Hadoop(四)—— MapReduce
一、Hadoop版本特性
MRv1
第一代计算框架,由编程模型和运行时环境两部分组成。
编程模型是,将数据进行map操作,然后进行reduce操作,最后将计算结果存储到HDFS中。
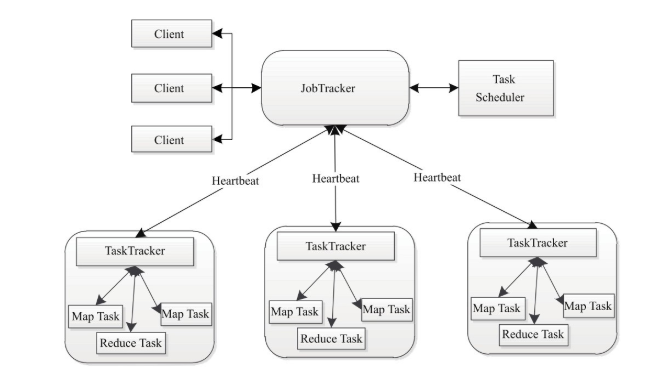
运行时环境是,由JobTracker和TaskTracker组成,JobTracker进行资源管理和作业控制。TaskTracker负责接收JobTracker分配的任务并执行。
YARN/MRv2
针对MRv1的问题,提出YARN资源管理框架,将JobTracker中的资源管理和作业控制分开,资源管理由ResourceManager进程实现,作业控制由ApplicationMaster进程实现。
二、模型概述
The MapReduce framework operates exclusively on <key, value> pairs, that is, the framework views the input to the job as a set of <key, value> pairs and produces a set of <key, value> pairs as the output of the job, conceivably of different types.
The key and value classes have to be serializable by the framework and hence need to implement the Writable interface. Additionally, the key classes have to implement the WritableComparable interface to facilitate sorting by the framework.
Input and Output types of a MapReduce job:
(input) <k1, v1> -> map -> <k2, v2> -> combine -> <k2, v2> -> reduce -> <k3, v3> (output)
map()
对多个key/value进行处理产生对应的新的key/value。
reduce()
对key/value进行处理,生成最终结果。
MapReduce架构
实现一个MapReduce程序
对数据进行处理。找出所有年份中的最高气温。
引入Jar包
<!-- hadoop mapreduce编程所需jars -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.2.0</version>
</dependency>
<dependency>
<groupId>commons-cli</groupId>
<artifactId>commons-cli</artifactId>
<version>1.2</version>
</dependency>
MapReduce模型
Hadoop MapReduce is a software framework for easily writing applications which process vast amounts of data (multi-terabyte data-sets) in-parallel on large clusters (thousands of nodes) of commodity hardware in a reliable(可靠的), fault-tolerant manner(方式).
MR是一个软件框架,可以简化编写应用,用于在分布式环境下,用一种可用、容错的方式处理大规模数据。
A MapReduce job usually splits the input data-set into independent chunks(块、片) which are processed by the map tasks in a completely parallel manner. The framework sorts the outputs of the maps, which are then input to the reduce tasks. Typically both the input and the output of the job are stored in a file-system. The framework takes care of scheduling tasks, monitoring them and re-executes the failed tasks.
一个MR任务,通常将输入的数据集用map任务以完全并行的方式处理成独立的块。
参考文档
Hadoop技术内幕:深入解析MapReduce架构设计与实现原理
Hadoop(四)—— MapReduce的更多相关文章
- hadoop系列四:mapreduce的使用(二)
转载请在页首明显处注明作者与出处 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的一些内容,如hadoop,spark,storm,机器学习等. 当前使用的hadoop版本为2.6 ...
- Hadoop基础-MapReduce入门篇之编写简单的Wordcount测试代码
Hadoop基础-MapReduce入门篇之编写简单的Wordcount测试代码 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本文主要是记录一写我在学习MapReduce时的一些 ...
- Hadoop基础-MapReduce的排序
Hadoop基础-MapReduce的排序 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.MapReduce的排序分类 1>.部分排序 部分排序是对单个分区进行排序,举个 ...
- Hadoop基础-MapReduce的数据倾斜解决方案
Hadoop基础-MapReduce的数据倾斜解决方案 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.数据倾斜简介 1>.什么是数据倾斜 答:大量数据涌入到某一节点,导致 ...
- Hadoop基础-MapReduce的Partitioner用法案例
Hadoop基础-MapReduce的Partitioner用法案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Partitioner关键代码剖析 1>.返回的分区号 ...
- Hadoop基础-MapReduce的Combiner用法案例
Hadoop基础-MapReduce的Combiner用法案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.编写年度最高气温统计 如上图说所示:有一个temp的文件,里面存放 ...
- Hadoop基础-MapReduce的工作原理第二弹
Hadoop基础-MapReduce的工作原理第二弹 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Split(切片) 1>.MapReduce处理的单位(切片) 想必 ...
- Hadoop基础-MapReduce的工作原理第一弹
Hadoop基础-MapReduce的工作原理第一弹 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 在本篇博客中,我们将深入学习Hadoop中的MapReduce工作机制,这些知识 ...
- hadoop的mapReduce和Spark的shuffle过程的详解与对比及优化
https://blog.csdn.net/u010697988/article/details/70173104 大数据的分布式计算框架目前使用的最多的就是hadoop的mapReduce和Spar ...
- hadoop之mapreduce详解(进阶篇)
上篇文章hadoop之mapreduce详解(基础篇)我们了解了mapreduce的执行过程和shuffle过程,本篇文章主要从mapreduce的组件和输入输出方面进行阐述. 一.mapreduce ...
随机推荐
- 连续子数组的最大乘积及连续子数组的最大和(Java)
1. 子数组的最大和 输入一个整形数组,数组里有正数也有负数.数组中连续的一个或多个整数组成一个子数组,每个子数组都有一个和.求所有子数组的和的最大值.例如数组:arr[]={1, 2, 3, -2, ...
- Jboss部署SpringBoot2 JPA
Jboss部署SpringBoot2 JPA 目录结构 . └── webapp └── META-INF ├── jboss-deployment-structure.xml └── jboss-w ...
- this指向详解及改变它的指向的方法
一.this指向详解(彻底理解js中this的指向,不必硬背) 首先必须要说的是,this的指向在函数定义的时候是确定不了的,只有函数执行的时候才能确定this到底指向谁,实际上this的最终指向的是 ...
- js原型链的看法
原型链 对象 对象: 1,函数对象:由function创造出来的函数 2,普通对象:除开函数对象之外的对象,都是普通对象 **即普通对象obj是构造函数Object的一个实例,因此: obj.__pr ...
- Python学习日记(三十四) Mysql数据库篇 二
外键(Foreign Key) 如果今天有一张表上面有很多职务的信息 我们可以通过使用外键的方式去将两张表产生关联 这样的好处能够节省空间,比方说你今天的职务名称很长,在一张表中就要重复的去写这个职务 ...
- vue---axios实现数据交互与跨域问题
1. 通过axios实现数据请求 vue.js默认没有提供ajax功能的. 所以使用vue的时候,一般都会使用axios的插件来实现ajax与后端服务器的数据交互. 注意,axios本质上就是java ...
- VMware15.5版本安装Windows_Server_2008_R2
VMware15.5版本安装Windows_Server_2008_R2一.从VMware15.5中新建虚拟机1.打开VMware,在首页面选择创建新的虚拟机. 2.新建虚拟机向导,选择典型配置. 3 ...
- 卓越Code第一次作业
第一次团队作业 序言 所属课程 https://edu.cnblogs.com/campus/xnsy/2019autumnsystemanalysisanddesign 作业要求 https://w ...
- springmvc手动获取bean
@Service @Lazy(false) public class SpringContextHolder implements ApplicationContextAware, Disposabl ...
- 5、Python之包管理工具pip
pip提供我们各色各样的软件(第三方库),而这些第三方库又可以给我们实现各种各样不同的功能,科学计算.画图.操作文件.聊天-- 我们可以通过Cmd终端.Pycharm.Jupyter三种平台使用pip ...