[原创]python爬虫之BeautifulSoup,爬取网页上所有图片标题并存储到本地文件
from bs4 import BeautifulSoup
import requests
import re
import os
r = requests.get("https://re.jd.com/search?keyword=%E6%B0%B4%E6%9E%9C%20%E7%BD%91&keywordid=44195495794&re_dcp=202m0QjIIg==&traffic_source=1004&test=1&enc=utf8&cu=true&utm_source=baidu-search&utm_medium=cpc&utm_campaign=t_262767352_baidusearch&utm_term=44195495794_0_32d58cbc7f0f40e08d64a09fbc8c95c4")
result = r.content
# print(result)
soup = BeautifulSoup(result,"html.parser")
# print(soup.script.text)
souptext = soup.find(type='text/javascript').text
# print(souptext) pattern3 =re.compile(r'\"ad_title_text\":\"(.*?\"),\"image_url\":\"(.*?\.(jpg|png))\"')
patternresult3 = pattern3.findall(souptext)
print(patternresult3) j = 0
for i in patternresult3:
j = j+1
title = i[0].replace(' ','').replace('\"','').replace('/','')
with open(os.getcwd()+'\\jpg\\'+title+str(j)+"."+i[2],"wb") as f: #在执行代码前,需要先创建一个jpg的目录,os.getcwd()用来获取当前目录
f.write(requests.get("https://img1.360buyimg.com/n6/"+i[1]).content)
运行结果如下:
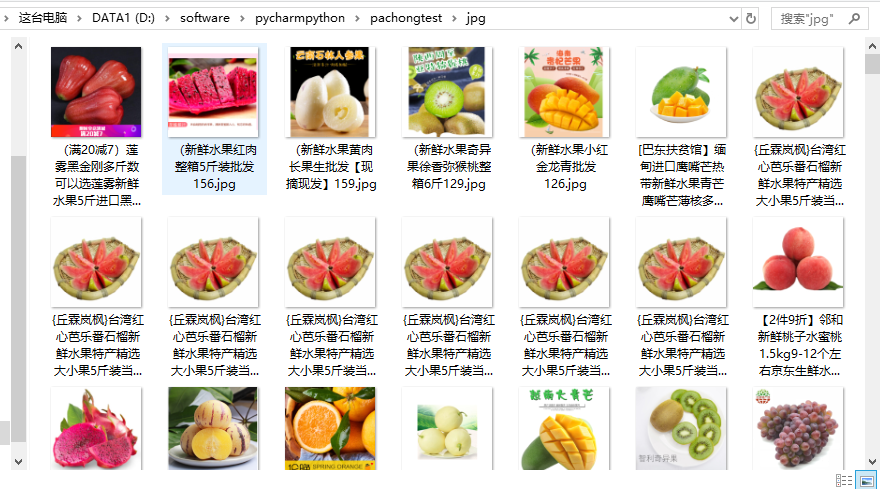
[原创]python爬虫之BeautifulSoup,爬取网页上所有图片标题并存储到本地文件的更多相关文章
- python 爬虫 requests+BeautifulSoup 爬取巨潮资讯公司概况代码实例
第一次写一个算是比较完整的爬虫,自我感觉极差啊,代码low,效率差,也没有保存到本地文件或者数据库,强行使用了一波多线程导致数据顺序发生了变化... 贴在这里,引以为戒吧. # -*- coding: ...
- 原创:Python爬虫实战之爬取美女照片
这个素材是出自小甲鱼的python教程,但源码全部是我原创的,所以,猥琐的不是我 注:没有用header(总会报错),暂时不会正则表达式(马上要学了),以下代码可能些许混乱,不过效果还是可以的. 爬虫 ...
- 原创:Python爬虫实战之爬取代理ip
编程的快乐只有在运行成功的那一刻才知道QAQ 目标网站:https://www.kuaidaili.com/free/inha/ #若有侵权请联系我 因为上面的代理都是http的所以没写这个判断 代 ...
- Python使用urllib,urllib3,requests库+beautifulsoup爬取网页
Python使用urllib/urllib3/requests库+beautifulsoup爬取网页 urllib urllib3 requests 笔者在爬取时遇到的问题 1.结果不全 2.'抓取失 ...
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- Python爬虫实例:爬取B站《工作细胞》短评——异步加载信息的爬取
很多网页的信息都是通过异步加载的,本文就举例讨论下此类网页的抓取. <工作细胞>最近比较火,bilibili 上目前的短评已经有17000多条. 先看分析下页面 右边 li 标签中的就是短 ...
- python爬虫-基础入门-爬取整个网站《1》
python爬虫-基础入门-爬取整个网站<1> 描述: 使用环境:python2.7.15 ,开发工具:pycharm,现爬取一个网站页面(http://www.baidu.com)所有数 ...
随机推荐
- c# 第33节 类的封装--访问修饰符
本节内容: 1:封装的简介 2:封装怎么实现 3:访问修饰符 1:封装的简介 2:封装怎么实现 3:访问修饰符 4:访问修饰符注意点
- leetcode 贪心算法
贪心算法中,是以自顶向下的方式使用最优子结构,贪心算法会先做选择,在当时看起来是最优的选择,然后再求解一个结果的子问题. 贪心算法是使所做的选择看起来都是当前最佳的,期望通过所做的局部最优选择来产生一 ...
- python copy和deepcopy
Python FAQ2:赋值.浅拷贝.深拷贝的区别? 发表于 2014-08-15 | 分类于 Lang.-Python | 在写Python过程中,经常会遇到对象的拷贝,如果不理解浅拷 ...
- 《LinuxTools》
https://zhuanlan.zhihu.com/p/37196870 Linux基础 Linux工具进阶 工具参考篇 1. gdb 调试利器 2. ldd 查看程序依赖库 3. lsof 一切皆 ...
- 牛客小白月赛18 Forsaken喜欢数论
牛客小白月赛18 Forsaken喜欢数论 题目传送门直接点标题 Forsaken有一个有趣的数论函数.对于任意一个数xxx,f(x)f(x)f(x)会返回xxx的最小质因子.如果这个数没有最小质 ...
- Python进阶-XVI 继承 单继承 多继承
一.初识继承 1.引入继承 class A(object): pass # 父类,基类,超类 class B: pass # 父类,基类,超类 class A_son(A, B): pass # 子类 ...
- 端口转发之 nc
nc使用方法: Ncat 7.50 ( https://nmap.org/ncat ) Usage: ncat [options] [hostname] [port] Options taking a ...
- h5移动端页面强制横屏
说明:这个的原文章来自于https://www.jianshu.com/p/9c3264f4a405 ,我做点点补充 ,谢谢原链接的小姐姐 最近公司是要我做一个h5的小视频,因为是视频接视频,并且 ...
- telnet: Unable to connect to remote host: Connection refused
问题描述: telnet: Unable to connect to remote host: Connection refused 已解决,需要安装telent 服务,请查看下方的链接文章: htt ...
- 小小见解之python循环依赖
a.py from b import b print '---------this is module a.py----------' def a(): print "hello, a&qu ...