Python实现 K_Means聚类算法
使用 Python实现 K_Means聚类算法:
问题定义
聚类问题是数据挖掘的基本问题,它的本质是将n个数据对象划分为 k个聚类,以便使得所获得的聚类满足以下条件:
同一聚类中的数据对象相似度较高;
不同聚类中的对象相似度较小。
相似度可以根据问题的性质进行数学定义。
K-means算法就是解决这类问题的经典聚类算法
它的基本思想是以空间中k个点为中心,进行聚类,对最靠近他们的对象归类。
通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果
其IPO描述如下:
输入:N个数据
操作:聚类算法
输出:图形化显示聚类结果 K-means算法步骤为:
从 n个数据对象任意选择 k 个对象作为初始聚类中心;并设定最大迭代次数
计算每个对象与k个中心点的距离,并根据最小距离对相应对象进行划分,
即,把对象划分到与他们最近的中心所代表的类别中去;
对于每一个中心点,遍历他们所包含的对象,计算这些对象所有维度的和的均值,获得新的中心点;
如果聚类中心与上次迭代之前相比,有所改变,
或者,算法迭代次数小于给定的最大迭代次数,则继续执行第2、3两步,否则,程序结束返回聚类结果。 K-means算法运行过程
程序代码如下:
程序的控制部分:
首先从文件读入数据,并将其存储在Numpy的数组对象中,
指定聚类个数,与,最大迭代次数,
调用kmeans聚类函数,得到聚类结果
将聚类结果以图的形式展示出来。 子函数定义
Initialize center函数通过使用numpy库的zeros函数和random.uniform函数,
随机选取了k个数据做聚类中心, 并将结果存放在Numpy的Array对象centers中
Dist2Centers这个函数用来计算一个数据点到所有聚类中心的距离,将其存放在dis2cents中返回
kmeans函数.
这部分代码完成了kmeans算法中为数据点决定所属类别以及迭代更新类中心点的主要功能。
注意numpy库的返回最小值索引的argmin函数以及计算平均值的mean函数的使用方法
showcluster函数中,利用matplotlib库的plot函数将不同类别数据以不同颜色展现出来。 完整Python代码如下:
import numpy as np
import matplotlib.pyplot as plt #子函数:Initialize center函数通过使用numpy库的zeros函数和random.uniform函数,
# 随机选取了k个数据做聚类中心, 并将结果存放在Numpy的Array对象centers中
def initCenters(dataSet,k):
numSamples,dim=dataSet.shape
centers=np.zeros((k,dim))
for i in range(k):
index=int(np.random.uniform(0,numSamples)) # random get k centers
centers[i,:]=dataSet[index,:]
print(centers)
return centers #子函数:Dist2Centers这个函数用来计算一个数据点到所有聚类中心的距离,将其存放在dis2cents中返回
def Dist2Centers(sample,centers):
k=centers.shape[0]
dis2cents=np.zeros(k)
for i in range(k):
dis2cents[i]=np.sqrt(np.sum(np.power(sample-centers[i,:],2)))
return dis2cents #子函数:kmeans函数.
# 这部分代码完成了kmeans算法中为数据点决定所属类别以及迭代更新类中心点的主要功能。
# 注意numpy库的返回最小值索引的argmin函数以及计算平均值的mean函数的使用方法
def kmeans(dataSet,k,iterNum):
numSamples=dataSet.shape[0]
iterCount=0 #clusterAssignment stores which cluster this sample belongs to
clusterAssignment=np.zeros(numSamples)
clusterChanged=True ##step 1: initialize centers
centers=initCenters(dataSet,k)
while clusterChanged and iterCount <iterNum:
clusterChanged=False
iterCount=iterCount+1 # for each sample
for i in range(numSamples):
dis2cent=Dist2Centers(dataSet[i,:],centers)
minIndex=np.argmin(dis2cent) #返回最小值索引的argmin函数 ## step 3: update its belonged cluster
if clusterAssignment[i] !=minIndex:
clusterChanged=True
clusterAssignment[i]=minIndex ## step 4: update centers
for j in range(k):
pointsInCluster=dataSet[np.nonzero(clusterAssignment[:]==j)[0]]
centers[j,:]=np.mean(pointsInCluster,axis=0) #计算平均值的mean函数
print("Congratulations ! Cluster Achieved !")
return centers,clusterAssignment #子函数:showcluster函数中,利用matplotlib库的plot函数将不同类别数据以不同颜色展现出来
def showCluster(dataSet,k,centers,clusterAssignment):
numSamples,dim=dataSet.shape
mark=['or','ob','og','om']
#draw all samples
for i in range(numSamples):
markIndex=int(clusterAssignment[i])
plt.plot(dataSet[i,0],dataSet[i,1],mark[markIndex]) mark=['Dr','Db','Dg','Dm']
#draw the centroids 图心,几何中心
for i in range(k):
plt.plot(centers[i,0],centers[i,1],mark[i],markersize=17)
plt.title("K=%d"%k)
plt.show() def main():
## step 1: load dataset
print("step 1: loading dataset...")
dataSet=[]
dataSetFile=open("180320-testSet.txt")
for line in dataSetFile:
lineArr=line.strip().split('\t')
dataSet.append([float(lineArr[0]),float(lineArr[1])]) ## step 2: clustering...
print("step 2: clustering...")
dataSet=np.mat(dataSet) k=2
centers_result,clusterAssignment_result=kmeans(dataSet,k, 100) ##step 3: show the result
print("tep 3: show the result...")
showCluster(dataSet,k,centers_result,clusterAssignment_result)
main()
实验结果:
运行程序,
下面依次是,将数据,聚为两类,三类,四类的程序结果图。也可以通过调整迭代次数,观察生成簇的变化
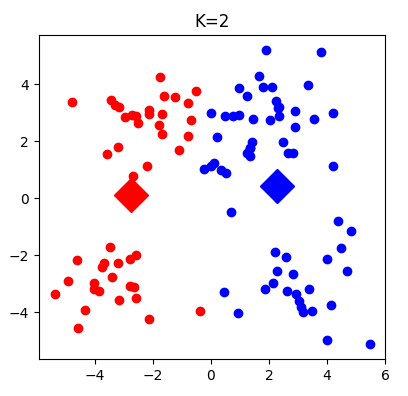
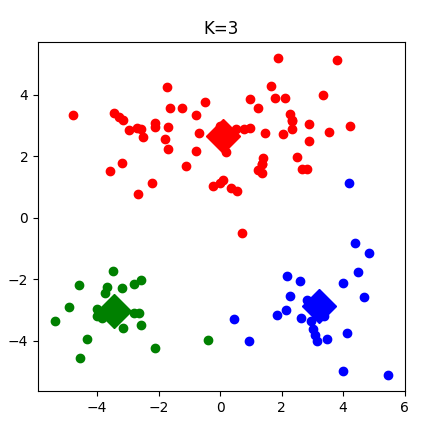
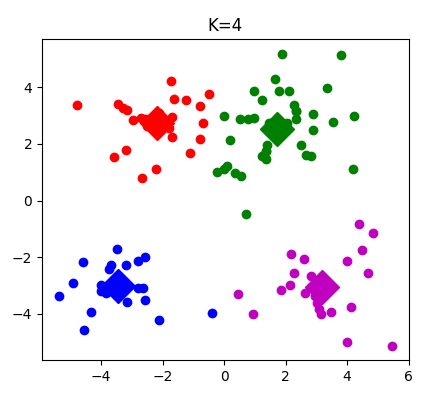
【完整源码】:点我获取
【测试文件】:点我获取
Python实现 K_Means聚类算法的更多相关文章
- python机器学习(1:K_means聚类算法)
一.算法介绍 K-means算法是最简单的也是最著名的划分聚类算法,由于简洁和效率使得他成为所有聚类算法中最广泛使用的.算法的目的是使各个样本与所在均值的误差平方和达到最小(这也是评价K-means算 ...
- Python 实现分层聚类算法
''' 1.将所有样本都看作各自一类 2.定义类间距离计算公式 3.选择距离最小的一堆元素合并成一个新的类 4.重新计算各类之间的距离并重复上面的步骤 5.直到所有的原始元素划分成指定数量的类 程序要 ...
- python实现K聚类算法
参考:<机器学习实战>- Machine Learning in Action 一. 基本思想 聚类是一种无监督的学习,它将相似的对象归到同一簇中.它有点像全自动分类.聚类方法几乎可以应 ...
- 使用sklearn进行K_Means聚类算法
首先附上官网说明 [http://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html#examples-usin ...
- Python实现DBSCAN聚类算法(简单样例测试)
发现高密度的核心样品并从中膨胀团簇. Python代码如下: # -*- coding: utf-8 -*- """ Demo of DBSCAN clustering ...
- python聚类算法解决方案(rest接口/mpp数据库/json数据/下载图片及数据)
1. 场景描述 一直做java,因项目原因,需要封装一些经典的算法到平台上去,就一边学习python,一边网上寻找经典算法代码,今天介绍下经典的K-means聚类算法,算法原理就不介绍了,只从代码层面 ...
- 机器学习:Python实现聚类算法(三)之总结
考虑到学习知识的顺序及效率问题,所以后续的几种聚类方法不再详细讲解原理,也不再写python实现的源代码,只介绍下算法的基本思路,使大家对每种算法有个直观的印象,从而可以更好的理解函数中参数的意义及作 ...
- 【转】利用python的KMeans和PCA包实现聚类算法
转自:https://www.cnblogs.com/yjd_hycf_space/p/7094005.html 题目: 通过给出的驾驶员行为数据(trip.csv),对驾驶员不同时段的驾驶类型进行聚 ...
- K-means聚类算法及python代码实现
K-means聚类算法(事先数据并没有类别之分!所有的数据都是一样的) 1.概述 K-means算法是集简单和经典于一身的基于距离的聚类算法 采用距离作为相似性的评价指标,即认为两个对象的距离越近,其 ...
随机推荐
- StatefulSet: Kubernetes 中对有状态应用的运行和伸缩
在最新发布的 Kubernetes 1.5 我们将过去的 PetSet 功能升级到了 Beta 版本,并重新命名为StatefulSet.除了依照社区民意改了名字之外,这一 API 对象并没有太大变化 ...
- 15、高可用 PXC(percona xtradb cluster) 搭建
安装环境: 集群名 pxc_lk 节点1: 192.168.1.20 节点2: 192.168.1.21 节点3: 192.168.1.22 所有节点安装 wget http://www.perc ...
- Java读取properties配置文件经常用法
在开发中对properties文件的操作还是蛮常常的.所以总结了几种操作方法,为后面的开发能够进行參考. 1.通过java.util.ResourceBundle类来读取 这边測试用到了枚举类进行传入 ...
- VUE router-view 页面布局 (嵌套路由+命名视图)
嵌套路由 实际生活中的应用界面,通常由多层嵌套的组件组合而成.同样地,URL 中各段动态路径也按某种结构对应嵌套的各层组件,例如: /user/foo/profile /user/foo/posts ...
- QtWebKit
WekKit官网:http://www.webkit.org/ QtWebKit官网及安装:http://trac.webkit.org/wiki/QtWebKit#GettingInvolved Q ...
- 4 Sum leetcode java
题目: Given an array S of n integers, are there elements a, b, c, and d in S such that a + b + c + d = ...
- Simplify Path leetcode java
题目: Given an absolute path for a file (Unix-style), simplify it. For example, path = "/home/&qu ...
- 正则 js截取时间
项目中要把时间截取,只要年月日,不要时分秒,于是 /\d{4}-\d{1,2}-\d{1,2}/g.exec("2012-6-18 00:00:00") 或者另一种 var dat ...
- easyui combobox实现本地模糊查询
直接上代码 $("#combobox1").combobox({ valueField : "value", textField : "text&qu ...
- 2019年所有人必须要掌握的一个技能 - “AI思维”
或许很多人认为AI只是那些直接从事AI相关岗位的人必须要掌握的技能,但实际上,不分岗位所有人都需要一种能力,那就是“AI思维”.如果没能在合适的时机把自己的认知提升到一定程度,被替代是很自然的事情.在 ...