[机器学习] k-近邻算法(knn)
最近在参加大数据的暑期培训,记录一下学习的东西。
引言
懒惰学习法:简单的存储数据,并且一直等待,直到给定一个检验数据,才进行范化,以便根据与存储的训练元组的相似性对该检验数据进行分类。懒惰学习法在 训练元组的时候只做少量的工作,而在进行分类或者数值预测时做更多的工作。由于懒惰学习法存储训练元组或实例,也被称为基于实例的学习法。
K-近邻算法是简单的分类与回归方法,属于懒惰学习法。
K-近邻算法的基本做法:给定一个训练数据集,在训练数据集中找到与未知实例最邻近的K个训练集中的实例,这K个实例的多数属于某个类,就把该未知实例分类到这个类中。
算法描述:
1、数据标准化
2、计算测试数据与各个训练数据之间的距离
3、按照距离的递增关系进行排序
4、选取距离最小的K个点
5、确定前K个点所在类别出现的频率
6、返回前K个点中出现频率最高的类别作为测试数据的预测分类
K近邻算法的三个基本要素:k值的选择,距离度量,分类决策规则
一、数据标准化
作用:防止某一属性权重过大
比如说坐标点 x,y。 x的范围是【0,1】,但y的范围却是【100,1000】,在进行距离的计算的时候y的权重比x的权重大。
这里就用最简单的一种标准化方法:
Min-max标准化: x‘ = (x -min)/(max-min)
举个例子:
x数据集为[1, 2, 3, 5], 则min=1, max=5
1 : (1-min) / (max-min) = 0
2 : (2-min) / (max-min) = 0.25
3 : (3-min) / (max-min) = 0.5
5 : (5 -min) / (max-min) = 1
则x数据集被更新为 x'[0, 0.25, 0.5, 1]
Min-max方法 x‘ 被标准化在[0,1]区间中
二、距离度量
计算两点间的距离:计算距离有欧式距离,曼哈顿距离等等, 一般采用欧式距离。
欧式距离公式 :
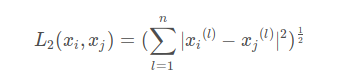
就比如(x1, y1)和 (x2, y2)的距离为

多维也是一样的,对应坐标相减,平方后,求和,再求根号
曼哈顿距离:
曼哈顿距离公式:
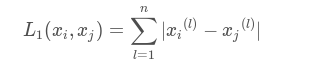
点(x1, y1)和(x2, y2)的曼哈顿距离为: |x1-x2| + |y1-y2|
多维为对应坐标相减的绝对值求和
根据需求选择不同的距离度量
三、确定K值
k值的选择会对k近邻法的结果有很大的影响,k值较小意味着只有与输入实例较近的训练实例才会对预测结果起作用,但容易发生过拟合;如果k值较大,优点是可以减少学习的估计误差,缺点是学习的近似值误差增大,这时与输入实例较远的训练实例也会起预测作用,使预测发生错误。在实际应用中,k值一般选择一个较小的数值,采用交叉验证的方法来选择最优的k值。
四、分类决策规则
分类决策规则是只按照什么规则确定当前实例属于哪一类。
k近邻算法中,分类决策规则往往是多数表决,即由输入实例的K个最邻近的训练实例中的多数类决定输入实例的类别。
五、优缺点
优点:简单,易于理解,无需建模与训练,易于实现;适合对稀有事件进行分类。
缺点:懒惰算法,内存开销大,对测试样本分类时计算量也比较大,性能较低;可解释性差,无法给出决策树那样的规则。
[机器学习] k-近邻算法(knn)的更多相关文章
- k近邻算法(KNN)
k近邻算法(KNN) 定义:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别. from sklearn.model_selection ...
- 机器学习(四) 分类算法--K近邻算法 KNN (上)
一.K近邻算法基础 KNN------- K近邻算法--------K-Nearest Neighbors 思想极度简单 应用数学知识少 (近乎为零) 效果好(缺点?) 可以解释机器学习算法使用过程中 ...
- 机器学习(四) 机器学习(四) 分类算法--K近邻算法 KNN (下)
六.网格搜索与 K 邻近算法中更多的超参数 七.数据归一化 Feature Scaling 解决方案:将所有的数据映射到同一尺度 八.scikit-learn 中的 Scaler preprocess ...
- 一看就懂的K近邻算法(KNN),K-D树,并实现手写数字识别!
1. 什么是KNN 1.1 KNN的通俗解释 何谓K近邻算法,即K-Nearest Neighbor algorithm,简称KNN算法,单从名字来猜想,可以简单粗暴的认为是:K个最近的邻居,当K=1 ...
- [机器学习] k近邻算法
算是机器学习中最简单的算法了,顾名思义是看k个近邻的类别,测试点的类别判断为k近邻里某一类点最多的,少数服从多数,要点摘录: 1. 关键参数:k值 && 距离计算方式 &&am ...
- Python3入门机器学习 - k近邻算法
邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一.所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代 ...
- 机器学习--K近邻 (KNN)算法的原理及优缺点
一.KNN算法原理 K近邻法(k-nearst neighbors,KNN)是一种很基本的机器学习方法. 它的基本思想是: 在训练集中数据和标签已知的情况下,输入测试数据,将测试数据的特征与训练集中对 ...
- 《机器学习实战》---第二章 k近邻算法 kNN
下面的代码是在python3中运行, # -*- coding: utf-8 -*- """ Created on Tue Jul 3 17:29:27 2018 @au ...
- k近邻算法(knn)的c语言实现
最近在看knn算法,顺便敲敲代码. knn属于数据挖掘的分类算法.基本思想是在距离空间里,如果一个样本的最接近的k个邻居里,绝大多数属于某个类别,则该样本也属于这个类别.俗话叫,"随大流&q ...
- 最基础的分类算法-k近邻算法 kNN简介及Jupyter基础实现及Python实现
k-Nearest Neighbors简介 对于该图来说,x轴对应的是肿瘤的大小,y轴对应的是时间,蓝色样本表示恶性肿瘤,红色样本表示良性肿瘤,我们先假设k=3,这个k先不考虑怎么得到,先假设这个k是 ...
随机推荐
- Qt实现长文件名(字符串)在QLabel中自适应缩短
一.应用场景简述 当在有限宽度的QLable中显示很长的文件名/字符串时,超出QLabel宽度部分将不会显示,此时采取缩短文件名策略(也可实现为字符串滚动动画)可以缓解这一问题.在实现这一想法的过程中 ...
- HTML续
HTML class属性 定义和用法 class 属性规定元素的类名(classname). class 属性大多数时候用于指向样式表中的类(class).不过,也可以利用它通过 JavaScript ...
- kafka笔记1
Kafka是一款基于发布和订阅的消息系统.一般被称为分布式提交日志或分布式流平台. Kafka系统是按照一定的顺序持久化保存的,可以按需读取. Kafka的数据单元被称为消息.类似于数据库中表的一行记 ...
- Spark之json数据处理
-- 默认情况下,SparkContext对象在spark-shell启动时用namesc初始化.使用以下命令创建SQLContext. val sqlcontext = new org.apache ...
- java统计文本中单词出现的个数
package com.java_Test; import java.io.File; import java.util.HashMap; import java.util.Iterator; imp ...
- ES 21 - Elasticsearch的高级检索语法 (包括term、prefix、wildcard、fuzzy、boost等)
目录 1 term query - 索引词检索 1.1 term query - 不分词检索 1.2 terms query - in检索 2 prefix query - 前缀检索 3 wildca ...
- Spring Boot:整合Spring Data JPA
综合概述 JPA是Java Persistence API的简称,是一套Sun官方提出的Java持久化规范.其设计目标主要是为了简化现有的持久化开发工作和整合ORM技术,它为Java开发人员提供了一种 ...
- 04-MySQL中的数据类型
1 整体说明MYsql的数据类型#1. 数字: 整型:tinyint int bigint 小数: float :在位数比较短的情况下不精准 double ...
- 【设计模式】行为型07备忘录模式(Memento Pattern)
参考地址:http://www.runoob.com/design-pattern/memento-pattern.html 对原文总结调整,以及修改代码以更清晰的展示: 备忘录模式(快照模式): ...
- auth-booster配置和使用(yii1.5)
auth-booster这个是一个yii框架扩展中的一个模块.是非常好用的(但是里面的说明都是英文的,所以国人用还需要改一点里面的汉化) 1.下载auth-booster这个:http://www.y ...