子密钥的生成 简介 IDEA的全称是International Data Encryption Algorithm,也叫做国际加 ...