hadoop2.8 集群 1 (伪分布式搭建)
简介:
关于完整分布式请参考: hadoop2.8 ha 集群搭建 【七台机器的集群】
Hadoop:(hadoop2.8)
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了 (relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。 -----来自google

hadoop安装模式:
hadoop安装模式有三种,本节重点介绍伪分布式的安装配置和启动。
第一种是本地(独立)模式: 本地模式没啥意义,大家可以作为一个入门的参考。
第二种是伪分布式集群: 在物理机不允许的情况下,用单机模拟集群的效果
第三种是完全分布式集群: 搭建完成分布式集群,为业务进行服务,具有高容错,高性能,高冗余等特点。后面我会再详细介绍
hadoop伪分布式搭建:
第一步:准备工作
centos下载: 下载适合自己的版本
本机已经安装好VMware和xshell。我已经在虚拟机上创建一个centos作为此次安装的环境。我采用的是centos7.



注意: 我在这选择的centos7的mini版本。可以选择完整版本centos.不过完整版本太大。我就用mini版本演示,mini版本里面很多软件都需要自己安装,所以我也会把我安装的步骤贴出来给大家做个分享。
第二步:启动虚拟机hadoop_yang
启动虚拟机后我要做一些调整.
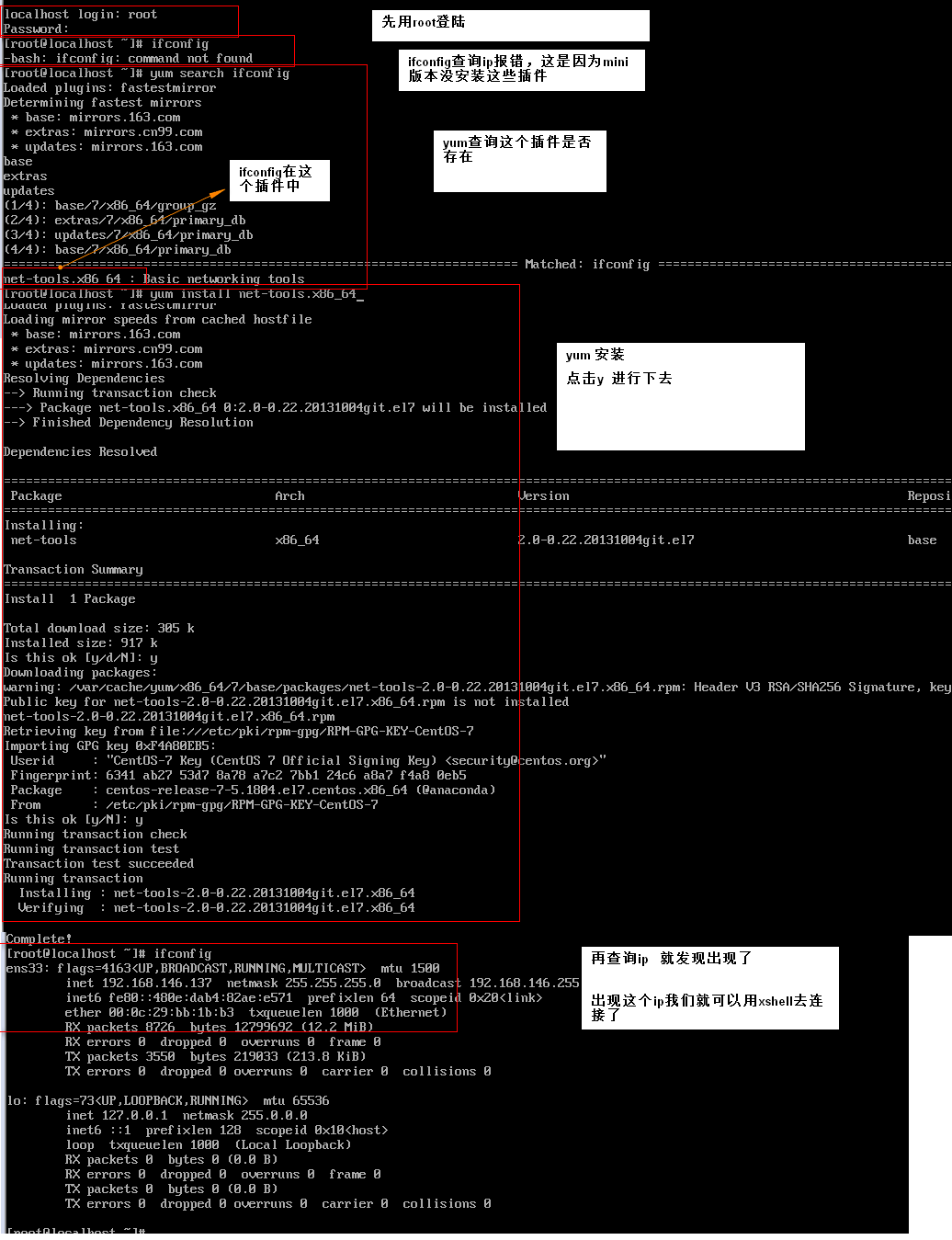
1> 查看ip 使用ifconfig命令,但是会报错,因为我这是mini版本,没安装这些。没关系,我来安装一下:(完整版本就已经安装好了,就不需要下面这步了)
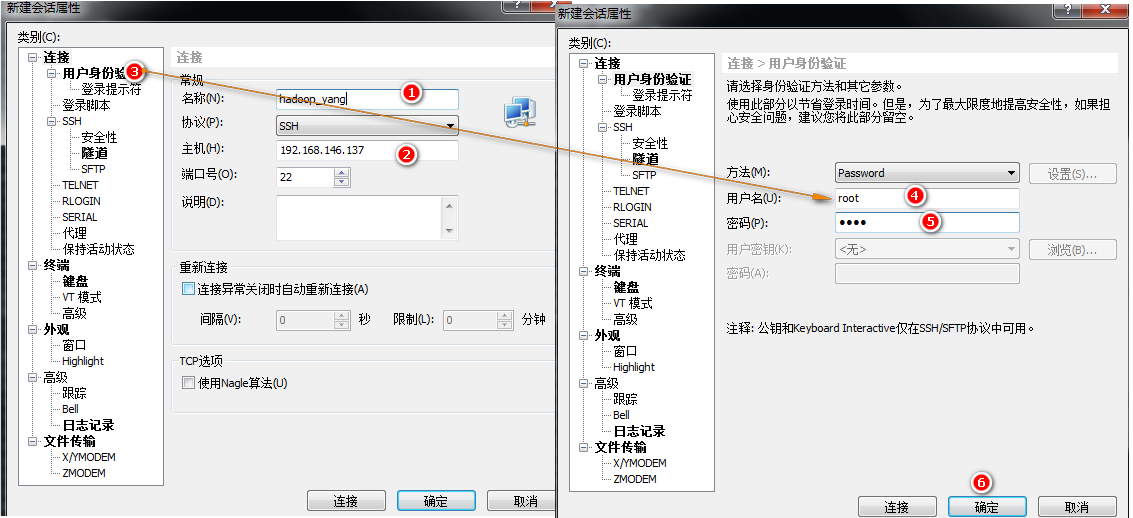
2> xshell连接到这个hadoop_yang上;
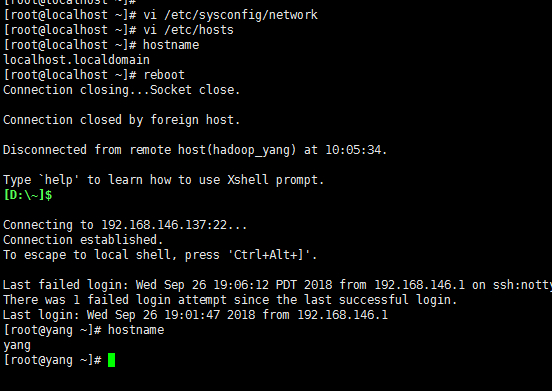
3> 修改主机名和关闭防火墙。[ 保存退出 :wq! 或者 shift + zz ]
修改主机名:vi /etc/sysconfig/network
将HOSTNAME=localhost改为HOSTNAME=yang 保存退出
修改主机名与IP映射文件:vi /etc/hosts
添加192.168.146.137 yang 保存退出
修改完成后重启生效:
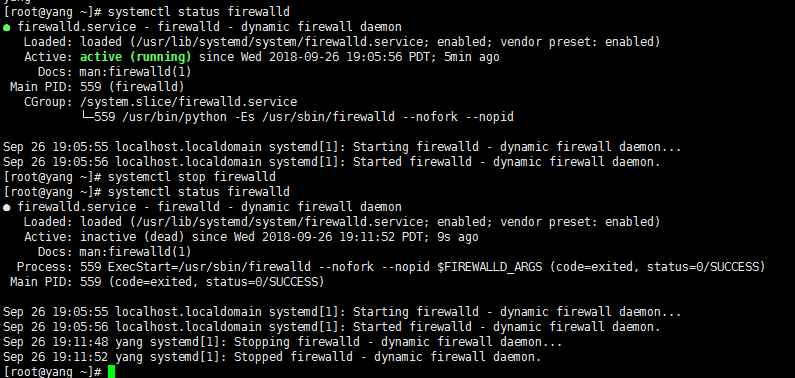
关闭防火墙,为了可以在搭建完成后我们可以访问其端口。如果不想关闭防火墙,可以打开我们要访问的端口即可。随自己喜好吧。我在这就直接关闭防火墙进行演示。
1》systemctl stop firewalld 关闭防火墙
2》systemctl status firewalld 查看防火墙状态
3》 systemctl start firewalld 开启防火墙
4》 systemctl disable firewalld 禁止防火墙随机启动
上面是关闭防火墙,还可以在开启某一个访问端口:vi/etc/sysconfig/iptables 这个前提要安装iptables.就不演示了。
4> SSH设置和密钥生成
SSH设置需要在集群上做不同的操作,如启动,停止,分布式守护shell操作。认证不同的Hadoop用户,需要一种用于Hadoop用户提供的公钥/私钥对,并用不同的用户共享。
下面的命令用于生成使用SSH键值对。复制公钥形成 id_rsa.pub 到authorized_keys 文件中,并提供拥有者具有authorized_keys文件的读写权限。
$ ssh-keygen -t rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keys 【可以不加】
第三步:上传需要软件[安装lrzsz]
jdk1.8 ,hadoop2.8 【我已经下载好这些了】
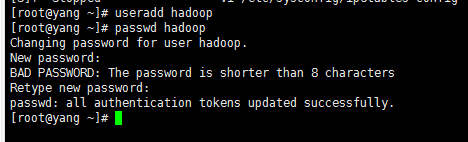
1》到这准备工作已经基本完成,我要在root超级用户下创建一个我们搭建集群的用户。hadoop
2》配置hadoop用户的sudo命令。参考我的博客:sudo的安装
3》切换到hadoop用户上。我们来安装hadoop的伪分布式。
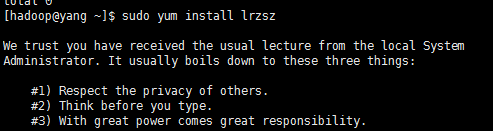
4》上传软件
先安装lrzsz插件
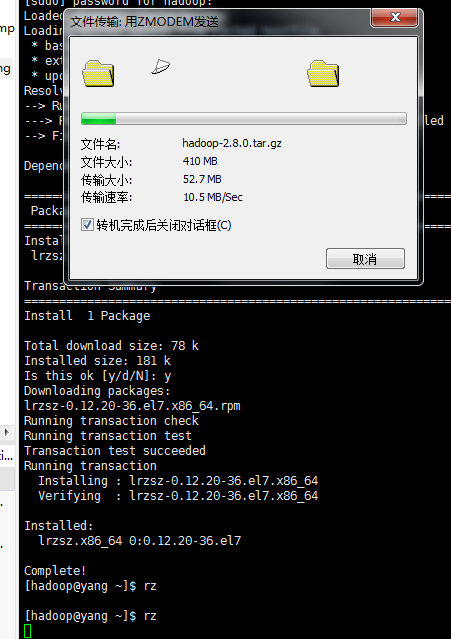

到这,我们已经通过命令把jdk和hadoop上传到了/home/hadoop的家目录下了。

第四步:安装jdk和hadoop:
1>解压jdk,并移动到 /usr/local 下 修改名称为jdk1.8
解压

重命名

移动到指定文件夹

查看移动效果:
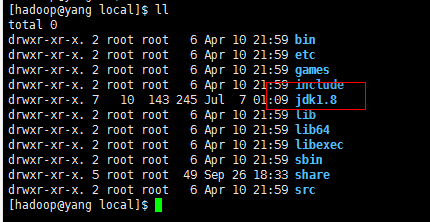
配置java环境变量: vi ~/.bashrc [用户的] 或者 /etc/profile [系统的] 在这我就配置用户级别的。系统的全局有效。不明白这个范围的可以上网查一下。我就不详细介绍了。
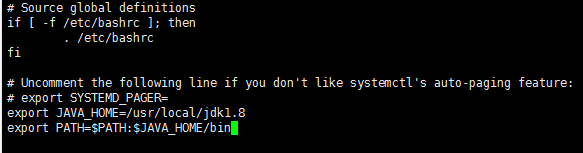
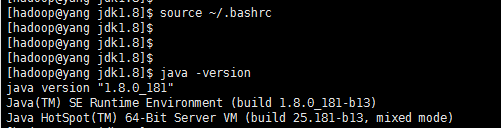
source ~/.bashrc 让配置生效。
然后java -version 验证java配置是否成功。
2> hadoop的配置:(修改hadoop/etc/hadoop下的配置文件(hadoop-env.sh、core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml))
jdk是hadoop的基础。安装好jdk后,我们来配置hadoop。首先解压hadoop。我在local下创建一个hadoop文件夹,后期hadoop的其他插件我也会放在这个文件夹中。
执行命令 sudo tar -zxvf hadoop----tgz -C /usr/local/hadoop -C参数,是直接解压到指定文件夹。
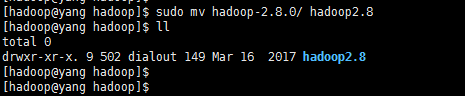
配置环境变量:

还可以加上这些属性:
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
source ~/.bashrc 让配置生效。
1》修改hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1.8
2》

第五步:格式化启动
1>格式化hdfs(只能格式化一次)
cd $HADOOP_HOME/bin
hdfs namenode -format
2>启动hadoop
cd $HADOOP_HOME/sbin
启动hdfs
start-dfs.sh
启动yarn
start-yarn.sh
启动historyserver
mr-jobhistory-daemon.sh start historyserver
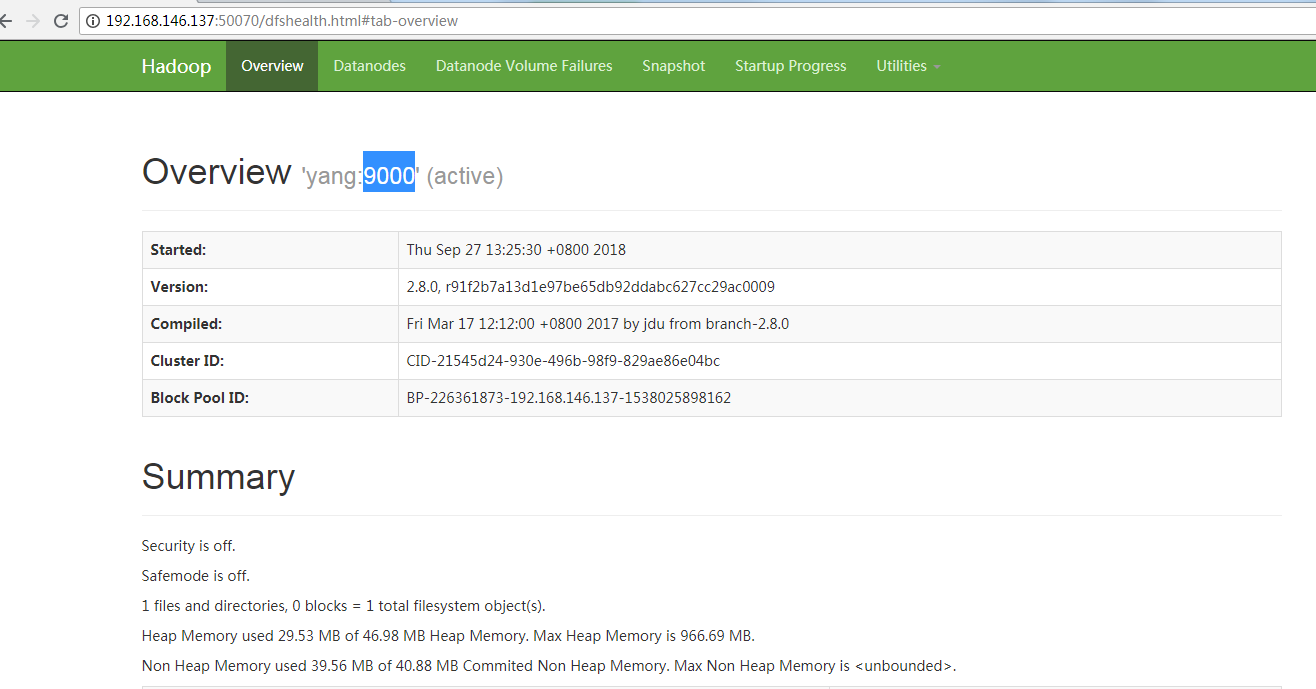
web验证:(打开表示启动成功)
验证hdfs启动状态:http://yang:50070/
验证yarn启动状态:http://yang:8088/
验证启动状态:http://yang:19888/

hadoop2.8 集群 1 (伪分布式搭建)的更多相关文章
- Ubuntu下用hadoop2.4搭建集群(伪分布式)
要真正的学习hadoop,就必需要使用集群,可是对于普通开发人员来说,没有大规模的集群用来測试,所以仅仅能使用伪分布式了.以下介绍怎样搭建一个伪分布式集群. 为了节省时间和篇幅,前面一些步骤不再叙述. ...
- [b0006] Spark 2.0.1 伪分布式搭建练手
环境: 已经安装好: hadoop 2.6.4 yarn 参考: [b0001] 伪分布式 hadoop 2.6.4 准备: spark-2.0.1-bin-hadoop2.6.tgz 下载地址: ...
- Hadoop2.x 集群搭建
Hadoop2.x 集群搭建 一些重复的细节参考Hadoop1.X集群完全分布式模式环境部署 1 HADOOP 集群搭建 1.1 集群简介 HADOOP 集群具体来说包含两个集群:HDFS 集群和YA ...
- redis在Windows下以后台服务一键搭建集群(单机--伪集群)
redis在Windows下以后台服务一键搭建集群(单机--伪集群) 一.概述 此教程介绍如何在windows系统中同一台机器上布置redis伪集群,同时要以后台服务的模式运行.布置以脚本的形式,一键 ...
- 沉淀,再出发——在Hadoop集群的基础上搭建Spark
在Hadoop集群的基础上搭建Spark 一.环境准备 在搭建Spark环境之前必须搭建Hadoop平台,尽管以前的一些博客上说在单机的环境下使用本地FS不用搭建Hadoop集群,可是在新版spark ...
- 2.hadoop基本配置,本地模式,伪分布式搭建
2. Hadoop三种集群方式 1. 三种集群方式 本地模式 hdfs dfs -ls / 不需要启动任何进程 伪分布式 所有进程跑在一个机器上 完全分布式 每个机器运行不同的进程 2. 服务器基本配 ...
- Redis单机版以及集群版的安装搭建以及使用
1,redis单机版 1.1 安装redis n 版本说明 本教程使用redis3.0版本.3.0版本主要增加了redis集群功能. 安装的前提条件: 需要安装gcc:yum install g ...
- Nginx集群之WCF分布式局域网应用
目录 1 大概思路... 1 2 Nginx集群WCF分布式局域网结构图... 1 3 关于WCF的BasicHttpBinding. 1 4 编写WC ...
- Nginx集群之WCF分布式身份验证(支持Soap)
目录 1 大概思路... 1 2 Nginx集群之WCF分布式身份验证... 1 3 BasicHttpBinding.ws2007HttpBinding. 2 4 ...
随机推荐
- 堆排序Heapsort的Java和C代码
Heapsort排序思路 将整个数组看作一个二叉树heap, 下标0为堆顶层, 下标1, 2为次顶层, 然后每层就是"3,4,5,6", "7, 8, 9, 10, 11 ...
- ElementUi tree 指定节点是否显示复选框
场景:树的内容是省份下面的城市有酒店 需求:只能多选酒店(为了删除它们),至于为啥不能选省份或者城市更加灵活的去删除相应酒店,这你得去问后台0.0,他只弄了根据酒店id去删除.嗯,连创建酒店的时候级联 ...
- Java与.net 关于URL Encode 的区别
在c#中,HttpUtility.UrlEncode("www+mzwu+com")编码结果为www%2bmzwu%2bcom,在和Java开发的平台做对接的时候,对方用用url编 ...
- 帆软 联合 创始人 数据可视化 中国 发展 FineReport FineBI
丧心病狂!帆软公司的成立竟源于一个被初恋抛弃的程序员 - 大数据-炼数成金-Dataguru专业数据分析社区http://dataguru.cn/article-7500-1.html 帆软联合创始人 ...
- EasyNVR网页无插件播放摄像机RTSP流是如何调取接口在Web页实现多窗口同时直播的
背景需求 在互联网飞速发展的时代,开发者常会说的一个词就是"跨平台".自从移动端的用户需求越来越大,H5逐渐发展,跨平台似乎已经成为了软件开发不可或缺的技术.EasyNVR互联网直 ...
- [LeetCode] 87. Scramble String 爬行字符串
Given a string s1, we may represent it as a binary tree by partitioning it to two non-empty substrin ...
- Shell中要如何调用别的shell脚本,或别的脚本中的变量,函数
在Shell中要如何调用别的shell脚本,或别的脚本中的变量,函数呢? 方法一: . ./subscript.sh 方法二: source ./subscript.sh 注意: 1.两个点之 ...
- 【Sqoop学习之一】Sqoop简介
环境 sqoop-1.4.6 Sqoop:将关系数据库(oracle.mysql.postgresql等)数据与hadoop数据进行转换的工具. 两个版本:两个版本完全不兼容,sqoop1使用最多:s ...
- 查看LINUX进程内存占用情况及启动时间
可以直接使用top命令后,查看%MEM的内容.可以选择按进程查看或者按用户查看,如想查看oracle用户的进程内存使用情况的话可以使用如下的命令: (1) top top命令是Linux下常用的性能分 ...
- 05 javascript知识点---BOM和DOM
1.DOM简单学习(为了满足案例要求) 功能:控制html文档的内容获取页面标签(元素)对象:Element document.getElementById("id值"):通过元素 ...