scrapy框架爬取蜂鸟网的人像图片
今天有点无聊,本来打算去蜂鸟网爬点图片存起来显得自己有点内涵,但是当我点开人像的时候就被里面的小姐姐所吸引了,下面就是整个爬图片的思路和过程了
第一步:先创建一个爬虫项目
scrapy startproject Feng

然后进入目录里面 创建爬虫

好了 爬虫项目创建完成了,接下来该去网页分析数据了
首先进入蜂鸟网 找到人像摄影页面的网址添加到爬虫的start_urls里面
然后利用开发者工具分析网页页面的图片数据
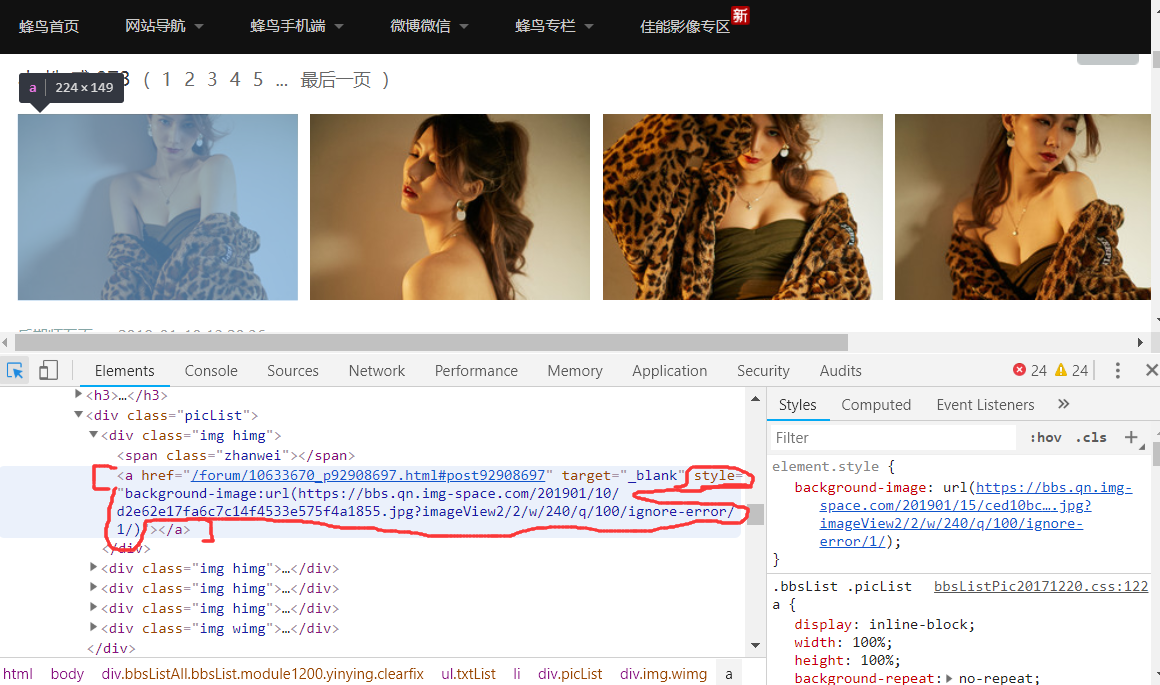
发现图片的地址是在a标签里面的style属性里面的background-image:url,然后根据xpath找到该页面的所有人像图片的a标签里的style属性,获得的属性值有多余的background-image:url(),利用字符串的切片将这些去除掉,就可以获得完整的图片url
这样我就获取到了该页面所有的人像图片的url
然后在settings.py文件里面配置反爬机制
然后再引用scrapy.pipelines.images.ImagesPipeline
并给图片一个存储地址 IMAGE_STORE='./images' 即在当前目录下的images文件夹里面
然后再items.py文件里面设置对象
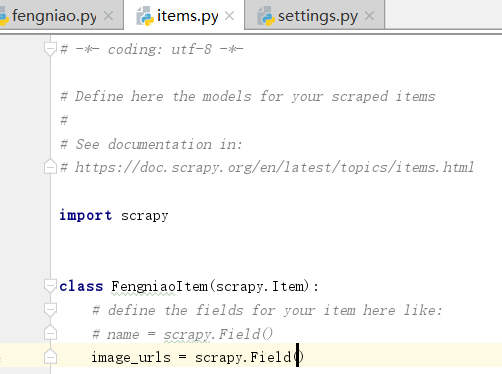
在parse里面导入items,然后创建item对象,然后将取到的图片地址赋给item对象在yield item
这样就可以下载当前页面的图片了
下面的翻页就是获取下一页的链接的xpath,用scrapy中的Request方法访问下一页,callback到parse就能循环翻页并下载
# -*- coding: utf-8 -*-
import scrapy
from ..items import FengniaoItem class FengniaoSpider(scrapy.Spider):
name = 'fengniao'
allowed_domains = ['fengniao.com']
start_urls = ['http://bbs.fengniao.com/forum/forum_101.html'] def parse(self, response):
image = response.xpath('//li/div/div/a/@style').extract()
for i in image:
item = FengniaoItem()
img = i[21:-1]
item['image_urls'] = [img]
yield item
nextpage = response.xpath('//a[text()="下一页"]/@href') .extract_first()
yield scrapy.Request(url=nextpage,callback=self.parse,method='GET',dont_filter=True)
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html import scrapy class FengniaoItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
image_urls = scrapy.Field()
# -*- coding: utf-8 -*- # Scrapy settings for Fengniao project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/latest/topics/settings.html
# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html BOT_NAME = 'Fengniao' SPIDER_MODULES = ['Fengniao.spiders']
NEWSPIDER_MODULE = 'Fengniao.spiders' # Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Fengniao (+http://www.yourdomain.com)' # Obey robots.txt rules
ROBOTSTXT_OBEY = False # Configure maximum concurrent requests performed by Scrapy (default: 16)
CONCURRENT_REQUESTS = 32 # Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16 # Disable cookies (enabled by default)
COOKIES_ENABLED = True # Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False # Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
} # Enable or disable spider middlewares
# See https://doc.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'Fengniao.middlewares.FengniaoSpiderMiddleware': 543,
#} # Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'Fengniao.middlewares.FengniaoDownloaderMiddleware': 543,
#} # Enable or disable extensions
# See https://doc.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#} # Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'Fengniao.pipelines.FengniaoPipeline': 300,
'scrapy.pipelines.images.ImagesPipeline':1,
}
IMAGES_STORE = './images' # Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False # Enable and configure HTTP caching (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage' LOG_FILE = 'test.log'
FEED_EXPORT_ENCODING='utf-8'
然后下面就是抓下来的部分图片
scrapy框架爬取蜂鸟网的人像图片的更多相关文章
- 使用scrapy框架爬取自己的博文(2)
之前写了一篇用scrapy框架爬取自己博文的博客,后来发现对于中文的处理一直有问题- - 显示的时候 [u'python\u4e0b\u722c\u67d0\u4e2a\u7f51\u9875\u76 ...
- scrapy框架爬取笔趣阁完整版
继续上一篇,这一次的爬取了小说内容 pipelines.py import csv class ScrapytestPipeline(object): # 爬虫文件中提取数据的方法每yield一次it ...
- scrapy框架爬取笔趣阁
笔趣阁是很好爬的网站了,这里简单爬取了全部小说链接和每本的全部章节链接,还想爬取章节内容在biquge.py里在加一个爬取循环,在pipelines.py添加保存函数即可 1 创建一个scrapy项目 ...
- scrapy框架爬取妹子图片
首先,建立一个项目#可在github账户下载完整代码:https://github.com/connordb/scrapy-jiandan2 scrapy startproject jiandan2 ...
- 爬虫 Scrapy框架 爬取图虫图片并下载
items.py,根据需求确定自己的数据要求 # -*- coding: utf-8 -*- # Define here the models for your scraped items # # S ...
- 基于python的scrapy框架爬取豆瓣电影及其可视化
1.Scrapy框架介绍 主要介绍,spiders,engine,scheduler,downloader,Item pipeline scrapy常见命令如下: 对应在scrapy文件中有,自己增加 ...
- scrapy框架爬取豆瓣读书(1)
1.scrapy框架 Scrapy,Python开发的一个快速.高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据.Scrapy用途广泛,可以用于数据挖掘.监测和自动化测试 ...
- scrapy框架爬取糗妹妹网站妹子图分类的所有图片
爬取所有图片,一个页面的图片建一个文件夹.难点,图片中有不少.gif图片,需要重写下载规则, 创建scrapy项目 scrapy startproject qiumeimei 创建爬虫应用 cd qi ...
- Python使用Scrapy框架爬取数据存入CSV文件(Python爬虫实战4)
1. Scrapy框架 Scrapy是python下实现爬虫功能的框架,能够将数据解析.数据处理.数据存储合为一体功能的爬虫框架. 2. Scrapy安装 1. 安装依赖包 yum install g ...
随机推荐
- BEC listen and translation exercise 45
So the Counselling Services we offer deal with any problems arising from your studies or in your lif ...
- JSTL前台报错
报错信息: jsp页面报错 Can not find the tag library descriptor for "http://java.sun.com/jsp/jstl/core&qu ...
- OPcache
1.介绍 OPcache 通过将 PHP 脚本预编译的字节码存储到共享内存中来提升 PHP 的性能, 存储预编译字节码的好处就是 省去了每次加载和解析 PHP 脚本的开销 2.配置 2.1 opcac ...
- UVA11059 - Maximum Product
1.题目名称 Maximum Product 2.题目地址 https://uva.onlinejudge.org/index.php?option=com_onlinejudge&Itemi ...
- w3c上的SQL 教程---基本语法 语句学习
SQL 教程路径:http://www.w3school.com.cn/sql/index.asp
- bzoj 2044 三维导弹拦截——DAG最小路径覆盖(二分图)
题目:https://www.lydsy.com/JudgeOnline/problem.php?id=2044 还以为是CDQ.发现自己不会三维以上的…… 第一问可以n^2.然后是求最长不下降子序列 ...
- 分享一个js技巧!判断一个变量chat_websocket是否存在。
注意!!! 判断一个变量chat_websocket是否存在:if( "undefined" == typeof(chat_websocket) || null == chat_w ...
- 【转】 Pro Android学习笔记(二九):用户界面和控制(17):include和merge
目录(?)[-] xml控件代码重用include xml控件代码重用merge 横屏和竖屏landsacpe portrait xml控件代码重用:include 如果我们定义一个控件,需要在不同的 ...
- js检测对象属性
In:(检测自身及原型属性) var o={x:1}; "x" in o; //true,自有属性存在 "y" in o; //false "toSt ...
- Project Online JS 添加Ribbon按钮
var Projects = Projects || {}; (function () { Projects.ribbonButtonClick = function (name) { var pro ...