使用pandas库实现csv行和列的获取
1、读取csv
import pandas as pd
df = pd.read_csv('路径/py.csv')
2、取行号
index_num = df.index
举个例子:
import pandas as pd
df = pd.read_csv('./IP2LOCATION.csv',encoding= 'utf-8')
index_num = df.index
print(index_num)

3、取出行
import pandas as pd
df = pd.read_csv('./IP2LOCATION.csv',encoding= 'utf-8',header=None)
# print(type(df))
df.columns = ['a','b','c','d','e','f']
# 获取行数
# index_num = df.index
# print(index_num)
# 取出某一行
# row_data_1 = df.iloc[0]
# row_data_2 = df.iloc[[0]]
# 取出连续的行
# row_data_3 = df.iloc[0:2]
# row_data_4 = df[0:2]
# 取出不连续的行
# row_data_5 = df.iloc[[0,2]]
# print(row_data_5)
只取一行
可以使用df.iloc[行号],得到的是series
也可以使用df.iloc[[行号]],得到的是dataframe
row_data_1 = df.iloc[0] # pandas series
row_data_2 = df.iloc[[0]] # dataframe
loc是显式的索引,默认第一行的行号为1,行号从1计数
iloc是隐式的索引,默认第一行的行号为0,行号从0计数
row_data_1
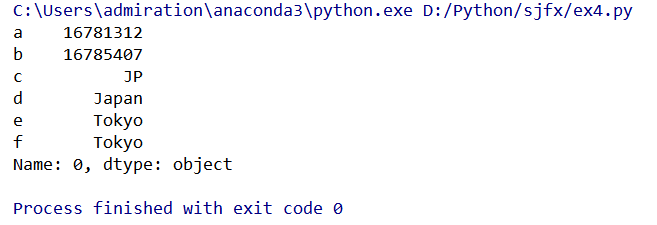
row_data_2

取连续的几行
可以用df.iloc[行号:行号],也可以用df[行号:行号],得到的都是dataframe
row_data_3 = df.iloc[0:2]
row_data_3 = df[0:2]
row_data_3

row_data_4

取出不连续的几行
使用df.iloc[[行号,行号]],特别注意是两个方括号,中间是逗号,得到的是dataframe
row_data_5 = df.iloc[[0,2]]
row_data_5

4、取出列
import pandas as pd
df = pd.read_csv('./IP2LOCATION.csv',encoding= 'utf-8',header=None)
# print(type(df))
df.columns = ['a','b','c','d','e','f']
# 只取一列
# col_data_1 = df['a'] # 单独一列是个series
# col_data_2 = df.loc[:,'a'] # 同上,但比较复杂,一般不用
# col_data_3 = df.iloc[:,0] # 同上,可以在不知道列名的时候用
#
# col_data_4 = df[['a']] # 单独一列是个df
# col_data_5 = df.loc[:,['a']] # 同上,但比较复杂,一般不用
# col_data_6 = df.iloc[:,[0]] # 同上,可以在不知道列名的时候用
# print(col_data_4)
# 获取指定的几列
# cols_data_1 = df[['a','b']] # DataFrame, 指定某几列,直接用列名
# cols_data_2 = df.loc[:,['a','b']] # 同上,但比较复杂,一般不用
# cols_data_3 = df.iloc[:,[0,2]] # 同上,可以在不知道列名的时候用
# print(cols_data_1)
# 获取指定的连续列
# cols_data_4 = df.loc[:,'a':'d'] # 指定连续列,用列名
# cols_data_5 = df.iloc[:,0:4] # 指定连续列,用数字
# print(cols_data_4)
只取一列
col_data_1 = df['a']# 单独一列是个seriescol_data_2 = df.loc[:,'a']# 同上,但比较复杂,一般不用col_data_3 = df.iloc[:,0] # 同上,可以在不知道列名的时候用
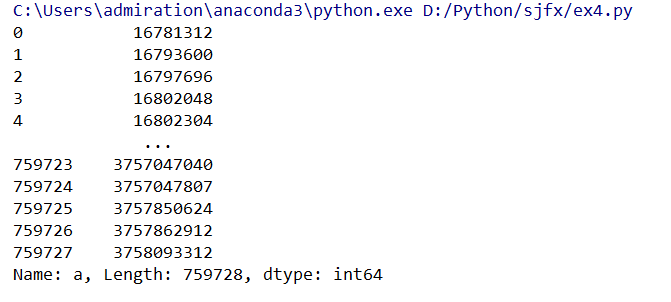
以上三种均为只取一列的操作,并且是等效的,获取的都是series类型
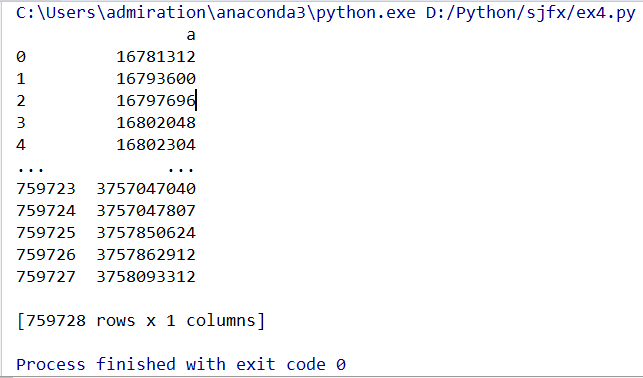
下面三种也是等效的,但是获取的是dataframe类型
col_data_4 = df[['a']] # 单独一列是个df
col_data_5 = df.loc[:,['a']] # 同上,但比较复杂,一般不用
col_data_6 = df.iloc[:,[0]] # 同上,可以在不知道列名的时候用
取指定的某几列
cols_data_1 = df[['a','b']] # DataFrame, 指定某几列,直接用列名
cols_data_2 = df.loc[:,['a','b']] # 同上,但比较复杂,一般不用
cols_data_3 = df.iloc[:,[0,2]] # 同上,可以在不知道列名的时候用

获取指定的连续几列
cols_data_4 = df.loc[:,'a':'d'] # 指定连续列,用列名
cols_data_5 = df.iloc[:,0:4] # 指定连续列,用数字
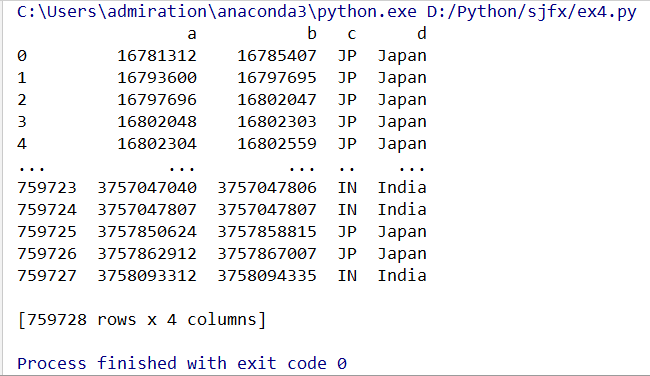
5、取指定行和列
import pandas as pd
df = pd.read_csv('./IP2LOCATION.csv',encoding= 'utf-8',header=None)
# print(type(df))
df.columns = ['a','b','c','d','e','f']
# 获取指定行列
# 第一种,列索引用数字表示
# data_1 = df.iloc[[1,3],[0]]
# data_2 = df.iloc[[1,3],0]
# data_3 = df.iloc[[1,3],1:3]
# data_4 = df.iloc[[1,3],[1,3]]
# print(data_4)
# 第二种,列索引直接引用列名
# data_5 = df.loc[1,['a','d']]
# data_6 = df.loc[[1],['a','d']]
# data_7 = df.loc[[1,3],'a':'d']
# data_8 = df.loc[[1,3],['a','d']]
# print(data_8)
列索引用数字表示
第一种情况是列索引用数字表示, df.iloc[行索引表达,列索引表达],规则跟上面行索引一模一样。
data_1 = df.iloc[[1,3],[0]]

data_2 = df.iloc[[1,3],0] # series
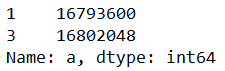
data_3 = df.iloc[[1,3],1:3]

data_4 = df.iloc[[1,3],[1,3]]
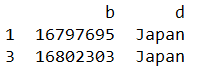
列索引直接引列名
第二种情况是列索引直接引列名(行索引不存在这个问题,因为pandas没有所谓'行名'),就要用df.loc[行索引,列名索引。
data_5 = df.loc[1,['a','d']] # series

data_6 = df.loc[[1],['a','d']]
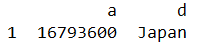
data_7 = df.loc[[1,3],'a':'d']

data_8 = df.loc[[1,3],['a','d']]

使用pandas库实现csv行和列的获取的更多相关文章
- POI教程之第二讲:创建一个时间格式的单元格,处理不同内容格式的单元格,遍历工作簿的行和列并获取单元格内容,文本提取
第二讲 1.创建一个时间格式的单元格 Workbook wb=new HSSFWorkbook(); // 定义一个新的工作簿 Sheet sheet=wb.createSheet("第一个 ...
- python的pandas库读取csv
首先建立test.csv原始数据,内容如下 时间,地点 一月,北京 二月,上海 三月,广东 四月,深圳 五月,河南 六月,郑州 七月,新密 八月,大连 九月,盘锦 十月,沈阳 十一月,武汉 十二月,南 ...
- 用pandas库对csv文件中的文本数据进行分析处理
#数据分析 import pandas import csv old_path = r'd:\2000W\200W-400W.csv' f = open(old_path,'r',encoding=' ...
- Python之文件读写(csv文件,CSV库,Pandas库)
前言 一.Python文件读取 二.读取CSV文件 一.Python文件读取 1. open函数是内置函数之with操作 - 关于路径设置的问题斜杠设置成D:\\文件夹\\文件或是D:/文件夹/文件 ...
- Python之使用Pandas库实现MySQL数据库的读写
本次分享将介绍如何在Python中使用Pandas库实现MySQL数据库的读写.首先我们需要了解点ORM方面的知识. ORM技术 对象关系映射技术,即ORM(Object-Relational ...
- python做数据分析pandas库介绍之DataFrame基本操作
怎样删除list中空字符? 最简单的方法:new_list = [ x for x in li if x != '' ] 这一部分主要学习pandas中基于前面两种数据结构的基本操作. 设有DataF ...
- Pandas库常用函数和操作
1. DataFrame 处理缺失值 dropna() df2.dropna(axis=0, how='any', subset=[u'ToC'], inplace=True) 把在ToC列有缺失值 ...
- python pandas库——pivot使用心得
python pandas库——pivot使用心得 2017年12月14日 17:07:06 阅读数:364 最近在做基于python的数据分析工作,引用第三方数据分析库——pandas(versio ...
- 建议42:使用pandas处理大型CSV文件
# -*- coding:utf-8 -*- ''' CSV 常用API 1)reader(csvfile[, dialect='excel'][, fmtparam]),主要用于CSV 文件的读取, ...
随机推荐
- Springboot以Tomcat为容器实现http重定向到https的两种方式
1 简介 本文将介绍在Springboot中如何通过代码实现Http到Https的重定向,本文仅讲解Tomcat作为容器的情况,其它容器将在以后一一道来. 建议阅读之前的相关文章: (1) Sprin ...
- 理解分布式一致性:Raft协议
理解分布式一致性:Raft协议 什么是分布式一致性 Leader选举 日志复制流程 term选举周期 timeout 选举和选举timeout 选举分裂 日志复制和心跳timeout 在分布式系统中, ...
- 【三剑客】awk命令
前言 awk是一种很棒的语言,它适合文本处理和报表生成. 模式扫描和处理.处理文本流. awk不仅仅是Linux系统中的一个命令,而是一种编程语言,可以用来处理数据和生成报告. 处理的数据: 可以是一 ...
- 酷狗音乐快速转换MP3格式的方法
喜欢听音乐的朋友们,散步跑步的时候都是随身听,音乐可以给人带来力量,让人心情愉悦,有时候甚至还可以让我们忘记烦恼和忧愁,是一种不错的解压方式,所以热爱运动的宝宝们是离不来音乐的陪伴的,这样说来随身听的 ...
- Docker 快速安装Jenkins完美教程 (亲测采坑后详细步骤)
一.前言 有人问,为什么要用Jenkins,在一些中小型企业?我说下我以前开发的痛点,每次开发一个项目完成后,需要打包部署,可能没有专门的运维人员,只能开发人员去把项目打成一个war包,可能这个项目已 ...
- SpringBoot返回JSON日期格式问题
SpringBoot中默认返回的日期格式类似于这样: "birth": 1537407384500 或者是这样: "createTime": "201 ...
- 【XR-3】核心城市(树直径)
[XR-3]核心城市 这题真的难啊......... k个核心城市太麻烦,我们假设先找一个核心城市,应该放在哪里? \(任意取一个点,它的最远端是直径的端点.\) \(所以当这个点是直径的中点时,可以 ...
- js和jq的获取焦点失去焦点写法
- 一文教你快速学会在matlab的simulink中调用C语言进行仿真
本文介绍如何在matlab的simulink中嵌入C语言进行多输入多输出的仿真:matlab版本位2015b: 创作不易,如果本文帮到了您: 如果本文帮到了您,请帮忙点个赞
- Linux内核驱动学习(八)GPIO驱动模拟输出PWM
文章目录 前言 原理图 IO模拟输出PWM 设备树 驱动端 调试信息 实验结果 附录 前言 上一篇的学习中介绍了如何在用户空间直接操作GPIO,并写了一个脚本可以产生PWM.本篇的学习会将写一个驱动操 ...