分布式ID方案SnowFlake雪花算法分析

1、算法
SnowFlake算法生成的数据组成结构如下:
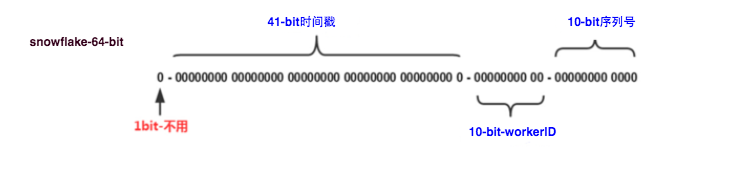
在java中用long类型标识,共64位(每部分用-分开):
0 - 0000000000 0000000000 0000000000 0000000000 0 - 00000 - 00000 - 0000000000 00
- 1位标识,0表示正数。
- 41位时间戳,当前时间的毫秒减去开始时间的毫秒数。可用 (1L << 41) / (1000L * 60 * 60 * 24 * 365) = 69年。
- 5位数据中心标识,可支持(1L << 5) = 32个数据中心。
- 5位机器标识,每个数据中心可支持(1L << 5) = 32个机器标识。
- 12位序列号,每个节点每一毫秒支持(1L << 12) = 4096个序列号。
2、Java版本实现
/**
* 雪花算法<br>
* 在java中用long类型标识,共64位(每部分用-分开):<br>
* 0 - 0000000000 0000000000 0000000000 0000000000 0 - 00000 - 00000 - 0000000000 00<br>
* 1位标识,0表示正数。<br>
* 41位时间戳,当前时间的毫秒减去开始时间的毫秒数。可用 (1L << 41) / (1000L * 60 * 60 * 24 * 365) = 69年。<br>
* 5位数据中心标识,可支持(1L << 5) = 32个数据中心。<br>
* 5位机器标识,每个数据中心可支持(1L << 5) = 32个机器标识。<br>
* 12位序列号,每个节点每一毫秒支持(1L << 12) = 4096个序列号。<br>
*/
public class SnowflakeIdWorker {
/**
* 机器标识
*/
private long workerId;
/**
* 数据中心标识
*/
private long dataCenterId;
/**
* 序列号
*/
private long sequence;
/**
* 机器标识占用5位
*/
private long workerIdBits = 5L;
/**
* 数据中心标识占用5位
*/
private long dataCenterIdBits = 5L;
/**
* 12位序列号
*/
private long sequenceBits = 12L;
/**
* 12位序列号支持的最大正整数
* ....... 00001111 11111111
* 2^12-1 = 4095
*/
private long sequenceMask = ~(-1L << sequenceBits);
/**
* The Worker id shift.
* 12位
*/
private long workerIdShift = sequenceBits;
/**
* The Data center id shift.
* 12 + 5 = 17位
*/
private long dataCenterIdShift = sequenceBits + workerIdBits;
/**
* The Timestamp shift.
* 12 + 5 + 5 = 22位
*/
private long timestampShift = sequenceBits + workerIdBits + dataCenterIdBits;
/**
* 开始时间戳毫秒
*/
private long startEpoch = 29055616000L;
/**
* The Last timestamp.
*/
private long lastTimestamp = -1L;
public SnowflakeIdWorker(long workerId, long dataCenterId, long sequence) {
// 检查workerId是否正常
/*
机器标识最多支持的最大正整数
-1的补码:
11111111 11111111 11111111 11111111 11111111 11111111 11111111 11111111
-1 左移 5 位,高位溢出,低位补0:
11111111 11111111 11111111 11111111 11111111 11111111 11111111 11100000
取反:
00000000 00000000 00000000 00000000 00000000 00000000 00000000 00011111
转10进制:
16 + 8 + 4 + 2 + 1 = 31
*/
long maxWorkerId = ~(-1L << workerIdBits);
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("工作Id不能大于%d或小于0", maxWorkerId));
}
/*
数据中心最多支持的最大正整数31
*/
long maxDataCenterId = ~(-1L << dataCenterIdBits);
if (dataCenterId > maxDataCenterId || dataCenterId < 0) {
throw new IllegalArgumentException(String.format("数据中心Id不能大于%d或小于0", maxDataCenterId));
}
this.workerId = workerId;
this.dataCenterId = dataCenterId;
this.sequence = sequence;
}
private synchronized long nextId() {
//获取当前时间毫秒数
long timestamp = timeGen();
//如果当前时间毫秒数小于上一次的时间戳
if (timestamp < lastTimestamp) {
System.err.printf("时钟发生回调,拒绝生成ID,直到: %d.", lastTimestamp);
throw new RuntimeException(String.format("时钟发生回调, 拒绝为 %d 毫秒生成ID。",
lastTimestamp - timestamp));
}
//当前时间毫秒数与上次时间戳相同,增加序列号
if (lastTimestamp == timestamp) {
//假设sequence=4095
//(4095 + 1) & 4095
//4096: ....... 00010000 00000000
//4095: ....... 00001111 11111111
// ....... 00000000 00000000
//最终sequence为0,即sequence发生溢出。
sequence = (sequence + 1) & sequenceMask;
//如果发生序列号为0,即当前毫秒数的序列号已经溢出,则借用下一毫秒的时间戳
if (sequence == 0) {
timestamp = tilNextMillis(lastTimestamp);
}
} else {
//当前毫秒数大于上次的时间戳,序列号为0
sequence = 0;
}
//更新
lastTimestamp = timestamp;
//生成ID算法,左移几位,则后面加几个0。
//1、当前时间的毫秒数-开始时间的毫秒数,结果左移22位
// 假设:timestamp - startEpoch = 1
// 二进制:
// 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000001
// 左移22位:
// 00000000 00000000 00000000 00000000 00000000 01000000 00000000 00000000
//2、dataCenterId左移17位
// 假设:dataCenterId = 1
// 二进制:
// 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000001
// 左移17位:
// 00000000 00000000 00000000 00000000 00000000 00000010 00000000 00000000
//3、workerId左移12位
// 假设:workerId = 1
// 二进制:
// 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000001
// 左移12位:
// 00000000 00000000 00000000 00000000 00000000 00000000 00010000 00000000
//4、最后的所有结果按位`或`
//假设:sequence = 1
//00000000 00000000 00000000 00000000 00000000 01000000 00000000 00000000
//00000000 00000000 00000000 00000000 00000000 00000010 00000000 00000000
//00000000 00000000 00000000 00000000 00000000 00000000 00010000 00000000
//00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000001
//00000000 00000000 00000000 00000000 00000000 01000010 00010000 00000001
//结果: 0 - 0000000 00000000 00000000 00000000 00000000 01 - 00001 - 00001 - 0000 00000001
return ((timestamp - startEpoch) << timestampShift) |
(dataCenterId << dataCenterIdShift) |
(workerId << workerIdShift) |
sequence;
}
/**
* 获取下一秒
*
* @param lastTimestamp the last timestamp
* @return the long
*/
private long tilNextMillis(long lastTimestamp) {
//获取当前毫秒数
long timestamp = timeGen();
//只要当前的毫秒数小于上次的时间戳,就一直循环,大于上次时间戳
while (timestamp <= lastTimestamp) {
//获取当前毫秒数
timestamp = timeGen();
}
return timestamp;
}
/**
* 获取当前毫秒数
*
* @return the long
*/
private long timeGen() {
return System.currentTimeMillis();
}
public static void main(String[] args) {
SnowflakeIdWorker worker = new SnowflakeIdWorker(1, 1, 1);
for (int i = 0; i < 10000; i++) {
long id = worker.nextId();
System.out.println(id);
System.out.println(Long.toString(id).length());
System.out.println(Long.toBinaryString(id));
System.out.println(Long.toBinaryString(id).length());
}
}
}
3、难点
Tips: 左移几位,则后面加几个0。
3.1、计算机器标识最多支持的最大正整数
private long workerIdBits = 5L;
long maxWorkerId = ~(-1L << workerIdBits);
计算过程:
- -1的补码:
11111111 11111111 11111111 11111111 11111111 11111111 11111111 11111111 - -1 左移 5 位,高位溢出,低位补0:
11111111 11111111 11111111 11111111 11111111 11111111 11111111 11100000 - 取反:
00000000 00000000 00000000 00000000 00000000 00000000 00000000 00011111 - 转10进制:
16 + 8 + 4 + 2 + 1 = 31
3.2、sequence溢出处理
sequence = (sequence + 1) & sequenceMask;
计算过程:
假设sequence=4095:
- (4095 + 1) & 4095
- 4096: ....... 00010000 00000000
- 4095: ....... 00001111 11111111
- 按位与 ....... 00000000 00000000
- 最终sequence为0,即sequence发生溢出。
3.3、ID计算
((timestamp - startEpoch) << timestampShift) |
(dataCenterId << dataCenterIdShift) |
(workerId << workerIdShift) |
sequence
计算过程:
- 当前时间的毫秒数-开始时间的毫秒数,结果左移22位
假设:timestamp - startEpoch = 1
二进制: 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000001
左移22位: 00000000 00000000 00000000 00000000 00000000 01000000 00000000 00000000
- dataCenterId左移17位
假设:dataCenterId = 1
二进制: 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000001
左移17位: 00000000 00000000 00000000 00000000 00000000 00000010 00000000 00000000
- workerId左移12位
假设:workerId = 1
二进制: 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000001
左移12位: 00000000 00000000 00000000 00000000 00000000 00000000 00010000 00000000
- 最后的所有结果按位
或
假设:sequence = 1
00000000 00000000 00000000 00000000 00000000 01000000 00000000 00000000
00000000 00000000 00000000 00000000 00000000 00000010 00000000 00000000
00000000 00000000 00000000 00000000 00000000 00000000 00010000 00000000
00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000001
00000000 00000000 00000000 00000000 00000000 01000010 00010000 00000001
- 结果:
0 - 0000000 00000000 00000000 00000000 00000000 01 - 00001 - 00001 - 0000 00000001
符合SnowFlake算法数据组成结构。
参考
理解分布式id生成算法SnowFlake
Twitter雪花算法SnowFlake算法的java实现

分布式ID方案SnowFlake雪花算法分析的更多相关文章
- 分布式ID生成器 snowflake(雪花)算法
在springboot的启动类中引入 @Bean public IdWorker idWorkker(){ return new IdWorker(1, 1); } 在代码中调用 @Autowired ...
- redis生成分布式id方案
分布式Id - redis方式 本篇分享内容是关于生成分布式Id的其中之一方案,除了redis方案之外还有如:数据库,雪花算法,mogodb(object_id也是数据库)等方案,对于redis来 ...
- 大型互联网公司分布式ID方案总结
ID是数据的唯一标识,传统的做法是利用UUID和数据库的自增ID,在互联网企业中,大部分公司使用的都是Mysql,并且因为需要事务支持,所以通常会使用Innodb存储引擎,UUID太长以及无序,所以并 ...
- 分布式ID方案有哪些以及各自的优劣势,我们当如何选择
作者介绍 段同海,就职于达达基础架构团队,主要参与达达分布式ID生成系统,日志采集系统等中间件研发工作. 背景 在分布式系统中,经常需要对大量的数据.消息.http请求等进行唯一标识,例如:在分布式系 ...
- 分布式id的生成方式——雪花算法
雪花算法是twitter开源的一个算法. 由64位0或1组成,其中41位是时间戳,10位工作机器id,12位序列号,该类通过方法nextID()实现id的生成,用Long数据类型去存储. 我们使用id ...
- 分布式ID方案有哪些以及各自的优势
1. 背景 在分布式系统中,经常需要对大量的数据.消息.http请求等进行唯一标识.例如:在分布式系统之间http请求需要唯一标识,调用链路分析的时候需要使用这个唯一标识.这个时候数据自增主键已 ...
- 分布式id生成器,雪花算法IdWorker
/** * <p>名称:IdWorker.java</p> * <p>描述:分布式自增长ID</p> * <pre> * Twitter的 ...
- 自增ID算法snowflake(雪花)
在数据库主键设计上,比较常见的方法是采用自增ID(1开始,每次加1)和生成GUID.生成GUID的方式虽然简单,但是由于采用的是无意义的字符串,推测会在数据量增大时造成访问过慢,在基础互联网的系统设计 ...
- Dubbo学习系列之七(分布式订单ID方案)
既然选择,就注定风雨兼程! 开始吧! 准备:Idea201902/JDK11/ZK3.5.5/Gradle5.4.1/RabbitMQ3.7.13/Mysql8.0.11/Lombok0.26/Erl ...
随机推荐
- IdentityServer4 (2) 密码授权(Resource Owner Password)
写在前面 1.源码(.Net Core 2.2) git地址:https://github.com/yizhaoxian/CoreIdentityServer4Demo.git 2.相关章节 2.1. ...
- .Net Core HttpClient处理响应压缩
前言 在上篇文章[ASP.NET Core中的响应压缩]中我们谈到了在ASP.NET Core服务端处理关于响应压缩的请求,服务端的主要工作就是根据Content-Encoding头信息判断采 ...
- 铁大树洞app功能演示和使用说明
在观看这篇功能博客之前推荐看一下我们设计软件方案博客,可以更好地理解,博客连接:https://www.cnblogs.com/three3/p/12658897.html首先下载我们软件的安装包,点 ...
- 比PS还好用!Python 20行代码批量抠图
你是否曾经想将某张照片中的人物抠出来,然后拼接到其他图片上去,从而可以即使你在天涯海角,我也可以到此一游? 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在 ...
- 用Python玩连连看是什么效果?
1.前言 Python实现的qq连连看辅助, 仅用于学习, 请在练习模式下使用, 请不要拿去伤害玩家们... 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道 ...
- 使用Python从PDF文件中提取数据
前言 数据是数据科学中任何分析的关键,大多数分析中最常用的数据集类型是存储在逗号分隔值(csv)表中的干净数据.然而,由于可移植文档格式(pdf)文件是最常用的文件格式之一,因此每个数据科学家都应该了 ...
- Java查表法实现十进制转化成其它进制
首先了解十进制转化成二级制的原理 156的二进制为: 156 % 2 = 78 …… 0 83 % 2 = 39 …… 0 39 % 2 = 19 …… 1 19 % 2 = 9 …… 1 9 % 2 ...
- Cross-Stage-Partial-Connections
- 认识与学习BASH①——鸟叔的Linux私房菜
文章目录 认识与学习BASH① 认识BASH 壳程序 多种shells Bash shell 的功能 type :查询指令是否为Bash shell 的内置指令 指令的换行输入和快速删除 Shell的 ...
- idea的热加载与热部署
一:热加载与热部署 热部署的意思就是不用手动重启环境,修改类后,项目会自动重启.但是如果项目比较大,重启也需要耗时十几秒左右. 热加载意为不需要重新启动,修改了什么文件就重新加载什么文 ...