数据结构-详解优先队列的二叉堆(最大堆)原理、实现和应用-C和Python
一、堆的基础
1.1 优先队列和堆
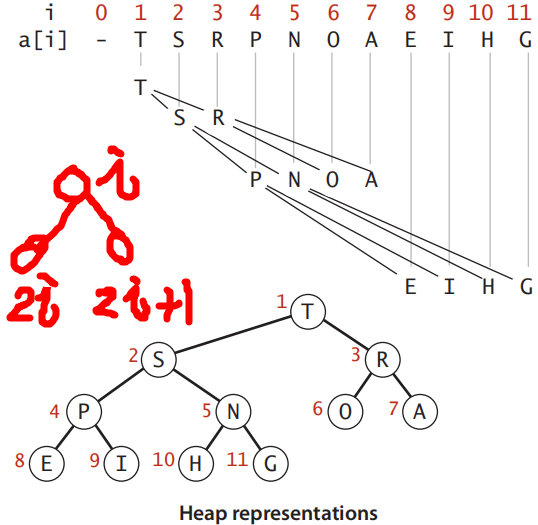
1.2 堆

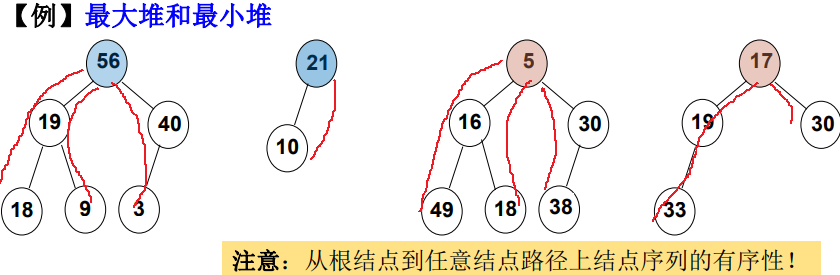
- 最大堆(MaxHeap), 也称“大顶堆”:根节点为最大值;
- 最小堆(MinHeap), 也称“小顶堆” :根节点为最小值。
二、最大堆实现
2.1 最大堆操作
- MaxHeap InitializeHeap( int MaxSize ):初始化一个空的最大堆。
- Boolean IsFull( MaxHeap H ):判断最大堆H是否已满。
- Boolean IsEmpty( MaxHeap H ):判断最大堆H是否为空。
- Insert( MaxHeap H, ElementType X ):将元素X插入最大堆H。
- ElementType DeleteMax( MaxHeap H ):返回H中最大元素(高优先级)。
- 自底向上reheapify(上滤,swim): 当某个节点的优先级增加时(或在堆的底部添加一个新节点)时,必须向上遍历调整堆以恢复堆序。
- 自顶向下reheapify(下滤, sink):当节点优先级减少(变小)时(例如,如果用键较小的新节点替换根上的节点),必须向下遍历调整堆以恢复堆顺。
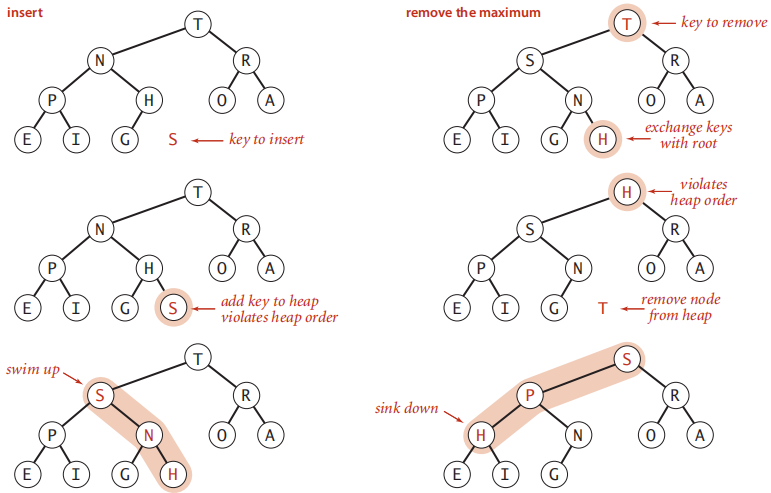
插入-插入元素索引上移,父节点值下移;
2.2 最大堆C实现
2.2.1 基本操作


#include <stdlib.h>
#include <stdIo.h>
typedef int ElementType;
typedef struct HNode *Heap; /* 堆的类型定义 */
struct HNode {
ElementType *Data; /* 存储元素的数组 */
int Size; /* 堆中当前元素个数 */
int Capacity; /* 堆的最大容量 */
};
typedef Heap MaxHeap; /* 最大堆 */
#define MAXDATA 1000000 /* 该值应根据具体情况定义为大于堆中所有可能元素的值 */
MaxHeap InitializeHeap( int MaxSize )
{ /* 创建容量为MaxSize的空的最大堆 */ MaxHeap H = (MaxHeap)malloc(sizeof(struct HNode));
/* 多一个元素存放"哨兵" */
H->Data = (ElementType *)malloc((MaxSize+1)*sizeof(ElementType)); H->Size = 0;
H->Capacity = MaxSize;
H->Data[0] = MAXDATA; /* 定义"哨兵"为大于堆中所有可能元素的值*/ return H;
}
判是否满堆,以及是否为空
bool IsFull( MaxHeap H )
{
return (H->Size == H->Capacity);
} bool IsEmpty( MaxHeap H )
{
return (H->Size == 0);
}
2.2.2 最大堆的插入
将新增结点插入到,从其父结点到根结点的有序序列中 ( 完全二叉树,插入时间复杂度O(logN) )

void Insert( MaxHeap H, ElementType X )
{ /* 将元素X插入最大堆H,其中H->Data[0]已经定义为哨兵 */
int i;
/* 首先判断,堆是否已满。已满则结束 */
if ( IsFull(H) ) {
printf("最大堆已满");
return;
} /* 若堆未满,i指向堆末尾的下一个位置(空穴,当前size+1),准备插入X */
i = ++H->Size; /* 类似插入排序, */
/* 若X 大于 其父节点值,则将父节点值下移至位置i, i位置(空穴)移到父节点位置[i/2] */
for ( ; H->Data[i/2] < X; i /= 2 )
H->Data[i] = H->Data[i/2]; /* 上滤X */ H->Data[i] = X; /* 将X插入 */
/* 若X是当前堆中最大元素,那么会在堆顶时(比哨兵小)终止上移 */
}
2.2.3 最大堆的删除
删除位置-根结点,返回堆顶(最大值)元素,并调整堆使其保持堆序性(少了一个元素)。
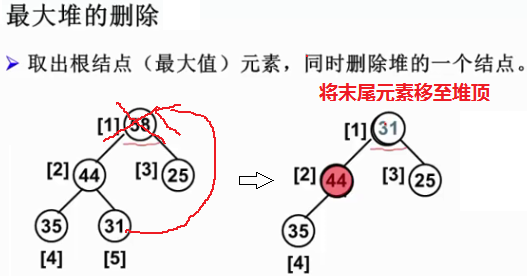
ElementType DeleteMax( MaxHeap H )
{ /* 从最大堆H中取出键值为最大的元素,并删除一个结点 */
int Parent, Child; /* 指针 */
ElementType MaxItem, X; if ( IsEmpty(H) ) {
printf("最大堆已为空"); /* 若堆已空,则结束(没得删) */
return ERROR;
} MaxItem = H->Data[1]; /* 取出根结点存放的最大值 */
/* 用最大堆中最后一个元素X,从根结点开始,向上过滤下层结点 */
X = H->Data[H->Size--]; /* 相当于删掉末尾元素位置,故当前堆size要减1*/ /* 迭代地将X和其更大的孩子节点值作比较,并调整位置(从根节点开始,给X找个位置) */
/* Parent*2 <= H->Size判断是否有左儿子(有无孩子),若无则超出堆空间,跳出循环,直接把X放Parent */
for ( Parent = 1; Parent*2 <= H->Size; Parent = Child ) {
/* 找到当前更大的孩子节点*/
Child = Parent * 2; /* 令Child为左儿子,经过外层for循环判断,Child只能 <= Parent */
/* 若有右儿子((Child < H->Size)),则让让Child指向左右子结点的较大者 */
if ( (Child != H->Size) && (H->Data[Child] < H->Data[Child+1]) )
Child++;
/* 将末尾元素X和Child的值比较,若X >= Child值则结束(有序了)*/
/* 若X < Child值 (Child更大),则将Child值放在位置Parent,并将Parent位置移到Child位置 */
if ( X >= H->Data[Child] )
break; /* 找到了合适位置 */
else /* Child元素上移,X移动到下一层(Parent = Child),继续和其孩子节点比较 */
H->Data[Parent] = H->Data[Child];
}
H->Data[Parent] = X; return MaxItem;
}
2.2.4 最大堆的建立
- 将N个元素按输入顺序存入,先满足完全二叉树的结构特性
- 调整各结点位置,以满足最大堆的有序特性
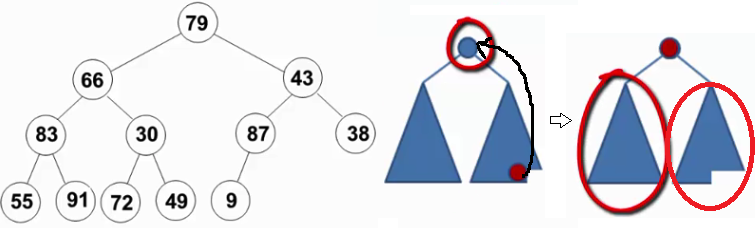
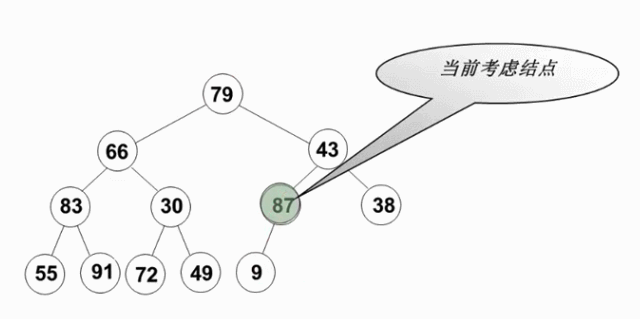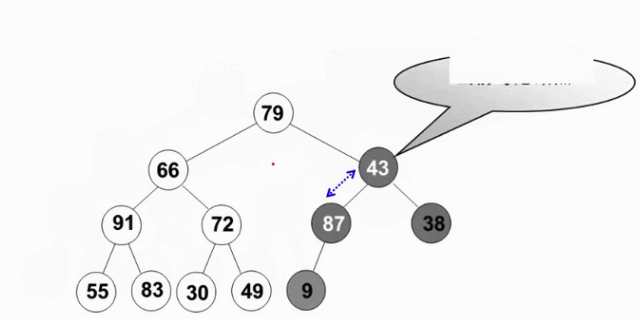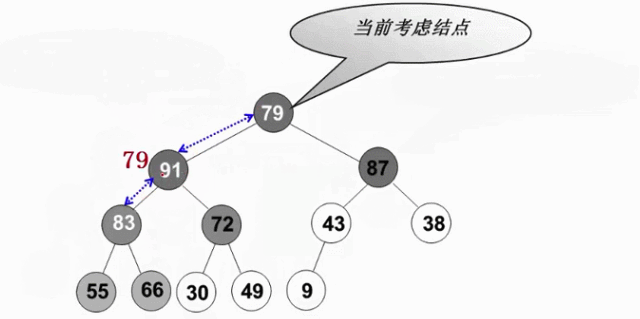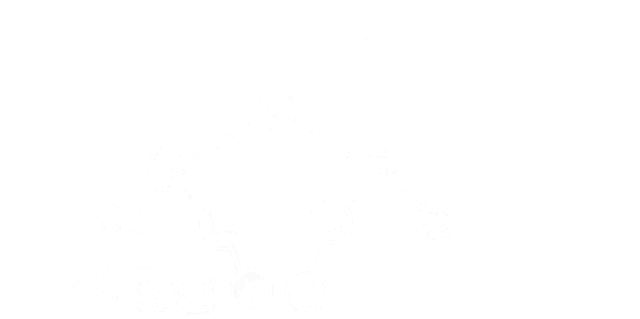
void PercolateDown( MaxHeap H, int p )
{ /* 下滤:将H中以H->Data[p]为根的子堆调整为最大堆 */
int Parent, Child;
ElementType X = H->Data[p]; /* 取出根结点存放的值 */
for ( Parent=p; Parent*2<=H->Size; Parent=Child ) {
Child = Parent * 2;
if ( (Child!=H->Size) && (H->Data[Child]<H->Data[Child+1]) )
Child++; /* Child指向左右子结点的较大者 */
if ( X >= H->Data[Child] ) break; /* 找到了合适位置 */
else /* 下滤X */
H->Data[Parent] = H->Data[Child];
}
H->Data[Parent] = X;
} void BuildHeap( MaxHeap H )
{ /* 调整H->Data[]中的元素,使满足最大堆的有序性 */
/* 这里假设所有H->Size个元素已经存在H->Data[]中 */ int i; /* 从最后一个结点的父节点开始,到根结点1 */
for ( i = H->Size/2; i > 0; i-- )
PercolateDown( H, i );
}
分析
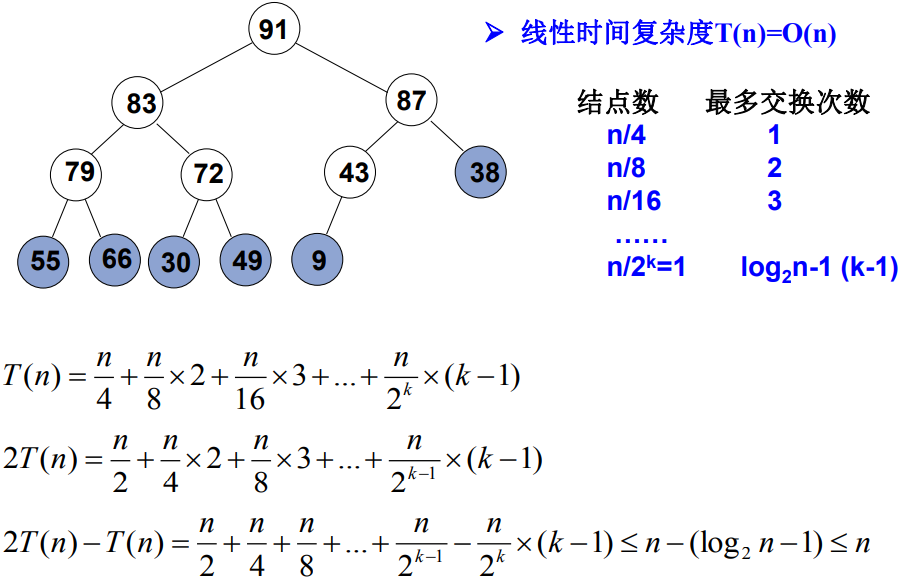
ElementType DeleteMax( MaxHeap H )
{ /* 从最大堆H中取出键值为最大的元素,并删除一个结点 */ ElementType MaxItem = H->Data[1]; /* 取出根结点存放的最大值 */ H->Data[1] = H->Data[H->Size--] /* 取出根结点存放的最大值 */ PercolateDown(H, 1); /* 从根结点开始,向上过滤下层结点(末尾节点下滤) */
return MaxItem;
}
2.3 最大堆Python实现
逻辑参照上述C语言版
class Heap:
def __init__(self, n):
self.capacity = n
self.size = 0
self.arr = [None] * (self.capacity+1)
self.arr[0] = 2e24 def insert(self, num):
if self.size == self.capacity:
print("Out of size")
else:
self.size += 1
child = self.size # 空穴位置
# 上滤, 当左儿子在堆范围内
while num > self.arr[child // 2]:
parent = child // 2
self.arr[child] = self.arr[parent]
child = parent self.arr[child] = num def pop(self):
if self.size == 0:
print("Empty")
else:
max_item = self.arr[1] # 取堆顶
x = self.arr[self.size] # 取堆末尾元素
self.size -= 1 parent = 1
# 下滤, 当左儿子在堆范围内
while parent * 2 <= self.size:
child = parent * 2
if child != self.size and self.arr[child+1] > self.arr[child]:
child += 1
if self.arr[child] > x:
self.arr[parent] = self.arr[child] # 孩子节点值上移
parent = child
else:
break
self.arr[parent] = x
return max_item
调用python包
import queue
, random class Heap():
def __init__(self, k):
if k > 0:
self.q = queue.PriorityQueue(k) def queue(self):
return self.q.queue def enque(self, key):
# 当前堆大小小于其容量
if self.q._qsize() < self.q.maxsize:
self.q.put(key)
else:
self.q.get() # 删除堆顶
self.q.put(key) def deque(self):
if not self.q.empty():
return self.q.get()
else:
print("Empty heap") h1 = Heap(10)
for i in range(15):
h1.enque(i) print(h1.queue()) # 最小堆,k 可得到堆排序得到最大的k个 l1 = [ random.randint(1, 100) for i in range(20)]
print(l1) for i in l1:
h1.enque(i) print(h1.queue())
print("\nPriority Queue:")
print([h1.deque() for i in range(h1.q._qsize())])
三、堆的应用
经典的应用有选择问题、堆排序和Huffman编码等等。
3.1. 选择问题
- 将N个元素读入数组,并构建最大堆O(N)
- 然后执行K次删除最大元素O(KlogN)
- 如果k小时,运行时间取决于建堆O(N)。
- 如果k大时,运行时间取决于删除O(KlogN)。例如K=N,即O(NlogN),直接堆排序
- 如果K=N/2,平均时间复杂度(NlogN)
- 将K个元素读入数组,并构建最小堆O(K)
- 依次删除最小堆的最小元素,再将元素插入最小堆(把待插入元素放在堆顶,然后下滤)O((N-K)logK)
3.2 堆排序
- 将N个元素读入数组,并构建最大堆O(N) Heap的原理和实现
- 然后,执行N-1次删除最大元素O(NlogN),返回的元素构成的数组有序
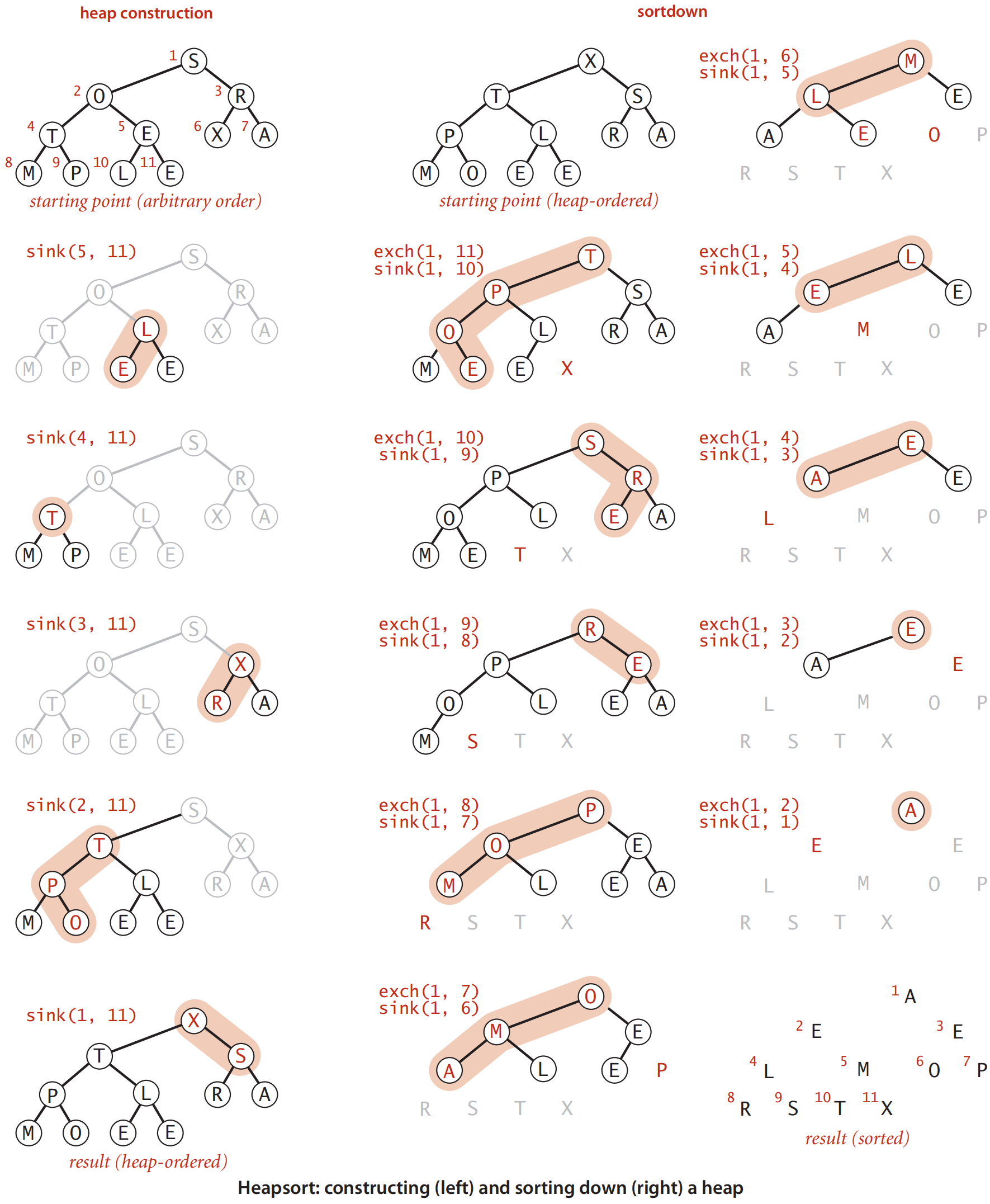
- 实际实现时,先自底向上调用N/2 + 1次下滤操作PercolateDown,线性建堆。
- 然后,每次把堆顶元素和堆末尾元素交换,将堆size减1,并从根节点执行下滤操作PercolateDown。共计N-1次(最后一个元素已经在堆顶,不需要操作)
def sortArray(nums: List[int]) -> List[int]:
import heapq
heapq.heapify(nums)
return [heapq.heappop(nums) for i in range(len(nums))]
Python实现
class Solution:
def sortArray(self, nums: List[int]) -> List[int]:
def heapify(nums, parent, arr_size):
# parent为开始下滤节点索引,p为当前堆大小(决定调整边界)
x = nums[parent]
# 下滤, 当左儿子在堆范围内
while parent * 2 + 1 < arr_size:
child = parent * 2 + 1
if child != arr_size-1 and nums[child+1] > nums[child]:
child += 1
if nums[child] > x:
nums[parent] = nums[child]
parent = child
else:
break
nums[parent] = x # 构建堆
n = len(nums)
for i in range(n//2, -1, -1):
heapify(nums, i, n) # 建堆时堆大小固定为其容量
# 迭代删除堆顶元素
for i in range(n-1, 0, -1):
# 将堆顶元素取出(直接在末尾存储),把末尾元素放堆顶
nums[i], nums[0] = nums[0], nums[i]
heapify(nums, 0, i) # 然后下滤
return nums
C实现
void PercolateDown( ElementType A[], int p, int N )
{
/* 将N个元素的数组中以A[p]为根的子堆调整为最大堆 */
int Parent, Child;
ElementType X = A[p]; /* 取出根结点存放的值 */
for ( Parent=p; (Parent*2+1) < N; Parent=Child ) {
Child = Parent * 2 + 1;
if ( (Child != N-1) && (A[Child] < A[Child+1]) )
Child++; /* Child指向左右子结点的较大者 */
if ( X >= A[Child] ) break; /* 找到了合适位置 */
else /* 下滤X */
A[Parent] = A[Child];
}
A[Parent] = X;
} void HeapSort( ElementType A[], int N )
{
int i;
/* 建立最大堆 */
for ( i = N/2-1; i >= 0; i-- )
PercolateDown( A, i, N ); for ( i=N-1; i>0; i-- ) {
/* 删除最大堆顶 */
Swap( &A[0], &A[i] );
PercolateDown( A, 0, i );
}
}
数据结构-详解优先队列的二叉堆(最大堆)原理、实现和应用-C和Python的更多相关文章
- 图论——Dijkstra+prim算法涉及到的优先队列(二叉堆)
[0]README 0.1)为什么有这篇文章?因为 Dijkstra算法的优先队列实现 涉及到了一种新的数据结构,即优先队列(二叉堆)的操作需要更改以适应这种新的数据结构,我们暂且吧它定义为Dista ...
- 数据结构图文解析之:二叉堆详解及C++模板实现
0. 数据结构图文解析系列 数据结构系列文章 数据结构图文解析之:数组.单链表.双链表介绍及C++模板实现 数据结构图文解析之:栈的简介及C++模板实现 数据结构图文解析之:队列详解与C++模板实现 ...
- 纯数据结构Java实现(6/11)(二叉堆&优先队列)
堆其实也是树结构(或者说基于树结构),一般可以用堆实现优先队列. 二叉堆 堆可以用于实现其他高层数据结构,比如优先队列 而要实现一个堆,可以借助二叉树,其实现称为: 二叉堆 (使用二叉树表示的堆). ...
- 优先队列之二叉堆与d-堆
二叉堆简介 平时所说的堆,若没加任何修饰,一般就是指二叉堆.同二叉树一样,堆也有两个性质,即结构性和堆序性.正如AVL树一样,对堆的以此操作可能破坏者两个性质中的一个,因此,堆的操作必须要到堆的所有性 ...
- PriorityBlockingQueue优先队列的二叉堆实现
转载请注明原创地址http://www.cnblogs.com/dongxiao-yang/p/6293807.html java.util.concurrent.PriorityBlockingQu ...
- 《Algorithms算法》笔记:优先队列(2)——二叉堆
二叉堆 1 二叉堆的定义 堆是一个完全二叉树结构(除了最底下一层,其他层全是完全平衡的),如果每个结点都大于它的两个孩子,那么这个堆是有序的. 二叉堆是一组能够用堆有序的完全二叉树排序的元素,并在数组 ...
- 优先队列的二叉堆Java实现
package practice; import edu.princeton.cs.algs4.StdRandom; public class TestMain { public static voi ...
- 数据结构与算法——优先队列类的C++实现(二叉堆)
优先队列简单介绍: 操作系统表明上看着是支持多个应用程序同一时候执行.其实是每一个时刻仅仅能有一个进程执行,操作系统会调度不同的进程去执行. 每一个进程都仅仅能执行一个固定的时间,当超过了该时间.操作 ...
- Python实现二叉堆
Python实现二叉堆 二叉堆是一种特殊的堆,二叉堆是完全二元树(二叉树)或者是近似完全二元树(二叉树).二叉堆有两种:最大堆和最小堆.最大堆:父结点的键值总是大于或等于任何一个子节点的键值:最小堆: ...
- 二叉堆(一)之 图文解析 和 C语言的实现
概要 本章介绍二叉堆,二叉堆就是通常我们所说的数据结构中"堆"中的一种.和以往一样,本文会先对二叉堆的理论知识进行简单介绍,然后给出C语言的实现.后续再分别给出C++和Java版本 ...
随机推荐
- Oracle性能优化之运行参数设置
Oracle参数调整建议值 sessions=2150 processes=2000 open_cursors=5120 db_file_multiblock_read_count=64 log_bu ...
- MLP(SGD or Adam) Perceptron Neural Network Working by Pytorch(including data preprocessing)
通过MLP多层感知机神经网络训练模型,使之能够根据sonar的六十个特征成功预测物体是金属还是石头.由于是简单的linearr线性仿射层,所以网络模型的匹配度并不高. 这是我的第一篇随笔,就拿这个来练 ...
- 搭建K8S集群前置条件
搭建K8S集群 搭建k8s环境平台规划 单master集群 单个master节点,然后管理多个node节点 多master集群 多个master节点,管理多个node节点,同时中间多了一个负载均衡的过 ...
- 带你了解S12直播中的“黑科技”
摘要:让精彩更流畅.让较量更清晰.让参与更沉浸.让体验更有趣,幕后的舞台,从来都是技术的战场,S12背后的名场面同样场场高能. 本文分享自华为云社区<用硬核方式打开S12名场面>,作者:华 ...
- Dubbo-聊聊Dubbo协议
前言 Dubbo源码阅读分享系列文章,欢迎大家关注点赞 SPI实现部分 Dubbo-SPI机制 Dubbo-Adaptive实现原理 Dubbo-Activate实现原理 Dubbo SPI-Wrap ...
- Android网络请求(3) 网络请求框架OkHttp
Android网络请求(3) 网络请求框架OkHttp 本节我们来讲解OkHtpp网络请求框架 什么是网络请求框架 在我的理解中,网络请求框架是为了方便我们更加便捷规范的进行网络请求所建的类,我们通过 ...
- Git同步操作
同步github数据 先要进入仓库文件夹 新建仓库文件夹要初始化或将远程仓库clone下来 git init或git clone https://github.com/用户名称/仓库名称.git 新建 ...
- redis集群之主从复制集群的原理和部署
最近在复盘redis的知识,所以本文开始希望介绍下redis的集群架构.原理以及部署:本文主要介绍redis的主从复制集群,包括其架构模型,原理,高可用等: 一.主从集群的介绍 redis的主从复 ...
- 2020最新Java面试题及答案(带完整目录).pdf
一.JVM 二.Java集合 三.Java多线程并发 四.Java基础 五.Spring原理 六.微服务 七.Netty与RPC 八.网络 九.日志 十.RabbitMQ 十一.MongoDB 十二. ...
- PW4052 是一颗适用于单节锂电池的、具有恒压/恒流充电模式的充电管理 IC
PW4052 是一颗适用于单节锂电池的.具有恒压/恒流充电模式的充电管理 IC.该芯片采用开关型的工作模式, 能够为单节锂电池提供快速. 高效且简单的充电管理解决方案.PW4052 采用三段式充电管理 ...