数据可视化之powerBI技巧(十一)基于SQL思维的PowerBI DAX实战
本文来自于PowerBI星球嘉宾天行老师的分享,天行老师不仅DAX使用娴熟,更是精通SQL,下面就来欣赏他利用SQL思维编写DAX解决问题的一个实战案例。
基于SQL思维使用DAX解决实战问题
作者:天行
学习掌握DAX语言的初期,尤其是刚开始尝试将DAX应用到实战中时,书上的、别人的例子永远是别人的,自己工作中的问题还是找不到如何下手。
其实如果有SQL的使用经验,上手DAX就相对容易很多,尤其对于工作实践中的复杂逻辑,使用SQL思维,进行逐步分解,然后用DAX的方式去具体实现,确实是高效的解决方法。
正好星球学友Mars悬赏征求“一次性解决率“的方案,借此机会,我们一起来实践一下基于SQL思维如何使用DAX来解决这个问题。
问题描述
某客服中心,对每个客服代表的阶段接听客户来电的问题解决情况进行统计分析,设定所接待客户在24小时以内没有再次来电,视为一次性有效解决。现需根据系统导出的每个客户代表接听客户的手机号码及呼入时间,统计每个客户代表的一次性有效解决率。
查看具体数据列表,进一步理解问题细节:
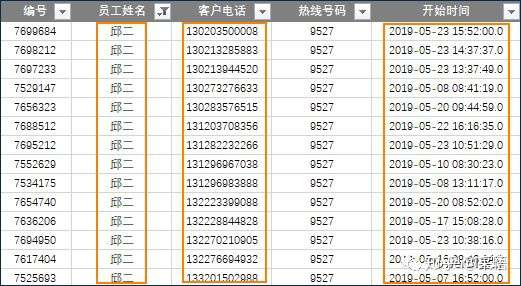
相关字段有【员工姓名】、【客户电话】、【开始时间】
- 一次性有效解决率=一次性有效解决笔数/接听来电总量
解决思路
这个问题看似简单,按员工分类汇总笔数就是接听来电总量,剔除同一来电在24小时之内的重复值就是一次性有效解决笔数,太Easy了!
但真正有实际工作经验的人肯定不会这么轻易得出结论,而是在动手之前会去仔细研究实务中的具体规则,进而提前考虑统计结果出来之后的应用场景,比如:
1、员工的接听总量的规则是什么?重复拨打的用户什么情况下算?什么情况下不算?
2、一次性有效解决的规则是什么?客户拨打会有哪几种可能?哪种可能算有效解决?哪种可能不算有效解决?
3、如果一次性有效解决率是对员工的考核,那么结果出来之后,员工将有查询核对的需求,具体要准备哪些信息才能满足员工查询的需求?
这些问题没有明确的规则,所谓的解决方案怎么可能满足实际业务需求呢?
通过与Mars沟通,明确了规则,也就可以将待解决的问题进行逻辑化描述了:
1、接听总量=全部接听电话数量-同一号码上次本人接听时间间隔不足24小时的接听数量。
要判断同一号码本人上次接听是否间隔不足24小时,就要知道每个客户电话,本人上一次接听的时间,并基于此算出两次接听之间的间隔。
那么用SQL思维如何解决这个问题?
简单说就是选择包含所需数据项的大数据集,然后通过细节条件进行筛选,精准得到符合条件的子数据集。最后对子数据集进行计数、求和、最大/小值和平均值等聚合计算,得到所需分析结果。
那么【全部接听电话数量】就是包含所需数据项的大数据集,在具体案例里面就是某话务员接听的所有电话数量。
【同一号码上次本人接听时间间隔不足24小时的接听电话数量】就是细节条件满足【本人本次接听时间】-【本人上次接听时间】<=86400秒的接听电话数量。
好,问题简化成求【本人上次接听时间】了,按照刚才的SQL思维继续推演:
在这个问题中,包含所需数据项的大数据集=【本人接听此号码的所有记录】中的【接听时间】。
假如【本人接听此号码的所有记录】有多条(实务中就是接听该客户电话在2次以上),那么【本人上次接听时间】就应该是大数据集(【本人接听此号码的所有记录】中【接听时间】)中小于【本人本次接听时间】的最大值。
不再重复以上的推演过程,运用SQL思维抽丝剥茧得到一次性有效解决的数量的描述条件。
2、一次性有效解决量=接听总量-同一号码任意人下次接听时间间隔不足24小时的接听数量
【同一号码任意人下次接听时间间隔不足24小时的接听数量】=【本人本次接听时间】-【任意人下次接听时间】
【任意人下次接听时间】为大于【本人本次接听时间】的所有此电话号码的【接听时间】中的最小值
梳理一下在Power BI中的具体实现操作:
编写【上一次本人接听电话时间】、【距上次时间差额】、【下一次任意人接听电话时间】、【距下次时间差额】等4个计算列
编写【接听客户总量】、【未一次性解决客户数】、【一次性解决率】等3个度量值
代码解析
(一) 计算列
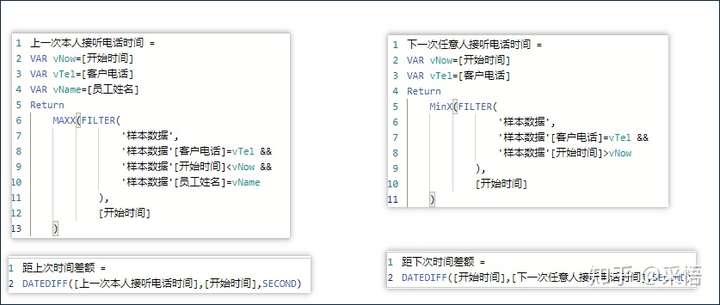
在样本数据表中添加以上4个计算列后的效果如下:
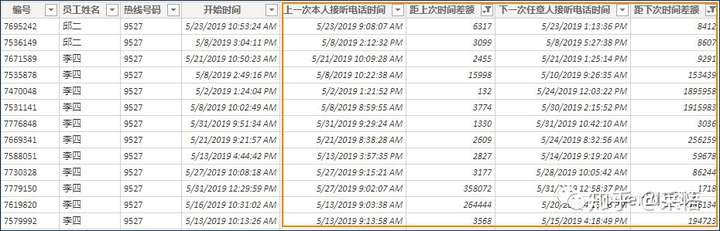
有了这4个辅助列,按照刚才SQL思维的推演,在电子表格中分别设置筛选条件,就可以得到【接听客户总量】和【未一次性解决客户数】的明细数据。
(二) 度量值
在Power BI中,使用计算表可以方便快速地得到每个话务员的统计结果,可以理解为Excel中的数据透视表。
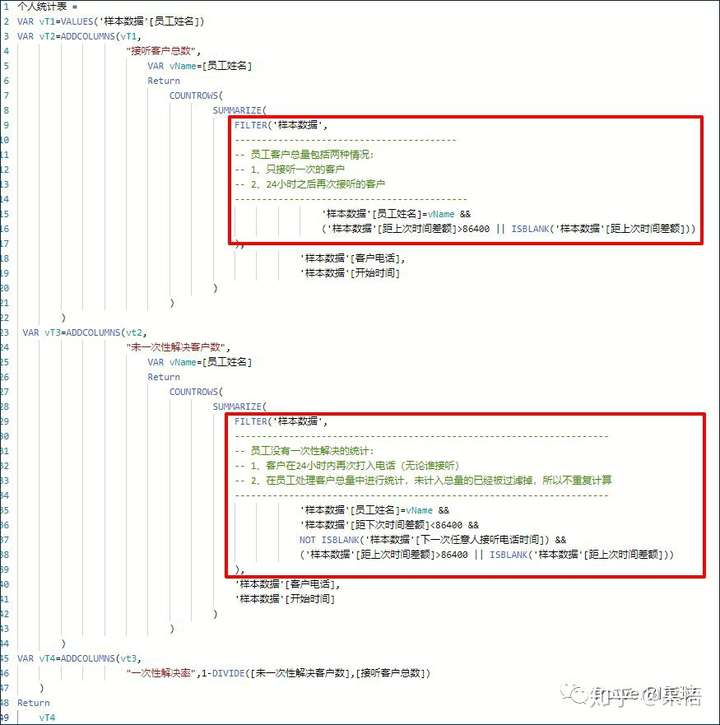
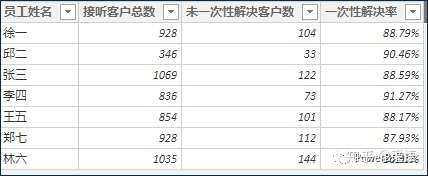
这里用到了构建计算表的方式,本质上每添加一列的代码可原样复制成为一个度量值。
从代码截图的红框部分可以将刚才SQL思维的推演过程与DAX的代码实现结合起来细细咀嚼,提炼模式,化为己用。
要点小结
【一次性解决率】这个具体问题本身的价值似乎并不大,但其实融汇了Power BI投入实战所需要掌握的大多数技能,尝试小结如下:
(一) 思维能力
1、将复杂问题分解成简单问题的技能:即如何将一个大问题拆解成若干小问题组件的能力。在这个案例里面就是将【一次性解决率】拆解成求【接听客户总量】和【未一次性解决客户量】的需求。
2、将业务问题明晰成SQL逻辑的技能:即如何将现实问题归纳为将全部明细数据通过条件筛选后,通过聚合计算得到分析值的分析能力。在这个案例中就是在第二节中的SQL逻辑分析过程。
3、将计算列和度量值灵活结合解决问题的技能:刚接触Power BI,往往对计算列更青睐,Excel的思维习惯使然;熟悉了DAX,恨不得什么东西都要用度量值去实现,追求动态的极致。其实,在具体工作中,往往快速准确得到分析结果才是价值所在。通过计算列和度量值的搭配使用,最高效率地解决现实问题是永远在磨练路上的核心技能。
(二) 技术能力
1、在计算列中掌握行上下文和筛选上下文的组合使用,以及行上下文的转换。具体而言指在掌握计算列中的X函数(迭代器)应用的能力。
2、利用VALUES函数灵活返回表或值的能力。
3、利用ADDCOLUMNS系列函数(包括SELECTCOLUMNS函数)灵活构建计算表的能力。
4、利用FILTER函数灵活返回自定义表的能力。
5、利用SUMMARIZE系列函数(包括SUMMARIZECOLUMNS、GROUPBY函数)进行灵活聚合计算的能力。
掌握了这些技能,使用DAX解决现实中的大多数日常问题应该胸有成竹了,但是如何才能掌握呢?首先从动手练习开始吧,随文附上源数据,供大家参考练习。(后台回复"SQL思维"获取本文数据源文件)
最后出一个小题目,读者可以自我检查一下这篇文章学习的效果。
这个案例中,某话务员对他的一次性解决率评价不服,提出要查看每一笔未能一次性解决的客户电话下一次是哪位话务员接听的,便于了解客户再次来电的真正原因。
数据可视化之powerBI技巧(十一)基于SQL思维的PowerBI DAX实战的更多相关文章
- 数据可视化基础专题(十一):Matplotlib 基础(三)常用图表(一)折线图、散点图、柱状图
1 折线图 折线图主要用于表现随着时间的推移而产生的某种趋势. cat = ["bored", "happy", "bored", &quo ...
- 基于SQL Server 2008 Service Broker构建企业级消息系统
注:这篇文章是为InfoQ 中文站而写,文章的地址是:http://www.infoq.com/cn/articles/enterprisemessage-sqlserver-servicebroke ...
- d3.js:数据可视化利器之快速入门
hello,data! 在进入d3.js之前,我们先用一个小例子回顾一下将数据可视化的基本流程. 任务 用横向柱状图来直观显示以下数据: var data = [10,15,23,78,57,29,3 ...
- 从基于 SQL 的 CURD 操作转移到基于语义 Web 的 CURD 操作
中文名称 CURD 含义 数据库技术中的缩写词 操作对象 一般的项目开发的各种参数 作用 用于处理数据的基本原子操作 它代表创建(Create).更新(Update).读取(Retrieve) ...
- 大数据最后一公里——2021年五大开源数据可视化BI方案对比
个人非常喜欢这种说法,最后一公里不是说目标全部达成,而是把整个路程从头到尾走了一遍. 大数据在经过前几年的野蛮生长以后,开始与数据中台的概念一同向着更实际的方向落地.有人问,数据可视化是不是等同于数据 ...
- 数据可视化之powerBI技巧(二十二)利用这个方法,帮你搞定Power BI"增量刷新"
Power BI的增量刷新功能现在已经对Pro用户开通,但由于种种限制,很多人依然无法使用无这个功能,所以,每一次刷新,都要彻底更新数据集.这对于量级比较大的数据集来说,着实是一件耗费时间的事情. 拿 ...
- 数据可视化之powerBI技巧(六)在PowerBI中简单的操作,实现复杂的预测分析
时间序列预测就是利用过去一段时间内的数据来预测未来一段时间内该数据的走势,比如根据过去5年的销售数据进行来年的收入增长预测,根据上个季度的股票走势推测未来一周的股价变化等等. 对于大部分人来说,这是个 ...
- 数据可视化之powerBI技巧(八)Power BI按多列排序的技巧
目前PowerBI的表格已经支持多列排序,但是矩阵依然还不支持按多个字段排序,虽然这个需求很普遍,这里利用DAX提供一个变通的实现方式. 模拟数据如下,有两个数据指标: 对类别首先按[指标一]进行排序 ...
- 11月16日《奥威Power-BI基于SQL的存储过程及自定义SQL脚本制作报表》腾讯课堂开课啦
上周的课程<奥威Power-BI vs微软Power BI>带同学们全面认识了两个Power-BI的使用情况,同学们已经迫不及待想知道这周的学习内容了吧!这周的课程关键词—— ...
随机推荐
- render props的运用
2020-04-03 render props的运用 术语 “render prop” 是指一种在 React 组件之间使用一个值为函数的 prop 共享代码的简单技术 通常的 这个值为函数的prop ...
- @luogu - P6109@ [Ynoi2009]rprmq
目录 @description@ @solution@ @accepted code@ @details@ @description@ 有一个 n×n 的矩阵 a,初始全是 0,有 m 次修改操作和 ...
- PowerApps Component Framework PCF 部署
PowerApps PCF 可以满足复杂的功能, 我们可以使用PCF来创建复杂的PowerApps. 这里附上微软的package code componet 教程(https://docs.micr ...
- 授权函数-web_set_user
为Web服务器指定登录字符串.当我们使用RNS服务器或者某些服务器的时候需要我们输入账号密码登录才能给进行访问,那么这个时候就需要用到该函数 int web_set_user(const char* ...
- SQL去掉重复数据
SELECT vc_your_email,vc_our_ref_or_code INTO #tmp FROM( SELECT vc_your_email,vc_our_ref_or_code,ROW_ ...
- 关于 JOIN 耐心总结,学不会你打我系列
现在随着各种数据库框架的盛行,在提高效率的同时也让我们忽略了很多底层的连接过程,这篇文章是对 SQL 连接过程梳理,并涉及到了现在常用的 SQL 标准. 其实标准就是在不同的时间,制定的一些写法或规范 ...
- 键盘侠Linux干货| 使用SSH方式推送文件至github仓库
前言 作为一名优秀的计算机从业人员,相信大家github应该都知道吧.(优秀的代码托管工具) 但是由于平常使用的https方式克隆的本地仓库,每次git push时都需要输入帐号密码才能将我们修改的文 ...
- 3、struct2的常见配置
1.在eclipse中如何复制一个工程作为一个新的工程 在struct.xml中: <result name="success">/login_sucess.jsp&l ...
- Java的前生今世
Java作为一门编程语言,自诞生以来已经流行了20多年,在学习它之前,我们有必要先了解一下它的历史,了解它是如何一步步发展到今天这个样子. 孕育 上世纪90年代,硬件领域出现了单片式计算机系统,比如电 ...
- Python3-socketserver模块-网络服务器框架
Python3中的socketserver模块简化了编写网络服务器的任务 在实际的开发中,特别是多并发的情况下,socket模块显然对我们的用处不大,因为如果你要通过socket模块来实现并发的soc ...