Python爬取拉勾网招聘信息并写入Excel
这个是我想爬取的链接:http://www.lagou.com/zhaopin/Python/?labelWords=label
页面显示如下:
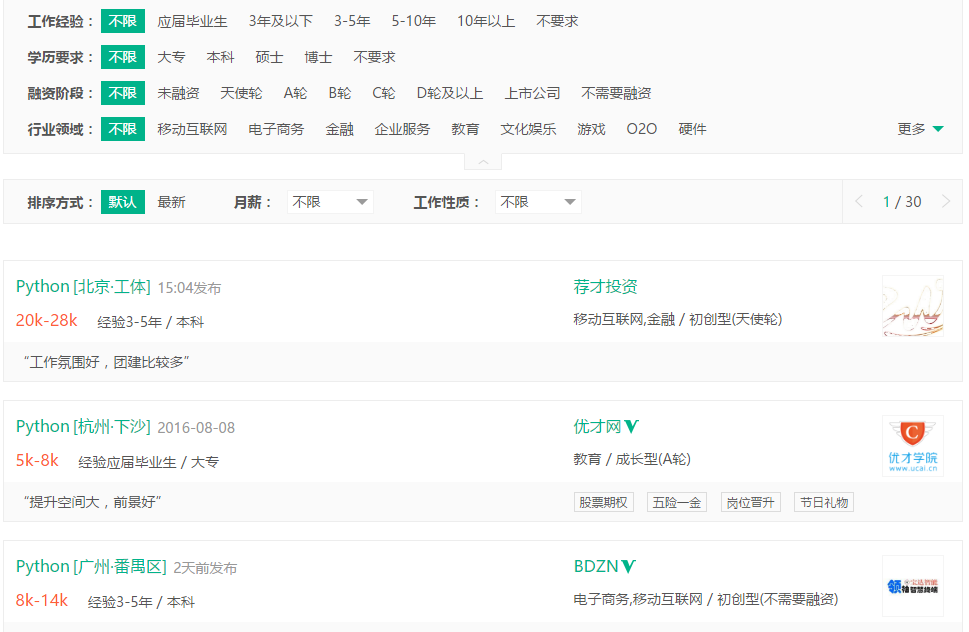
在Chrome浏览器中审查元素,找到对应的链接:

然后依次针对相应的链接(比如上面显示的第一个,链接为:http://www.lagou.com/jobs/2234309.html),打开之后查看,下面是我想具体爬取的每个公司岗位相关信息:
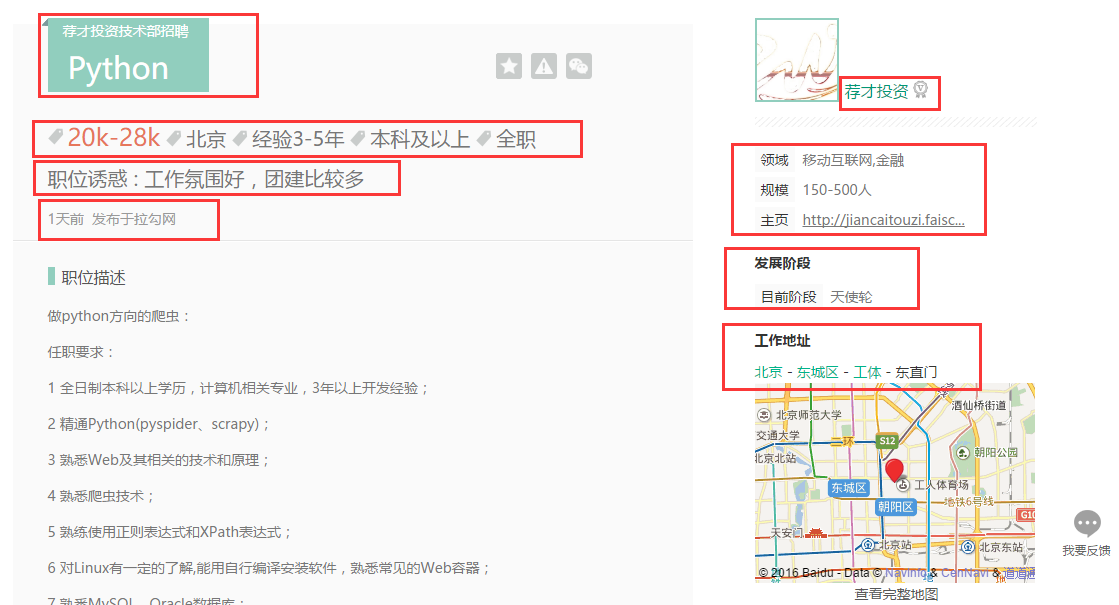
针对想要爬取的内容信息,找到html代码标签位置:
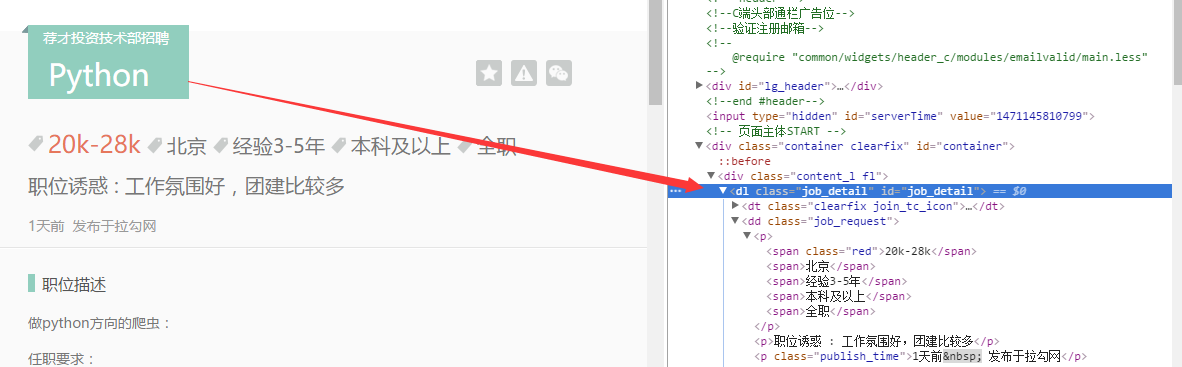
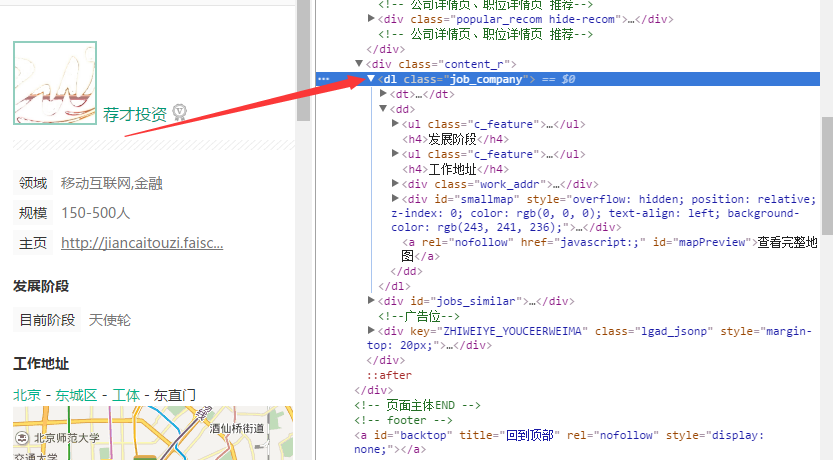
找到了相关的位置之后,就可以进行爬取的操作了。
以下是代码部分
# -*- coding:utf-8 -*- import urllib
import urllib2
from bs4 import BeautifulSoup
import re
import xlwt # initUrl = 'http://www.lagou.com/zhaopin/Python/?labelWords=label'
def Init(skillName):
totalPage = 30
initUrl = 'http://www.lagou.com/zhaopin/'
# skillName = 'Java'
userAgent = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36'
headers = {'User-Agent':userAgent} # create excel sheet
workBook = xlwt.Workbook(encoding='utf-8')
sheetName = skillName + ' Sheet'
bookSheet = workBook.add_sheet(sheetName)
rowStart = 0
for page in range(totalPage):
page += 1
print '##################################################### Page ',page,'#####################################################'
currPage = initUrl + skillName + '/' + str(page) + '/?filterOption=3'
# print currUrl
try:
request = urllib2.Request(currPage,headers=headers)
response = urllib2.urlopen(request)
jobData = readPage(response)
# rowLength = len(jobData)
for i,row in enumerate(jobData):
for j,col in enumerate(row):
bookSheet.write(rowStart + i,j,col)
rowStart = rowStart + i +1
except urllib2.URLError,e:
if hasattr(e,"code"):
print e.code
if hasattr(e,"reason"):
print e.reason
xlsName = skillName + '.xls'
workBook.save(xlsName) def readPage(response):
btfsp = BeautifulSoup(response.read())
webLinks = btfsp.body.find_all('div',{'class':'p_top'})
# webLinks = btfsp.body.find_all('a',{'class':'position_link'})
# print weblinks.text
count = 1
jobData = []
for link in webLinks:
print 'No.',count,'==========================================================================================='
pageUrl = link.a['href']
jobList = loadPage(pageUrl)
# print jobList
jobData.append(jobList)
count += 1
return jobData def loadPage(pageUrl):
currUrl = 'http:' + pageUrl
userAgent = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36'
headers = {'User-Agent':userAgent}
try:
request = urllib2.Request(currUrl,headers=headers)
response = urllib2.urlopen(request)
content = loadContent(response.read())
return content
except urllib2.URLError,e:
if hasattr(e,"code"):
print e.code
if hasattr(e,"reason"):
print e.reason def loadContent(pageContent):
# print pageContent
btfsp = BeautifulSoup(pageContent)
# job infomation
job_detail = btfsp.find('dl',{'id':'job_detail'})
jobInfo = job_detail.h1.text
tempInfo = re.split(r'(?:\s*)',jobInfo) # re.split is better than the Python's raw split function
jobTitle = tempInfo[1]
jobName = tempInfo[2]
job_request = job_detail.find('dd',{'class':'job_request'})
reqList = job_request.find_all('p')
jobAttract = reqList[1].text
publishTime = reqList[2].text
itemLists = job_request.find_all('span')
salary = itemLists[0].text
workplace = itemLists[1].text
experience = itemLists[2].text
education = itemLists[3].text
worktime = itemLists[4].text # company's infomation
jobCompany = btfsp.find('dl',{'class':'job_company'})
# companyName = jobCompany.h2
companyName = re.split(r'(?:\s*)',jobCompany.h2.text)[1]
companyInfo = jobCompany.find_all('li')
# workField = companyInfo[0].text.split(' ',1)
workField = re.split(r'(?:\s*)|(?:\n*)',companyInfo[0].text)[2]
# companyScale = companyInfo[1].text
companyScale = re.split(r'(?:\s*)|(?:\n*)',companyInfo[1].text)[2]
# homePage = companyInfo[2].text
homePage = re.split(r'(?:\s*)|(?:\n*)',companyInfo[2].text)[2]
# currStage = companyInfo[3].text
currStage = re.split(r'(?:\s*)|(?:\n*)',companyInfo[3].text)[1]
financeAgent = ''
if len(companyInfo) == 5:
# financeAgent = companyInfo[4].text
financeAgent = re.split(r'(?:\s*)|(?:\n*)',companyInfo[4].text)[1]
workAddress = ''
if jobCompany.find('div',{'class':'work_addr'}):
workAddress = jobCompany.find('div',{'class':'work_addr'})
workAddress = ''.join(workAddress.text.split()) # It's sooooo cool! # workAddress = jobCompany.find('div',{'class':'work_addr'})
# workAddress = ''.join(workAddress.text.split()) # It's sooooo cool! infoList = [companyName,jobTitle,jobName,salary,workplace,experience,education,worktime,jobAttract,publishTime,
workField,companyScale,homePage,workAddress,currStage,financeAgent] return infoList def SaveToExcel(pageContent):
pass if __name__ == '__main__':
# Init(userAgent)
Init('Python')
也是一边摸索一边来进行的,其中的一些代码写的不是很规范和统一。
结果显示如下:
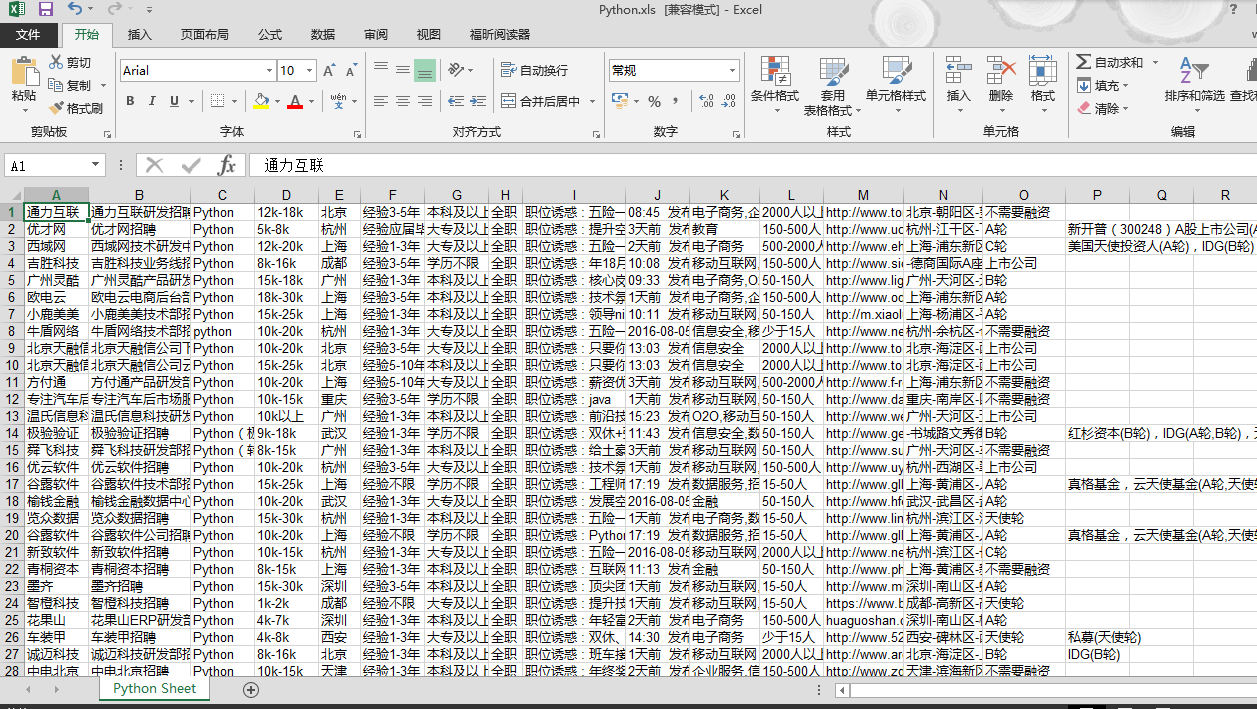
考虑打算下一步可以对相关的信息进行处理分析下,比如统计一下分布、薪资水平等之类的。
原文地址:http://www.cnblogs.com/leonwen/p/5769888.html
欢迎交流,请不要私自转载,谢谢
Python爬取拉勾网招聘信息并写入Excel的更多相关文章
- Python爬虫学习(二) ——————爬取前程无忧招聘信息并写入excel
作为一名Pythoner,相信大家对Python的就业前景或多或少会有一些关注.索性我们就写一个爬虫去获取一些我们需要的信息,今天我们要爬取的是前程无忧!说干就干!进入到前程无忧的官网,输入关键字&q ...
- 爬取拉勾网招聘信息并使用xlwt存入Excel
xlwt 1.3.0 xlwt 文档 xlrd 1.1.0 python操作excel之xlrd 1.Python模块介绍 - xlwt ,什么是xlwt? Python语言中,写入Excel文件的扩 ...
- python-scrapy爬虫框架爬取拉勾网招聘信息
本文实例为爬取拉勾网上的python相关的职位信息, 这些信息在职位详情页上, 如职位名, 薪资, 公司名等等. 分析思路 分析查询结果页 在拉勾网搜索框中搜索'python'关键字, 在浏览器地址栏 ...
- python爬取拉勾网职位信息-python相关职位
import requestsimport mathimport pandas as pdimport timefrom lxml import etree url = 'https://www.la ...
- (转)python爬取拉勾网信息
学习Python也有一段时间了,各种理论知识大体上也算略知一二了,今天就进入实战演练:通过Python来编写一个拉勾网薪资调查的小爬虫. 第一步:分析网站的请求过程 我们在查看拉勾网上的招聘信息的时候 ...
- 【图文详解】scrapy爬虫与动态页面——爬取拉勾网职位信息(2)
上次挖了一个坑,今天终于填上了,还记得之前我们做的拉勾爬虫吗?那时我们实现了一页的爬取,今天让我们再接再厉,实现多页爬取,顺便实现职位和公司的关键词搜索功能. 之前的内容就不再介绍了,不熟悉的请一定要 ...
- node.js爬虫爬取拉勾网职位信息
简介 用node.js写了一个简单的小爬虫,用来爬取拉勾网上的招聘信息,共爬取了北京.上海.广州.深圳.杭州.西安.成都7个城市的数据,分别以前端.PHP.java.c++.python.Androi ...
- python爬取拉勾网数据并进行数据可视化
爬取拉勾网关于python职位相关的数据信息,并将爬取的数据已csv各式存入文件,然后对csv文件相关字段的数据进行清洗,并对数据可视化展示,包括柱状图展示.直方图展示.词云展示等并根据可视化的数据做 ...
- python爬取豆瓣视频信息代码
目录 一:代码 二:结果如下(部分例子) 这里是爬取豆瓣视频信息,用pyquery库(jquery的python库). 一:代码 from urllib.request import quote ...
随机推荐
- Educational Codeforces Round 76 (Rated for Div. 2) E. The Contest dp
E. The Contest A team of three programmers is going to play a contest. The contest consists of
- Pytorch创建模型的多种方法
目录 Method 1 Method 2 Method 3 Method 4 Reference 网络结构: conv --> relu --> pool --> FC -- > ...
- IT兄弟连 Java语法教程 逻辑运算符
表8中显示的布尔逻辑运算符只能操作布尔类型的操作数,所有的二元逻辑运算符都可以组合两个布尔值,得到的结果为布尔类型. 表8 布尔逻辑运算符 布尔逻辑运算符”&“.”|“以及”^“,都会布尔值 ...
- tf.contrib.slim模块简介
原文连接:https://blog.csdn.net/MOU_IT/article/details/82717745 1.简介 对于tensorflow.contrib这个库,tensorflow官方 ...
- Ubuntu安装CUDA、CUDNN比较有用的网址总结
Ubuntu安装CUDA.CUDNN比较有用的网址总结 1.tensorflow各个版本所对应的的系统要求和CUDA\CUDNN适配版本 https://tensorflow.google.cn/in ...
- java报错问题记录
java.lang.NoSuchMethodError 运行时错误,再编译期一般不会出现这个问题.NoSuchMethodError中文意思是没有找到方法,遇到这个错误并不是说依赖的jar包.方法不存 ...
- javafx笔记----非javafx线程Platform.runLater赋值不生效情况
Platform.runLater(() -> { // }); Platform.runLater一些情况下没有赋值到fx页面上 采用task方式 Task<SB> task = ...
- JS基础语法---阶段复习+作业练习+接下来知识点heads up
调试:调试代码---高级程序员都是从调试开始的 调试: 写代码---打开浏览器--F12(开发人员工具)--->Sources---双击文件,在某一行代码前面点击一下(出现的东西就是断点) 一元 ...
- JS基础语法---循环语句之:for 循环 + 9个练习
for循环 语法: for(表达式1;表达式2;表达式3){ 循环体; } 执行过程: 先执行一次表达式1,然后判断表达式2;如果不成立则直接跳出循环 如果表达式2成立,执行循环体的代码,结束后,跳到 ...
- Tasteless challenges hard WP
hard Level 5- Fred CMS 十有八九是注入,不过测试引号和转义符并没发现什么,于是跑了下密码字典,竟然发现网页提示 sql injection detected! ,然后发现原来是密 ...