爬虫系列(十) 用requests和xpath爬取豆瓣电影
这篇文章我们将使用 requests 和 xpath 爬取豆瓣电影 Top250,下面先贴上最终的效果图:
1、网页分析
(1)分析 URL 规律
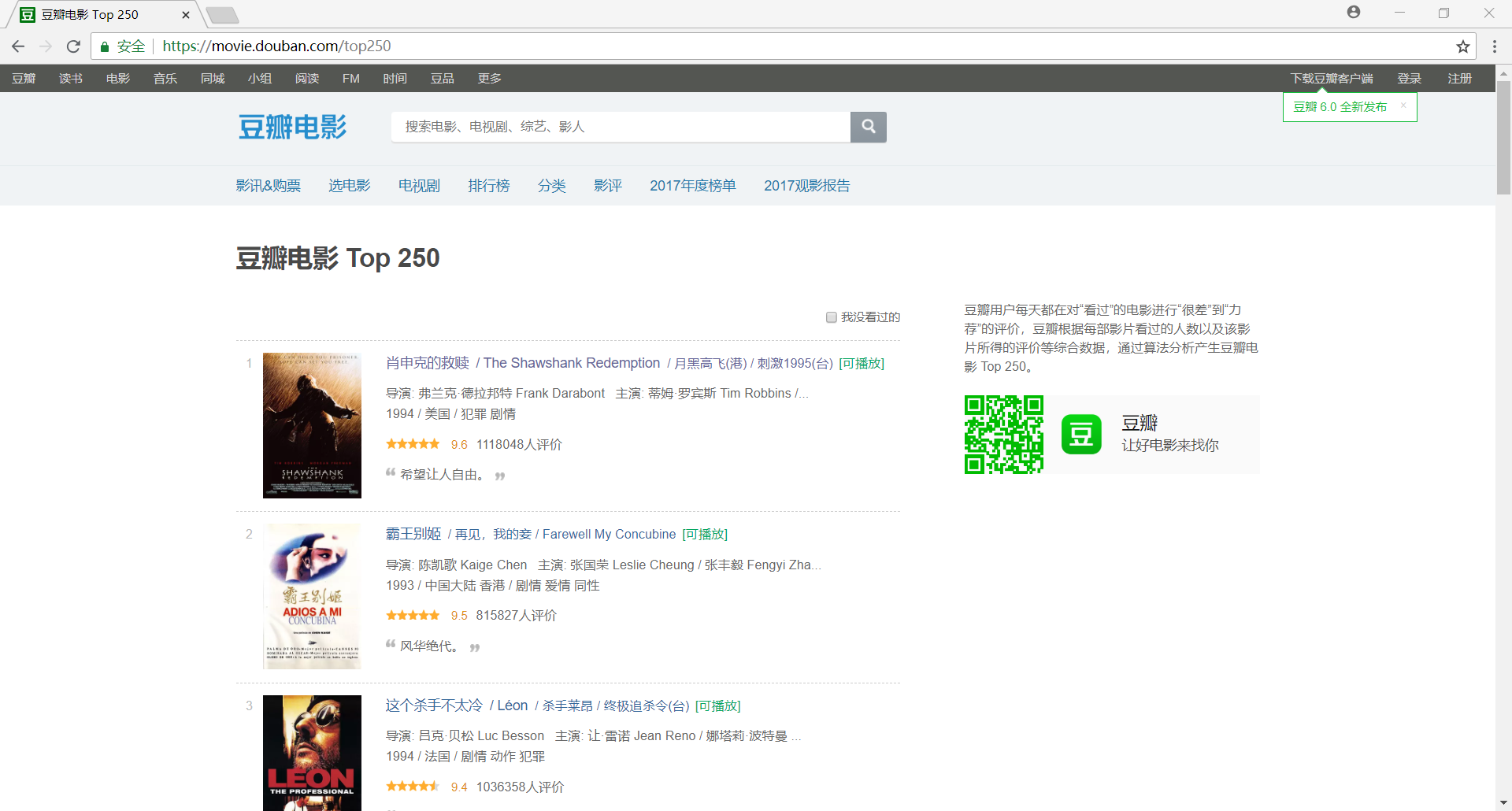
我们首先使用 Chrome 浏览器打开 豆瓣电影 Top250,很容易可以判断出网站是一个静态网页
然后我们分析网站的 URL 规律,以便于通过构造 URL 获取网站中所有网页的内容
首页:https://movie.douban.com/top250
第二页:https://movie.douban.com/top250?start=25&filter=
第三页:https://movie.douban.com/top250?start=50&filter=
...
不难发现,URL 可以泛化为 https://movie.douban.com/top250?start={page}&filter=,其中,page 代表页数
最后我们还需要验证一下首页的 URL 是否也满足规律,经过验证,很容易可以发现首页的 URL 也满足上面的规律
核心代码如下:
import requests
# 获取网页源代码
def get_page(url):
# 构造请求头部
headers = {
'USER-AGENT':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
# 发送请求,获得响应
response = requests.get(url=url,headers=headers)
# 获得网页源代码
html = response.text
# 返回网页源代码
return html
(2)分析内容规律
接下来我们开始分析每一个网页的内容,并从中提取出需要的数据
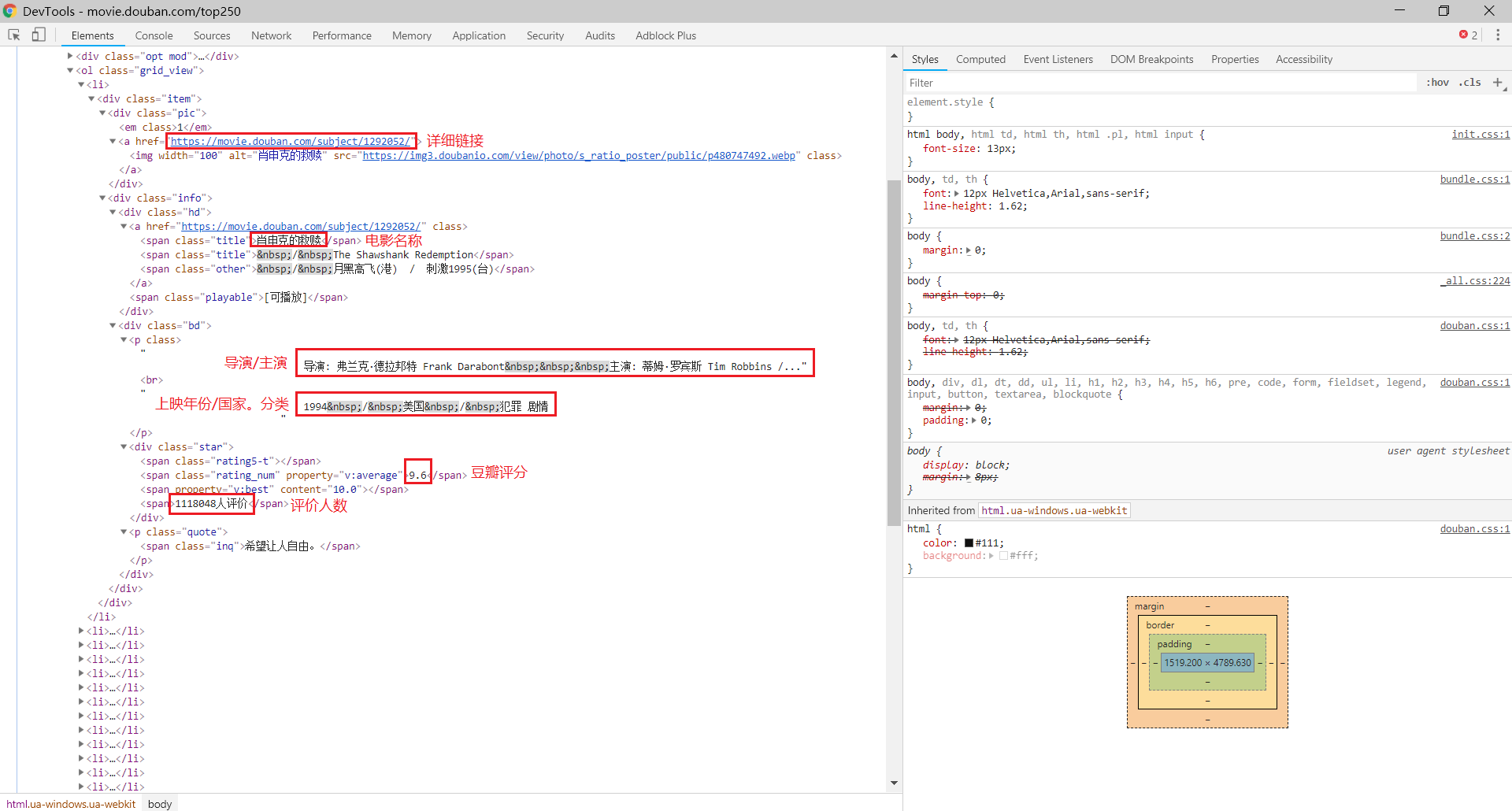
使用快捷键 Ctrl+Shift+I 打开开发者工具,选中 Elements 选项栏分析网页的源代码
需要提取的数据包括(可以使用 xpath 进行匹配):
- 详细链接:
html.xpath('//div[@class="hd"]/a/@href') - 电影名称:
html.xpath('//div[@class="hd"]/a/span[1]/text()') - 导演/主演、上映年份/国家/分类:
html.xpath('//div[@class="bd"]/p[1]//text()') - 豆瓣评分:
html.xpath('//div[@class="bd"]/div/span[2]/text()') - 评价人数:
html.xpath('//div[@class="bd"]/div/span[4]/text()')
核心代码如下:
from lxml import etree
# 解析网页源代码
def parse_page(html):
# 构造 _Element 对象
html_elem = etree.HTML(html)
# 详细链接
links = html_elem.xpath('//div[@class="hd"]/a/@href')
# 电影名称
titles = html_elem.xpath('//div[@class="hd"]/a/span[1]/text()')
# 电影信息(导演/主演、上映年份/国家/分类)
infos = html_elem.xpath('//div[@class="bd"]/p[1]//text()')
roles = [j for i,j in enumerate(infos) if i % 2 == 0]
descritions = [j for i,j in enumerate(infos) if i % 2 != 0]
# 豆瓣评分
stars = html_elem.xpath('//div[@class="bd"]/div/span[2]/text()')
# 评论人数
comments = html_elem.xpath('//div[@class="bd"]/div/span[4]/text()')
# 获得结果
data = zip(links,titles,roles,descritions,stars,comments)
# 返回结果
return data
(3)保存数据
下面将数据分别保存为 txt 文件、json 文件和 csv 文件
import json
import csv
# 打开文件
def openfile(fm):
fd = None
if fm == 'txt':
fd = open('douban.txt','w',encoding='utf-8')
elif fm == 'json':
fd = open('douban.json','w',encoding='utf-8')
elif fm == 'csv':
fd = open('douban.csv','w',encoding='utf-8',newline='')
return fd
# 将数据保存到文件
def save2file(fm,fd,data):
if fm == 'txt':
for item in data:
fd.write('----------------------------------------\n')
fd.write('link:' + str(item[0]) + '\n')
fd.write('title:' + str(item[1]) + '\n')
fd.write('role:' + str(item[2]) + '\n')
fd.write('descrition:' + str(item[3]) + '\n')
fd.write('star:' + str(item[4]) + '\n')
fd.write('comment:' + str(item[5]) + '\n')
if fm == 'json':
temp = ('link','title','role','descrition','star','comment')
for item in data:
json.dump(dict(zip(temp,item)),fd,ensure_ascii=False)
if fm == 'csv':
writer = csv.writer(fd)
for item in data:
writer.writerow(item)
2、编码实现
下面是完整代码,也是几十行可以写完
import requests
from lxml import etree
import json
import csv
import time
import random
# 获取网页源代码
def get_page(url):
headers = {
'USER-AGENT':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
response = requests.get(url=url,headers=headers)
html = response.text
return html
# 解析网页源代码
def parse_page(html):
html_elem = etree.HTML(html)
links = html_elem.xpath('//div[@class="hd"]/a/@href')
titles = html_elem.xpath('//div[@class="hd"]/a/span[1]/text()')
infos = html_elem.xpath('//div[@class="bd"]/p[1]//text()')
roles = [j.strip() for i,j in enumerate(infos) if i % 2 == 0]
descritions = [j.strip() for i,j in enumerate(infos) if i % 2 != 0]
stars = html_elem.xpath('//div[@class="bd"]/div/span[2]/text()')
comments = html_elem.xpath('//div[@class="bd"]/div/span[4]/text()')
data = zip(links,titles,roles,descritions,stars,comments)
return data
# 打开文件
def openfile(fm):
fd = None
if fm == 'txt':
fd = open('douban.txt','w',encoding='utf-8')
elif fm == 'json':
fd = open('douban.json','w',encoding='utf-8')
elif fm == 'csv':
fd = open('douban.csv','w',encoding='utf-8',newline='')
return fd
# 将数据保存到文件
def save2file(fm,fd,data):
if fm == 'txt':
for item in data:
fd.write('----------------------------------------\n')
fd.write('link:' + str(item[0]) + '\n')
fd.write('title:' + str(item[1]) + '\n')
fd.write('role:' + str(item[2]) + '\n')
fd.write('descrition:' + str(item[3]) + '\n')
fd.write('star:' + str(item[4]) + '\n')
fd.write('comment:' + str(item[5]) + '\n')
if fm == 'json':
temp = ('link','title','role','descrition','star','comment')
for item in data:
json.dump(dict(zip(temp,item)),fd,ensure_ascii=False)
if fm == 'csv':
writer = csv.writer(fd)
for item in data:
writer.writerow(item)
# 开始爬取网页
def crawl():
url = 'https://movie.douban.com/top250?start={page}&filter='
fm = input('请输入文件保存格式(txt、json、csv):')
while fm!='txt' and fm!='json' and fm!='csv':
fm = input('输入错误,请重新输入文件保存格式(txt、json、csv):')
fd = openfile(fm)
print('开始爬取')
for page in range(0,250,25):
print('正在爬取第 ' + str(page+1) + ' 页至第 ' + str(page+25) + ' 页......')
html = get_page(url.format(page=str(page)))
data = parse_page(html)
save2file(fm,fd,data)
time.sleep(random.random())
fd.close()
print('结束爬取')
if __name__ == '__main__':
crawl()
【爬虫系列相关文章】
爬虫系列(十) 用requests和xpath爬取豆瓣电影的更多相关文章
- 爬虫系列(十一) 用requests和xpath爬取豆瓣电影评论
这篇文章,我们继续利用 requests 和 xpath 爬取豆瓣电影的短评,下面还是先贴上效果图: 1.网页分析 (1)翻页 我们还是使用 Chrome 浏览器打开豆瓣电影中某一部电影的评论进行分析 ...
- requests+lxml+xpath爬取豆瓣电影
(1)lxml解析html from lxml import etree #创建一个html对象 html=stree.HTML(text) result=etree.tostring(html,en ...
- 爬虫系列1:Requests+Xpath 爬取豆瓣电影TOP
爬虫1:Requests+Xpath 爬取豆瓣电影TOP [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]: ...
- Python爬虫:现学现用xpath爬取豆瓣音乐
爬虫的抓取方式有好几种,正则表达式,Lxml(xpath)与BeautifulSoup,我在网上查了一下资料,了解到三者之间的使用难度与性能 三种爬虫方式的对比. 这样一比较我我选择了Lxml(xpa ...
- requests结合xpath爬取豆瓣最新上映电影
# -*- coding: utf-8 -*- """ 豆瓣最新上映电影爬取 # ul = etree.tostring(ul, encoding="utf-8 ...
- python3+requests+BeautifulSoup+mysql爬取豆瓣电影top250
基础页面:https://movie.douban.com/top250 代码: from time import sleep from requests import get from bs4 im ...
- 爬虫系列(六) 用urllib和re爬取百度贴吧
这篇文章我们将使用 urllib 和 re 模块爬取百度贴吧,并使用三种文件格式存储数据,下面先贴上最终的效果图 1.网页分析 (1)准备工作 首先我们使用 Chrome 浏览器打开 百度贴吧,在输入 ...
- 一起学爬虫——通过爬取豆瓣电影top250学习requests库的使用
学习一门技术最快的方式是做项目,在做项目的过程中对相关的技术查漏补缺. 本文通过爬取豆瓣top250电影学习python requests的使用. 1.准备工作 在pycharm中安装request库 ...
- Python爬虫爬取豆瓣电影之数据提取值xpath和lxml模块
工具:Python 3.6.5.PyCharm开发工具.Windows 10 操作系统.谷歌浏览器 目的:爬取豆瓣电影排行榜中电影的title.链接地址.图片.评价人数.评分等 网址:https:// ...
随机推荐
- ant+jmeter中build.xml配置详解
- ant+jmeter 报告优化
环境基础:ant+jmeter+java +jmeter脚本 1.将 JMeter的extras目录中ant-jmeter-1.1.1.jar包拷贝至ant安装目录下的lib目录中 2.修改JMete ...
- oracle Plsql 运行update或者delete时卡死问题解决的方法
oracle Plsql 运行update或者delete时 遇到过Plsql卡死问题或者导致代码运行sql的时候就卡死. 在开发中遇到此问题的时候,本来把sql复制出来,在plsql中运行,Sql本 ...
- OC常用的数学函数及宏定义
一.函数 1. 三角函数 double sin (double);正弦 double cos (double);余弦 double tan (double);正切 2 .反三角函数 double as ...
- [Apple开发者帐户帮助]六、配置应用服务(4)创建MusicKit标识符和私钥
要与Apple Music服务进行通信,您将使用MusicKit私钥对一个或多个开发人员令牌进行签名. 首先注册音乐标识符以识别您的应用.为使用Apple Music API的每个应用注册音乐标识符. ...
- Python类属性访问的魔法方法
Python类属性访问的魔法方法: 1. __getattr__(self, name)- 定义当用户试图获取一个不存在的属性时的行为 2. __getattribute__(self, name)- ...
- MySql c#通用类
using System; using System.Collections.Generic; using System.Linq; using System.Text;//导命名空间 using S ...
- 折纸---珠穆朗玛问题----简单for 循环
一张纸的厚度大约是0.08mm,对折多少次之后能达到珠穆朗玛峰的高度(8848.13米)? package com.zuoye.test; public class Zhezhi { public s ...
- I2C controller core之Bit controller(02)
4 generate clock and control signals 1 -- architecture signal iscl_oen, isda_oen : std_logic; -- int ...
- 【sqli-labs】 less32 GET- Bypass custom filter adding slashes to dangrous chars (GET型转义了'/"字符的宽字节注入)
转义函数,针对以下字符,这样就无法闭合引号,导致无法注入 ' --> \' " --> \" \ --> \\ 但是,当MySQL的客户端字符集为gbk时,就可能 ...