Python3爬取豆瓣网电影信息
# -*- coding:utf-8 -*-
"""
一个简单的Python爬虫, 用于抓取豆瓣电影Top前250的电影的名称
Language: Python3.6
"""
import re
import urllib.request
import urllib.error
import time #import urllib2
import ssl ssl._create_default_https_context = ssl._create_unverified_context
class DouBanSpider(object):
"""类的简要说明
本类主要用于抓取豆瓣前100的电影名称 Attributes:
page: 用于表示当前所处的抓取页面
cur_url: 用于表示当前争取抓取页面的url
datas: 存储处理好的抓取到的电影名称
_top_num: 用于记录当前的top号码
""" def __init__(self):
self.page = 1
self.cur_url = "http://movie.douban.com/top250?start={page}&filter=&type="
self.datas = []
self._top_num = 1
print("豆瓣电影爬虫准备就绪, 准备爬取数据...") def get_page(self, cur_page):
"""
根据当前页码爬取网页HTML
Args:
cur_page: 表示当前所抓取的网站页码
Returns:
返回抓取到整个页面的HTML(unicode编码)
Raises:
URLError:url引发的异常
"""
url = self.cur_url
time.sleep(3) try:
#print(cur_page)
page = (cur_page - 1) * 25
#print(page)
url = url.format(page=page)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
}
request = urllib.request.Request(url, headers=headers)
my_page = urllib.request.urlopen(request).read().decode('utf-8') print("请求第{}页,url地址是:{}".format(cur_page,url)) #print(my_page)
#urllib.error.URLError #urllib.request.urlopen.URLError
except urllib.error.URLError as e:
if hasattr(e, "code"):
print("The server couldn't fulfill the request.")
print("Error code: %s" % e.code)
elif hasattr(e, "reason"):
print("We failed to reach a server. Please check your url and read the Reason")
print("Reason: %s" % e.reason)
return my_page def find_title(self, my_page):
"""
通过返回的整个网页HTML, 正则匹配前100的电影名称
Args:
my_page: 传入页面的HTML文本用于正则匹配
"""
temp_data = []
#<span class="title">.*</span>
#class="">[\s]+<span class="title">(.*?)</span>
#<span.*?class="title">(.*?)</span>
movie_items = re.findall(r'<span.*?class="title">(.*?)</span>', my_page, re.S)
for index, item in enumerate(movie_items):
if item.find(" ") == -1:
temp_data.append("Top" + str(self._top_num) + " " + item)
self._top_num += 1
self.datas.extend(temp_data) def start_spider(self):
"""
爬虫入口, 并控制爬虫抓取页面的范围
"""
while self.page <= 3: my_page = self.get_page(self.page)
self.find_title(my_page)
self.page += 1 def main():
print(
"""
######################################
一个简单的豆瓣电影前100爬虫
Author: Agoly
Version: Python3.6
Date: 2019-09-06
######################################
""")
my_spider = DouBanSpider()
my_spider.start_spider()
for item in my_spider.datas:
print(item)
print("豆瓣爬虫爬取结束...") if __name__ == '__main__':
main()

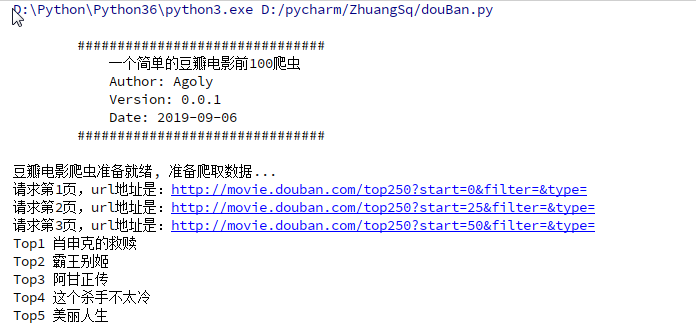
Python3爬取豆瓣网电影信息的更多相关文章
- requests爬取豆瓣top250电影信息
''' 1.爬取豆瓣top250电影信息 - 第一页: https://movie.douban.com/top250?start=0&filter= - 第二页: https://movie ...
- python3爬取豆瓣top250电影
需求:爬取豆瓣电影top250的排名.电影名称.评分.评论人数和一句话影评 环境:python3.6.5 准备工作: 豆瓣电影top250(第1页)网址:https://movie.douban.co ...
- 003.[python学习] 简单抓取豆瓣网电影信息程序
声明:本程序仅用于学习爬网页数据,不可用于其它用途. 本程序仍有很多不足之处,请读者不吝赐教. 依赖:本程序依赖BeautifulSoup4和lxml,如需正确运行,请先安装.下面是代码: #!/us ...
- 80 行代码爬取豆瓣 Top250 电影信息并导出到 CSV 及数据库
一.下载页面并处理 二.提取数据 观察该网站 html 结构 可知该页面下所有电影包含在 ol 标签下.每个 li 标签包含单个电影的内容. 使用 XPath 语句获取该 ol 标签 在 ol 标签中 ...
- 爬取豆瓣网图书TOP250的信息
爬取豆瓣网图书TOP250的信息,需要爬取的信息包括:书名.书本的链接.作者.出版社和出版时间.书本的价格.评分和评价,并把爬取到的数据存储到本地文件中. 参考网址:https://book.doub ...
- Node.js爬虫-爬取慕课网课程信息
第一次学习Node.js爬虫,所以这时一个简单的爬虫,Node.js的好处就是可以并发的执行 这个爬虫主要就是获取慕课网的课程信息,并把获得的信息存储到一个文件中,其中要用到cheerio库,它可以让 ...
- Python爬虫项目--爬取自如网房源信息
本次爬取自如网房源信息所用到的知识点: 1. requests get请求 2. lxml解析html 3. Xpath 4. MongoDB存储 正文 1.分析目标站点 1. url: http:/ ...
- 基础爬虫,谁学谁会,用requests、正则表达式爬取豆瓣Top250电影数据!
爬取豆瓣Top250电影的评分.海报.影评等数据! 本项目是爬虫中最基础的,最简单的一例: 后面会有利用爬虫框架来完成更高级.自动化的爬虫程序. 此项目过程是运用requests请求库来获取h ...
- Python 2.7_利用xpath语法爬取豆瓣图书top250信息_20170129
大年初二,忙完家里一些事,顺带有人交流爬取豆瓣图书top250 1.构造urls列表 urls=['https://book.douban.com/top250?start={}'.format(st ...
随机推荐
- Day01-基础数据类型/用户交互/流程控制之-if
1.基础数据类型 什么是数据类型 我们人类可以很容易的分清数字与字符的区别,但是计算机并不能,计算机虽然很强大,但从某种角度上看又很傻,除非你明确的告诉它,1是数字,“汉”是文字,否则它是分不清1和‘ ...
- 从AlexNet(2012)开始
目录 写在前面 网络结构 创新点 其他有意思的点 参考 博客:blog.shinelee.me | 博客园 | CSDN 写在前面 本文重点在于回顾深度神经网络在CV领域的First Blood--A ...
- 用Python在25行以下代码实现人脸识别
在本文中,我们将看到一种使用Python和开放源码库开始人脸识别的非常简单的方法. OpenCV OpenCV是最流行的计算机视觉库.最初是用C/C++编写的,现在它提供了Python的API. Op ...
- 剑指offer笔记面试题6----从未到头打印链表
题目:输入一个链表的头结点,从尾到头反过来打印出每个结点的值.链表节点定义如下: struct ListNode{ int m_nKey; ListNode* m_pNext; } 测试用例: 功能测 ...
- css里的背景属性有哪些,如何去使用哪些属性
分类:纯色背景 背景图像 1.背景颜色 background-color : 任意合法的颜色 和 transparent 2.背景图像 background-image : url(想要加载的图 ...
- Geoserver安装
准备内容 安装环境:win10*64位专业版 安装文件:geoserver-2.15.2 安装步骤 安装JDK 1.安装GeoServer是基于Java的环境,所以需要先装Jdk环境. 2.前往官网下 ...
- Java学习笔记 -- 头代码
每次写Java程序都会忘记这个main代码怎么写,特意把他写下来,之后忘了还可以温故而知新. 程序猿们请千万不要鄙视我o(╯□╰)o public static void main(String[] ...
- MySQL数据库~~~~ 完整性约束
1. not null 与 default not null : 不可空 default : 默认值 例: create table t1(id int not null default 2); 2. ...
- mysql5.7 找回密码
初次接触数据库,二进制安装了mysql5.7以后发现无法像yum一样在日志中找回初始密码~so 首先关掉启动的数据库: 在my.cnf中新增一句: skip-grant-tables 保存退出重启m ...
- 12C新功能:在线移动数据文件 (Doc ID 1566797.1)
12C New Feature : Move a Datafile Online (Doc ID 1566797.1) APPLIES TO: Oracle Database - Enterprise ...