TVM:使用调度模板和AutoTVM优化算子
本节学习如何使用TVM 张量表达式(TE)语言来编写调度模板,这些模板可以被autoTVM搜索到,以找到最佳调度。这个过程称为auto-Tuning,它有助于优化张量计算的自动化过程。
本节建立在如何使用TE编写矩阵乘法的基础上
auto-tuning的步骤如下:
- 第一搜索空间
- 第二运行一个搜索算法来探索这个空间
Install dependencies
为在TVM使用autoTVM包,需要安装一些额外的依赖
pip3 install --user psutil xgboost cloudpickle
为了使 TVM 在 tuning 中运行得更快,建议使用 cython 作为 TVM 的 FFI。在 TVM 的根目录下,执行:
FFI:Foreign Function Interface,用一种编程语言写的程序能调用另一种编程语言写的函数
pip3 install --user cython
sudo make cython3
导入需要的库:
import logging
import sys
import numpy as np
import tvm
from tvm import te
import tvm.testing
# the module is called `autotvm`
from tvm import autotvm
Basic Matrix Multiplication with TE
用一个python函数定义来包装TE矩阵乘法。为简单起见,将注意力放在分割优化上,使用一个固定值来定义重新排序的块大小
def matmul_basic(N, L, M, dtype):
A = te.placeholder((N, L), name="A", dtype=dtype)
B = te.placeholder((L, M), name="B", dtype=dtype)
k = te.reduce_axis((0, L), name="k")
C = te.compute((N, M), lambda i, j: te.sum(A[i, k] * B[k, j], axis=k), name="C")
s = te.create_schedule(C.op)
# schedule
y, x = s[C].op.axis
k = s[C].op.reduce_axis[0]
yo, yi = s[C].split(y, 8)
xo, xi = s[C].split(x, 8)
s[C].reorder(yo, xo, k, yi, xi)
return s, [A, B, C]
Matrix Multiplication with AutoTVM
在上述就矩阵乘法代码中,使用常数“8”作为平铺系数(tiling factor)。这可能不是最好的,最佳的平铺系数取决于实际的硬件环境和输入形状。
如果想让调度代码在更大范围的输入形状和目标硬件上可移植,最好是定义一组候选值,并根据目标硬件上的测量结果挑选最佳值。
在 autotvm 中,我们可以定义一个可调整的参数,或者说是一个 “旋钮”,用于此类值。
# Matmul V1: List candidate values
@autotvm.template("tutorial/matmul_v1") # 1. use a decorator
def matmul_v1(N, L, M, dtype):
A = te.placeholder((N, L), name="A", dtype=dtype)
B = te.placeholder((L, M), name="B", dtype=dtype)
k = te.reduce_axis((0, L), name="k")
C = te.compute((N, M), lambda i, j: te.sum(A[i, k] * B[k, j], axis=k), name="C")
s = te.create_schedule(C.op)
# schedule
y, x = s[C].op.axis
k = s[C].op.reduce_axis[0]
# 2. get the config object
cfg = autotvm.get_config()
# 3. define search space
cfg.define_knob("tile_y", [1, 2, 4, 8, 16])
cfg.define_knob("tile_x", [1, 2, 4, 8, 16])
# 4. schedule according to config
yo, yi = s[C].split(y, cfg["tile_y"].val)
xo, xi = s[C].split(x, cfg["tile_x"].val)
s[C].reorder(yo, xo, k, yi, xi)
return s, [A, B, C]
在这里,我们对之前的调度代码做了四项修改,得到了一个可调度的 “模板”。我们可以逐一解释这些修改:
- 使用装饰器将这个函数标记为一个简单的模板。
- 获取 config 对象。以把这个
cfg看作是这个函数的一个参数,但可以以不同的方式获得它。有了这个参数,这个函数就不再是一个确定性的调度了。相反,我们可以向这个函数传递不同的配置,得到不同的调度。一个像这样使用配置对象的函数被称为 “模板”。
为了使模板函数更加紧凑,我们可以做两件事来定义单一函数中的参数搜索空间。
- 定义一个跨越一组数值的搜索空间。这是通过使
cfg成为一个ConfigSpace对象来实现的。它将收集这个函数中的所有可调控旋钮,并从中建立一个搜索空间。- 根据这个空间的一个实体来调度。这是通过使
cfg成为一个ConfigEntity对象来实现的。当它是一个ConfigEntity时,它将忽略所有空间定义 API(即cfg.define_XXXXX(...))。相反,它将为所有可调度的旋钮存储确定的值,我们根据这些值来调度。
在自动调度过程中,我们将首先用 ConfigSpace 对象调用该模板来构建搜索空间。然后,我们在构建的空间中用不同的 ConfigEntity 调用该模板,以获得不同的调度。最后,我们将测量不同调度所产生的代码,并挑选出最好的一个。
定义两个可调度的旋钮。第一个是
tile_y,有 5 个可能的值。第二个是tile_x,有相同的可能值列表。这两个旋钮是独立的,所以它们跨越了一个大小为 25=5x5 的搜索空间。配置旋钮被传递给
split调度操作,使我们能够根据我们先前在 cfg 中定义的 5x5 确定值来调度。
A Matrix Multiplication Template with the Advanced Parameter API
在前面的模板中,手动列出了一个旋钮的所有可能值。这是定义空间的最底层的 API,它给出了要搜索的参数空间的明确列举。然而,我们还提供了另一组 API,可以使搜索空间的定义更容易、更智能。在可能的情况下,我们接受你使用这个更高级别的 API。
在下面的例子中,我们使用 ConfigSpace.define_split 来定义一个分割旋钮。它将列举所有可能的方式来分割一个轴并构建空间。
还有ConfigSpace.define_reorder用于重新排序旋钮,以及 ConfigSpace.define_annotate 用于 unroll、矢量化、线程绑定等注释。当高级 API 不能满足您的要求时,您总是可以退回到使用低水平的 API。
@autotvm.template("tutorial/matmul")
def matmul(N, L, M, dtype):
A = te.placeholder((N, L), name="A", dtype=dtype)
B = te.placeholder((L, M), name="B", dtype=dtype)
k = te.reduce_axis((0, L), name="k")
C = te.compute((N, M), lambda i, j: te.sum(A[i, k] * B[k, j], axis=k), name="C")
s = te.create_schedule(C.op)
# schedule
y, x = s[C].op.axis
k = s[C].op.reduce_axis[0]
##### define space begin #####
cfg = autotvm.get_config()
cfg.define_split("tile_y", y, num_outputs=2)
cfg.define_split("tile_x", x, num_outputs=2)
##### define space end #####
# schedule according to config
yo, yi = cfg["tile_y"].apply(s, C, y)
xo, xi = cfg["tile_x"].apply(s, C, x)
s[C].reorder(yo, xo, k, yi, xi)
return s, [A, B, C]
PS:关于 cfg.define_split 的更多解释
在这个模板中,cfg.define_split("tile_y", y, num_outputs=2) 将列举所有能将轴 y 分割成两个轴的可能组合,其系数为 y 的长度。例如,如果 y 的长度是 32,我们想用 32 的因子将其分割成两个轴,那么(外轴的长度,内轴的长度)对有 6 种可能的值,即(32, 1), (16, 2), (8, 4), (4, 8), (2, 16) 或者 (1, 32)。这些都是 tile_y 的 6 种可能值。
在调度过程中,cfg["tile_y"] 是一个 SplitEntity 对象。我们将外轴和内轴的长度存储在 cfg['tile_y'].size 中(一个有两个元素的元组)。在这个模板中,我们通过使用 yo, yi = cfg['tile_y'].apply(s, C, y) 来应用它。实际上,这等同于 yo, yi = s[C].split(y, cfg["tile_y"].size[1]) 或者 yo, yi = s[C].split(y, nparts=cfg['tile_y"].size[0])
使用 cfg.apply API 的好处是,它使多级拆分(即 num_outputs >= 3 时)更容易。
Step 2: Use AutoTVM to Optimize the Matrix Multiplication
在步骤 1 中,我们编写了一个矩阵乘法模板,允许我们对分割调度中使用的块大小进行参数化。我们现在可以对这个参数空间进行搜索。下一步是选择一个调整器来指导对这个空间的探索。
Auto-tuners in TVM
调整工作如下伪代码所示:
ct = 0
while ct < max_number_of_trials:
propose a batch of configs
measure this batch of configs on real hardware and get results
ct += batch_size
当提出下一批配置的时候,tuner可以采取不同的策略。TVM 提供的一些调谐器策略包括:
tvm.autotvm.tuner.RandomTuner:以随机顺序枚举空间。tvm.autotvm.tuner.GridSearchTuner:以网格搜索的方式枚举空间。tvm.autotvm.tuner.GATuner:使用遗传算法来搜索空间tvm.autotvm.tuner.XGBTuner:使用一个基于模型的方法。训练一个 XGBoost 模型来预测降低 IR 的速度,并根据预测结果挑选下一批。
可以根据你的空间大小、你的时间预算和其他因素来选择调谐器。例如,如果你的空间非常小(小于 1000),网格搜索调谐器或随机调谐器就足够好了。如果你的空间在 的水平(这是 CUDA GPU 上 conv2d 运算器的空间大小),XGBoostTuner 可以更有效地探索并找到更好的配置。
Begin tuning
首先,创建一个tuning task,也可以检查初始化空间。在本例子中,对于一个512 * 512的矩阵乘法,空间大小玩10 * 10 = 100.注意这个task与搜索空间与所选的tuner无关。
N, L, M = 512, 512, 512
task = autotvm.task.create("tutorial/matmul", args=(N, L, M, "float32"), target="llvm")
print(task.config_space)
输出结果:
ConfigSpace (len=100, space_map=
0 tile_y: Split(policy=factors, product=512, num_outputs=2) len=10
1 tile_x: Split(policy=factors, product=512, num_outputs=2) len=10
)
然后,需要定义一个怎样衡量生产的代码和挑选的tuner。因为我们的空间很小,随机的tuner就可以了
在实践中,你可以根据你的时间预算做更多的试验。我们将把调谐结果记录到一个日志文件中。这个文件可以用来选择调谐器以后发现的最佳配置。
# logging config (for printing tuning log to the screen)
logging.getLogger("autotvm").setLevel(logging.DEBUG)
logging.getLogger("autotvm").addHandler(logging.StreamHandler(sys.stdout))
衡量一个配置有两步:构建和运行。默认情况下,使用所有的CPU核心来编译程序。然后按顺序衡量。为减少差异,这里进行了5次衡量并取平均
measure_option = autotvm.measure_option(builder="local", runner=autotvm.LocalRunner(number=5))
# Begin tuning with RandomTuner, log records to file `matmul.log`
# You can use alternatives like XGBTuner.
tuner = autotvm.tuner.RandomTuner(task)
tuner.tune(
n_trial=10,
measure_option=measure_option,
callbacks=[autotvm.callback.log_to_file("matmul.log")],
)
输出结果:
waiting for device...
waiting for device...
device available
device available
Get devices for measurement successfully!
Get devices for measurement successfully!
No: 1 GFLOPS: 8.17/8.17 result: MeasureResult(costs=(0.0328701162,), error_no=MeasureErrorNo.NO_ERROR, all_cost=0.6089231967926025, timestamp=1658363130.4992497) [('tile_y', [-1, 16]), ('tile_x', [-1, 16])],None,44
No: 1 GFLOPS: 8.17/8.17 result: MeasureResult(costs=(0.0328701162,), error_no=MeasureErrorNo.NO_ERROR, all_cost=0.6089231967926025, timestamp=1658363130.4992497) [('tile_y', [-1, 16]), ('tile_x', [-1, 16])],None,44
No: 2 GFLOPS: 7.45/8.17 result: MeasureResult(costs=(0.0360509632,), error_no=MeasureErrorNo.NO_ERROR, all_cost=0.695908784866333, timestamp=1658363131.2425098) [('tile_y', [-1, 8]), ('tile_x', [-1, 16])],None,43
No: 2 GFLOPS: 7.45/8.17 result: MeasureResult(costs=(0.0360509632,), error_no=MeasureErrorNo.NO_ERROR, all_cost=0.695908784866333, timestamp=1658363131.2425098) [('tile_y', [-1, 8]), ('tile_x', [-1, 16])],None,43
No: 3 GFLOPS: 25.86/25.86 result: MeasureResult(costs=(0.010381651799999999,), error_no=MeasureErrorNo.NO_ERROR, all_cost=0.3583974838256836, timestamp=1658363131.6205783) [('tile_y', [-1, 32]), ('tile_x', [-1, 128])],None,75
No: 3 GFLOPS: 25.86/25.86 result: MeasureResult(costs=(0.010381651799999999,), error_no=MeasureErrorNo.NO_ERROR, all_cost=0.3583974838256836, timestamp=1658363131.6205783) [('tile_y', [-1, 32]), ('tile_x', [-1, 128])],None,75
No: 4 GFLOPS: 30.35/30.35 result: MeasureResult(costs=(0.0088443436,), error_no=MeasureErrorNo.NO_ERROR, all_cost=0.31720852851867676, timestamp=1658363131.9254267) [('tile_y', [-1, 1]), ('tile_x', [-1, 64])],None,60
No: 4 GFLOPS: 30.35/30.35 result: MeasureResult(costs=(0.0088443436,), error_no=MeasureErrorNo.NO_ERROR, all_cost=0.31720852851867676, timestamp=1658363131.9254267) [('tile_y', [-1, 1]), ('tile_x', [-1, 64])],None,60
No: 5 GFLOPS: 9.35/30.35 result: MeasureResult(costs=(0.028700182600000002,), error_no=MeasureErrorNo.NO_ERROR, all_cost=0.7562305927276611, timestamp=1658363132.5526962) [('tile_y', [-1, 16]), ('tile_x', [-1, 128])],None,74
No: 5 GFLOPS: 9.35/30.35 result: MeasureResult(costs=(0.028700182600000002,), error_no=MeasureErrorNo.NO_ERROR, all_cost=0.7562305927276611, timestamp=1658363132.5526962) [('tile_y', [-1, 16]), ('tile_x', [-1, 128])],None,74
No: 6 GFLOPS: 28.15/30.35 result: MeasureResult(costs=(0.0095366542,), error_no=MeasureErrorNo.NO_ERROR, all_cost=0.29946398735046387, timestamp=1658363132.9198403) [('tile_y', [-1, 8]), ('tile_x', [-1, 512])],None,93
No: 6 GFLOPS: 28.15/30.35 result: MeasureResult(costs=(0.0095366542,), error_no=MeasureErrorNo.NO_ERROR, all_cost=0.29946398735046387, timestamp=1658363132.9198403) [('tile_y', [-1, 8]), ('tile_x', [-1, 512])],None,93
No: 7 GFLOPS: 19.80/30.35 result: MeasureResult(costs=(0.0135571626,), error_no=MeasureErrorNo.NO_ERROR, all_cost=0.30517101287841797, timestamp=1658363133.3043413) [('tile_y', [-1, 512]), ('tile_x', [-1, 512])],None,99
No: 7 GFLOPS: 19.80/30.35 result: MeasureResult(costs=(0.0135571626,), error_no=MeasureErrorNo.NO_ERROR, all_cost=0.30517101287841797, timestamp=1658363133.3043413) [('tile_y', [-1, 512]), ('tile_x', [-1, 512])],None,99
No: 8 GFLOPS: 5.75/30.35 result: MeasureResult(costs=(0.0467114476,), error_no=MeasureErrorNo.NO_ERROR, all_cost=0.8827676773071289, timestamp=1658363134.2409544) [('tile_y', [-1, 8]), ('tile_x', [-1, 32])],None,53
No: 8 GFLOPS: 5.75/30.35 result: MeasureResult(costs=(0.0467114476,), error_no=MeasureErrorNo.NO_ERROR, all_cost=0.8827676773071289, timestamp=1658363134.2409544) [('tile_y', [-1, 8]), ('tile_x', [-1, 32])],None,53
No: 9 GFLOPS: 27.67/30.35 result: MeasureResult(costs=(0.0097023816,), error_no=MeasureErrorNo.NO_ERROR, all_cost=0.38503575325012207, timestamp=1658363134.582773) [('tile_y', [-1, 2]), ('tile_x', [-1, 128])],None,71
No: 9 GFLOPS: 27.67/30.35 result: MeasureResult(costs=(0.0097023816,), error_no=MeasureErrorNo.NO_ERROR, all_cost=0.38503575325012207, timestamp=1658363134.582773) [('tile_y', [-1, 2]), ('tile_x', [-1, 128])],None,71
No: 10 GFLOPS: 2.62/30.35 result: MeasureResult(costs=(0.1026008602,), error_no=MeasureErrorNo.NO_ERROR, all_cost=1.708867073059082, timestamp=1658363136.3652241) [('tile_y', [-1, 8]), ('tile_x', [-1, 1])],None,3
No: 10 GFLOPS: 2.62/30.35 result: MeasureResult(costs=(0.1026008602,), error_no=MeasureErrorNo.NO_ERROR, all_cost=1.708867073059082, timestamp=1658363136.3652241) [('tile_y', [-1, 8]), ('tile_x', [-1, 1])],None,3
tuning完成后,从日志文件中选出就v有最佳测量性能的配置,并用相应的参数来编译schedule.也可以 做一个快速验证,以确保schedule产生正确的答案。可以autotvm.apply_history_best上下文下直接调用matmul函数。当调用这个函数时,它将以其参数查询调度上下文,并以相同的参数获得最佳配置。
# apply history best from log file
with autotvm.apply_history_best("matmul.log"):
with tvm.target.Target("llvm"):
s, arg_bufs = matmul(N, L, M, "float32")
func = tvm.build(s, arg_bufs)
# check correctness
a_np = np.random.uniform(size=(N, L)).astype(np.float32)
b_np = np.random.uniform(size=(L, M)).astype(np.float32)
c_np = a_np.dot(b_np)
c_tvm = tvm.nd.empty(c_np.shape)
func(tvm.nd.array(a_np), tvm.nd.array(b_np), c_tvm)
tvm.testing.assert_allclose(c_np, c_tvm.numpy(), rtol=1e-4)
输出结果:
Finish loading 10 records
Finish loading 10 records
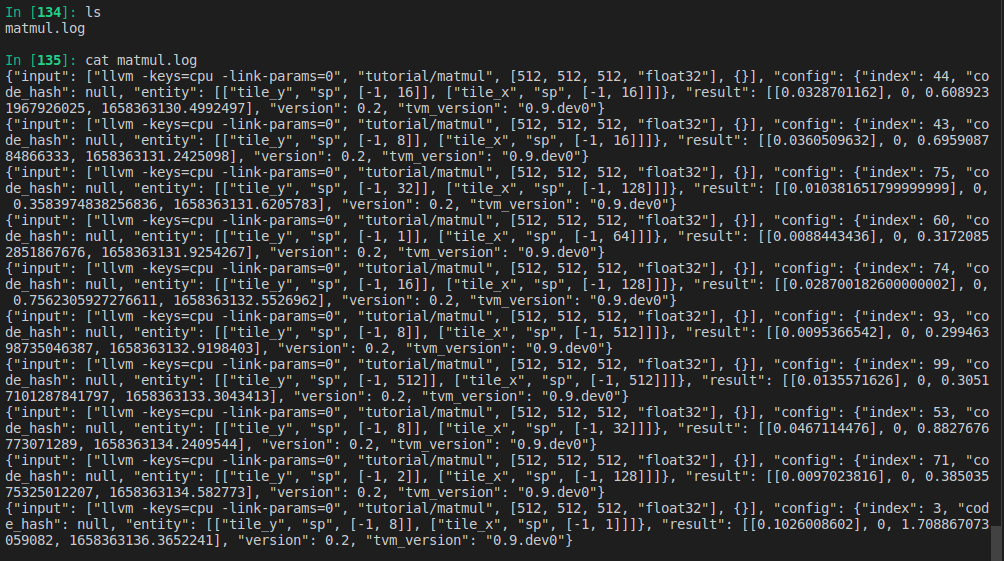
matmul.log内容如下:
TVM:使用调度模板和AutoTVM优化算子的更多相关文章
- TVM自动调度器
TVM自动调度器 随着模型大小,算子多样性和硬件异构性的不断增长,优化深度神经网络的执行速度非常困难.从计算的角度来看,深度神经网络只是张量计算的一层又一层.这些张量计算(例如matmul和conv2 ...
- SystemML大规模机器学习,优化算子融合方案的研究
SystemML大规模机器学习,优化算子融合方案的研究 摘要 许多大规模机器学习(ML)系统允许通过线性代数程序指定定制的ML算法,然后自动生成有效的执行计划.在这种情况下,优化的机会融合基本算子的熔 ...
- Karmada v1.5发布:多调度组助力成本优化
摘要:在最新发布的1.5版本中,Karmada 提供了多调度组的能力,利用该能力,用户可以实现将业务优先调度到成本更低的集群,或者在主集群故障时,优先迁移业务到指定的备份集群. 本文分享自华为云社区& ...
- 微信服务号模板消息接口新增"设置行业"和"添加模板"及细节优化
微信服务号模板消息可以向用户发送重要的服务通知,如信用卡刷卡通知,商品购买成功通知等.昨日,微信团队发布公告称模板消息新增“设置行业”和“添加模板”接口及细节优化,详细变动如下 模板消息[业务通知]自 ...
- 初识费用流 模板(spfa+slf优化) 餐巾计划问题
今天学习了最小费用最大流,是网络流算法之一.可以对于一个每条边有一个容量和一个费用(即每单位流的消耗)的图指定一个源点和汇点,求在从源点到汇点的流量最大的前提下的最小费用. 这里讲一种最基础也是最好掌 ...
- GCD LCM 最大公约数 最小公倍数 分数模板 (防溢出优化完成)
自己写的一个分数模板,在运算操作时进行了防溢出的优化: ll gcd(ll a, ll b) { return b ? gcd(b, a%b) : a; } ll lcm(ll a, ll b) { ...
- k8s pod节点调度及k8s资源优化
一.k8s pod 在节点间调度控制 k8s起pod时,会通过调度器scheduler选择某个节点完成调度,选择在某个节点上完成pod创建.当需要在指定pod运行在某个节点上时,可以通过以下几种方式: ...
- 火山引擎DataLeap数据调度实例的 DAG 优化方案
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,并进入官方交流群 实例 DAG 介绍 DataLeap 是火山引擎自研的一站式大数据中台解决方案,集数据集成.开发.运维.治理.资产管理能力 ...
- sgu 194 被动散热器具有最大流量的上限和下限(最大流量模板dinic加上优化)
模板类型的题详细參考国家集训队论文:http://wenku.baidu.com/view/0f3b691c59eef8c75fbfb35c.html 參考博客:http://blog.csdn.ne ...
- java接口入参模板化,适用于企业化服务远程调度模板化的场景,接口入参实现高度可配置化
需求:远程服务接口模板化配置提供接入服务 模板接口分为三个模块:功能路由.参数校验.模板入库 路由:这里的实现方式很简单,就是根据业务标识找到对应的处理方法 参数校验: 参数校验这步涉及模板和校验类两 ...
随机推荐
- 【博客搭建】Hexo使用笔记
[博客搭建]Hexo 使用笔记 Hexo 是一款前端博客框架,可以自动根据基于 Markdown 的文章生成博客网站代码. 基本概念 项目结构 目录 描述 _config.yml 网站的配置信息 th ...
- ESP AT指令使用记录
一.前言 本篇文章主要用于记录自己在使用AT指令时候的流程,记录一些资料与程序等.如果能帮到你,请给我点个赞. 二.背景知识 ESP-AT是什么? ESP-AT 是乐鑫开发的可直接用于量产的物联网应用 ...
- halo配置踩坑过程小记
写在最前: 终于搞定了最后的一步域名解析配置,其实动态博客的折腾程度也不低于当时的hexo吧,也可能当时的痛苦过程已经忘了..整理一下思路,记录一下配置过程走过的坑. 我是从hexo用了半年想 ...
- node几个类之间的关系
B/S 架构的应用程序,包含两个部分,客户端和服务端,在每一个http请求至响应的完成,产生了这多姿多彩的网页世界,所以,与B/S 架构的一切相关技术问题,都可以认为是一个http请求过程的详细解释: ...
- 解决 Mac(M1/M2)芯片,使用node 14版本
前言 nvm 在安装 Node.js v14.21.3 时,报错: nvm install 14 Downloading and installing node v14.21.3... Downloa ...
- SLAM建图导航信息(仿真)
博客地址:https://www.cnblogs.com/zylyehuo/ 基于[基于机器人自主移动实现SLAM建图],详见之前的博客 基于机器人自主移动实现SLAM建图 - zylyehuo - ...
- http状态码413,并提示Request Entity Too Large的解决办法
使用wordpress的用户经常遇到的问题,就是在后台上传多媒体文件的时候,发现文件大小是有限制的,通常是2M.如图: 如果上传的文件超过2M,服务端返回的状态码会是413,同时提示上传失败.实际上, ...
- delphi获取DOS命令行输出函数 运行CMD命令并获取结果
procedure TForm1.Button4Click(Sender: TObject); var hReadPipe,hWritePipe:THandle; si:STARTUPINFO; ls ...
- C# 多项目打包时如何将项目引用转为包依赖
项目背景 最近开发一组类库,大约会有五六个项目.一个Core,加上若干面向不同产品的实现库,A/B/C/D...它们都依赖Core. 首先,我想统一版本号,这个容易,通过Directory.Build ...
- 看了他,妈妈再也不用担心我被问到Mybatis缓存了
Mybatis缓存 一.一级缓存 1. 概念 sqlsession级别的缓存,即缓存的是SQL语句 同一个sqlsession中执行多次查询条件相同的SQL,mybatis会提供一级缓存进行优化 2. ...