[机器学习] k-近邻算法(knn)
最近在参加大数据的暑期培训,记录一下学习的东西。
引言
懒惰学习法:简单的存储数据,并且一直等待,直到给定一个检验数据,才进行范化,以便根据与存储的训练元组的相似性对该检验数据进行分类。懒惰学习法在 训练元组的时候只做少量的工作,而在进行分类或者数值预测时做更多的工作。由于懒惰学习法存储训练元组或实例,也被称为基于实例的学习法。
K-近邻算法是简单的分类与回归方法,属于懒惰学习法。
K-近邻算法的基本做法:给定一个训练数据集,在训练数据集中找到与未知实例最邻近的K个训练集中的实例,这K个实例的多数属于某个类,就把该未知实例分类到这个类中。
算法描述:
1、数据标准化
2、计算测试数据与各个训练数据之间的距离
3、按照距离的递增关系进行排序
4、选取距离最小的K个点
5、确定前K个点所在类别出现的频率
6、返回前K个点中出现频率最高的类别作为测试数据的预测分类
K近邻算法的三个基本要素:k值的选择,距离度量,分类决策规则
一、数据标准化
作用:防止某一属性权重过大
比如说坐标点 x,y。 x的范围是【0,1】,但y的范围却是【100,1000】,在进行距离的计算的时候y的权重比x的权重大。
这里就用最简单的一种标准化方法:
Min-max标准化: x‘ = (x -min)/(max-min)
举个例子:
x数据集为[1, 2, 3, 5], 则min=1, max=5
1 : (1-min) / (max-min) = 0
2 : (2-min) / (max-min) = 0.25
3 : (3-min) / (max-min) = 0.5
5 : (5 -min) / (max-min) = 1
则x数据集被更新为 x'[0, 0.25, 0.5, 1]
Min-max方法 x‘ 被标准化在[0,1]区间中
二、距离度量
计算两点间的距离:计算距离有欧式距离,曼哈顿距离等等, 一般采用欧式距离。
欧式距离公式 :
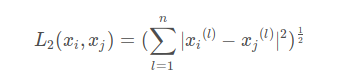
就比如(x1, y1)和 (x2, y2)的距离为

多维也是一样的,对应坐标相减,平方后,求和,再求根号
曼哈顿距离:
曼哈顿距离公式:
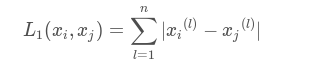
点(x1, y1)和(x2, y2)的曼哈顿距离为: |x1-x2| + |y1-y2|
多维为对应坐标相减的绝对值求和
根据需求选择不同的距离度量
三、确定K值
k值的选择会对k近邻法的结果有很大的影响,k值较小意味着只有与输入实例较近的训练实例才会对预测结果起作用,但容易发生过拟合;如果k值较大,优点是可以减少学习的估计误差,缺点是学习的近似值误差增大,这时与输入实例较远的训练实例也会起预测作用,使预测发生错误。在实际应用中,k值一般选择一个较小的数值,采用交叉验证的方法来选择最优的k值。
四、分类决策规则
分类决策规则是只按照什么规则确定当前实例属于哪一类。
k近邻算法中,分类决策规则往往是多数表决,即由输入实例的K个最邻近的训练实例中的多数类决定输入实例的类别。
五、优缺点
优点:简单,易于理解,无需建模与训练,易于实现;适合对稀有事件进行分类。
缺点:懒惰算法,内存开销大,对测试样本分类时计算量也比较大,性能较低;可解释性差,无法给出决策树那样的规则。
[机器学习] k-近邻算法(knn)的更多相关文章
- k近邻算法(KNN)
k近邻算法(KNN) 定义:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别. from sklearn.model_selection ...
- 机器学习(四) 分类算法--K近邻算法 KNN (上)
一.K近邻算法基础 KNN------- K近邻算法--------K-Nearest Neighbors 思想极度简单 应用数学知识少 (近乎为零) 效果好(缺点?) 可以解释机器学习算法使用过程中 ...
- 机器学习(四) 机器学习(四) 分类算法--K近邻算法 KNN (下)
六.网格搜索与 K 邻近算法中更多的超参数 七.数据归一化 Feature Scaling 解决方案:将所有的数据映射到同一尺度 八.scikit-learn 中的 Scaler preprocess ...
- 一看就懂的K近邻算法(KNN),K-D树,并实现手写数字识别!
1. 什么是KNN 1.1 KNN的通俗解释 何谓K近邻算法,即K-Nearest Neighbor algorithm,简称KNN算法,单从名字来猜想,可以简单粗暴的认为是:K个最近的邻居,当K=1 ...
- [机器学习] k近邻算法
算是机器学习中最简单的算法了,顾名思义是看k个近邻的类别,测试点的类别判断为k近邻里某一类点最多的,少数服从多数,要点摘录: 1. 关键参数:k值 && 距离计算方式 &&am ...
- Python3入门机器学习 - k近邻算法
邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一.所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代 ...
- 机器学习--K近邻 (KNN)算法的原理及优缺点
一.KNN算法原理 K近邻法(k-nearst neighbors,KNN)是一种很基本的机器学习方法. 它的基本思想是: 在训练集中数据和标签已知的情况下,输入测试数据,将测试数据的特征与训练集中对 ...
- 《机器学习实战》---第二章 k近邻算法 kNN
下面的代码是在python3中运行, # -*- coding: utf-8 -*- """ Created on Tue Jul 3 17:29:27 2018 @au ...
- k近邻算法(knn)的c语言实现
最近在看knn算法,顺便敲敲代码. knn属于数据挖掘的分类算法.基本思想是在距离空间里,如果一个样本的最接近的k个邻居里,绝大多数属于某个类别,则该样本也属于这个类别.俗话叫,"随大流&q ...
- 最基础的分类算法-k近邻算法 kNN简介及Jupyter基础实现及Python实现
k-Nearest Neighbors简介 对于该图来说,x轴对应的是肿瘤的大小,y轴对应的是时间,蓝色样本表示恶性肿瘤,红色样本表示良性肿瘤,我们先假设k=3,这个k先不考虑怎么得到,先假设这个k是 ...
随机推荐
- UWP-ListView到底部自动加载更多数据
原文:UWP-ListView到底部自动加载更多数据 ListView绑定的数据当需要“更多”时自动加载 ListView划到底部后,绑定的ObservableCollection列表数据需要加载的更 ...
- 给 Web 开发人员推荐的通用独立 UI 组件(二)
现代 Web 开发在将体验和功能做到极致的同时,对于美观的追求也越来越高.在推荐完图形库之后,再来推荐一些精品的独立 UI 组件.这些组件可组合在一起,形成美观而交互强大的 Web UI . 给 We ...
- 更换Qt QtEmbedded库的版本出现问题及解决(交叉编译OpenSSL)
近日将QtEmbedded库的版本由4.7.0更新到4.7.4.工具链并未改变,仍为 Target: arm-none-linux-gnueabiConfigured with: ......Thre ...
- java8计算时间差
示例1:计算指定时间单位的时间差 import java.time.Instant;import java.time.LocalDateTime;import java.time.temporal.C ...
- java中的String、StringBuffer、StringBuilder的区别
java中String.StringBuffer.StringBuilder是编程中经常使用的字符串类,他们之间的区别也是经常在面试中会问到的问题.现在总结一下,看看他们的不同与相同. 1.可变与不可 ...
- spark streaming 接收kafka消息之二 -- 运行在driver端的receiver
先从源码来深入理解一下 DirectKafkaInputDStream 的将 kafka 作为输入流时,如何确保 exactly-once 语义. val stream: InputDStream[( ...
- hgoi#20190628
更好的阅读体验 来我的博客观看 T1-打印收费 CZYZ 校园内有一家打印店,收费有着奇葩的规则,对于打印的量不同的情况会收取不同的费用.例如打印少于 100 张的时候,收取 20 分每张,但是打印不 ...
- 用composer安装php代码(以安装phpmailer为例)
1.安装composer.exe软件 2.下载composer.phar 3.创建composer.json文件 { "require": { "php": & ...
- Scala 学习之路(九)—— 继承和特质
一.继承 1.1 Scala中的继承结构 Scala中继承关系如下图: Any是整个继承关系的根节点: AnyRef包含Scala Classes和Java Classes,等价于Java中的java ...
- Spark学习之路(三)—— 弹性式数据集RDDs
弹性式数据集RDDs 一.RDD简介 RDD全称为Resilient Distributed Datasets,是Spark最基本的数据抽象,它是只读的.分区记录的集合,支持并行操作,可以由外部数据集 ...