搭建HDFS HA
搭建HDFS HA
1.服务器角色规划
| hd-01(192.168.1.99) | hd-02 (192.168.1.100) | hd-03 (192.168.1.101) |
|---|---|---|
| NameNode | NameNode | |
| Zookeeper | Zookeeper | Zookeeper |
| DataNode | DataNode | DataNode |
| ResourceManage | ResourceManage | |
| NodeManager | NodeManager | NodeManager |
2.搭建
解压Hadoop 2.8.5
tar -zxvf hadoop-2.8.5.tar.gz
配置Hadoop JDK路径
# 修改hadoop-env.sh、mapred-env.sh、yarn-env.sh文件中的JDK路径
export JAVA_HOME="/opt/jdk1.8.0_112"
配置hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<!-- 为namenode集群定义一个services name -->
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<property>
<!-- nameservice 包含哪些namenode,为各个namenode起名 -->
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<property>
<!-- 名为nn1的namenode 的rpc地址和端口号,rpc用来和datanode通讯 -->
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>hd-01:8020</value>
</property>
<property>
<!-- 名为nn2的namenode 的rpc地址和端口号,rpc用来和datanode通讯 -->
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>hd-02:8020</value>
</property>
<property>
<!-- 名为nn1的namenode 的http地址和端口号,web客户端 -->
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>hd-01:50070</value>
</property>
<property>
<!--名为nn2的namenode 的http地址和端口号,web客户端 -->
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>hd-02:50070</value>
</property>
<property>
<!-- namenode间用于共享编辑日志的journal节点列表 -->
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hd-01:8485;hd-02:8485;hd-03:8485/ns1</value>
</property>
<property>
<!-- journalnode 上用于存放edits日志的目录 -->
<name>dfs.journalnode.edits.dir</name>
<value>/opt/hadoop-2.8.5/tmp/data/dfs/jn</value>
</property>
<property>
<!-- 客户端连接可用状态的NameNode所用的代理类 -->
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<!-- -->
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
</configuration>
配置core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<!-- hdfs 地址,ha中是连接到nameservice -->
<name>fs.defaultFS</name>
<value>hdfs://ns1</value>
</property>
<property>
<!-- -->
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-2.8.5/data/tmp</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>hd-01:2181,hd-02:2181,hd-03:2181</value>
</property>
</configuration>
配置slaves文件
[root@hd-01 opt]# cat /opt/hadoop-2.8.5/etc/hadoop/slaves
hd-01
hd-02
hd-03
分发到其他节点
scp -r /opt/hadoop-2.8.5/ hd-01:/opt/
scp -r /opt/hadoop-2.8.5/ hd-02:/opt/
三台机器分别启动Journalnode
# 三台机器分别给hadoop赋权
chown -R hadoop:hadoop /opt/hadoop-2.8.5/
# 启动,三台机器分别执行
sbin/hadoop-daemon.sh start journalnode
# JPS命令查看是否启动
jps
在三台节点上启动Zookeeper
# 启动,三台机器分别执行
bin/zkServer.sh start
# 查看zk状态
bin/zkServer.sh status
启动NameNode
# 启动之前先格式化NameNode
# 1.格式话hd-01
bin/hdfs namenode -format
# 启动hd-01
sbin/hadoop-daemon.sh start namenode
# 2.格式化hd-02
bin/hdfs namenode -bootstrapStandby
# 启动hd-02
sbin/hadoop-daemon.sh start namenode
查看HDFS Web页面,此时两个NameNode都是standby状态。
切换第一台为active状态:
添加上forcemanual参数,强制将一个NameNode转换为Active状态
bin/hdfs haadmin -transitionToActive nn1
3.配置故障自动转移
利用zookeeper集群实现故障自动转移,在配置故障自动转移之前,要先关闭集群,不能在HDFS运行期间进行配置。
关闭NameNode、DataNode、JournalNode、zookeeper
# 三台分别到对应的路径执行
sbin/hadoop-daemon.sh stop namenode
sbin/hadoop-daemon.sh stop datanode
sbin/hadoop-daemon.sh stop journalnode
bin/zkServer.sh stop
修改hdfs-site.xml
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
修改core-site.xml
<property>
<name>ha.zookeeper.quorum</name>
<value>hd-01:2181,hd-02:2181,hd-03:2181</value>
</property>
将hdfs-site.xml和core-site.xml分发到其他机器
scp /opt/hadoop-2.8.5/etc/hadoop/hdfs-site.xml hd-02:/opt/hadoop-2.8.5/etc/hadoop/
scp /opt/hadoop-2.8.5/etc/hadoop/core-site.xml hd-02:/opt/hadoop-2.8.5/etc/hadoop/
三台机器启动zookeeper
bin/zkServer.sh start
创建一个zNode
cd /opt/hadoop-2.8.5/
bin/hdfs zkfc -formatZK
启动HDFS、JournalNode、zkfc
# vm-01上执行
cd /opt/hadoop-2.8.5/
sbin/start-dfs.sh
4.测试故障自动转移和数据是否共享
# 在hd-01上上传文件
cd /opt/hadoop-2.8.5/
bin/hdfs dfs -put /opt/data/wc.input /
在http://192.168.1.99:50070/explorer.html#/上可以看到已经上传的文件
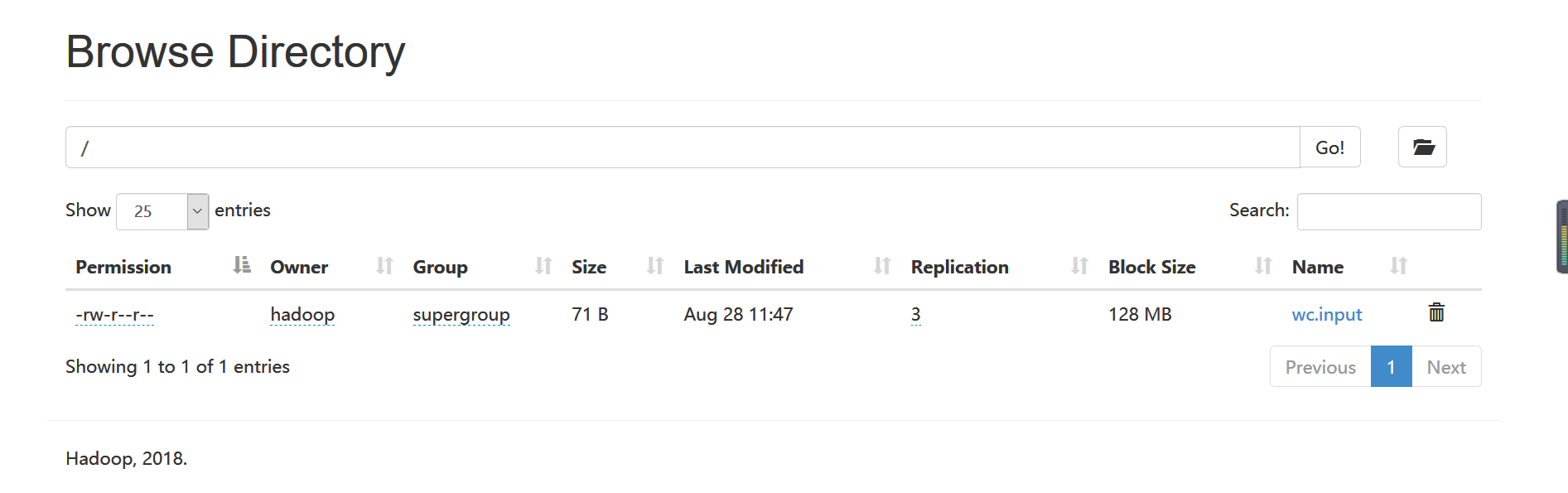
将hd-01上的NameNode杀掉
jps | grep NameNode | awk '{print $1}' | xargs kill -9
在nn2上查看是否看见文件

已经验证,已经实现nn1和nn2之间的文件同步和故障自动转移。
原文链接:
https://blog.csdn.net/hliq5399/article/details/78193113
搭建HDFS HA的更多相关文章
- 使用Cloudera Manager搭建zookeeper集群及HDFS HA实战篇
使用Cloudera Manager搭建zookeeper集群及HDFS HA实战篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.使用Cloudera Manager搭建zo ...
- 【Hadoop学习之四】HDFS HA搭建(QJM)
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk8 hadoop-3.1.1 由于NameNode对于整个HDF ...
- 基于HBase0.98.13搭建HBase HA分布式集群
在hadoop2.6.0分布式集群上搭建hbase ha分布式集群.搭建hadoop2.6.0分布式集群,请参考“基于hadoop2.6.0搭建5个节点的分布式集群”.下面我们开始啦 1.规划 1.主 ...
- 使用QJM部署HDFS HA集群
一.所需软件 1. JDK版本 下载地址:http://www.oracle.com/technetwork/java/javase/index.html 版本: jdk-7u79-linux-x64 ...
- Hadoop 5、HDFS HA 和 YARN
Hadoop 2.0 产生的背景Hadoop 1.0 中HDFS和MapReduce存在高可用和扩展方面的问题 HDFS存在的问题 NameNode单点故障,难以用于在线场景 NameNode压力过大 ...
- [转]HDFS HA 部署安装
1. HDFS 2.0 基本概念 相比于 Hadoop 1.0,Hadoop 2.0 中的 HDFS 增加了两个重大特性,HA 和 Federaion.HA 即为 High Availability, ...
- HDFS HA架构以及源代码引导
HA体系架构 相关知识介绍 HDFS master/slave架构,HDFS节点分为NameNode节点和DataNode节点. NameNode存有HDFS的元数据:主要由FSImage和EditL ...
- 【Zookeeper】利用zookeeper搭建Hdoop HA高可用
HA概述 所谓HA(high available),即高可用(7*24小时不中断服务). 实现高可用最关键的策略是消除单点故障.HA严格来说应该分成各个组件的HA机制:HDFS的HA和YARN的HA. ...
- Hadoop【Hadoop-HA搭建(HDFS、YARN)】
目录 0.HDFS-HA的工作机制 1. HDFS-HA集群配置 1.1 环境准备 1.2 规划集群 1.3 配置Zookeeper集群 2. 配置HDFS-HA集群 3. 启动HDFS-HA集群 4 ...
随机推荐
- input checkbox 禁止选中/修改
input checkbox 禁止选中 <input type="checkbox" onclick="return false;" /> inp ...
- CDH5..4.7+phoenix实现查询HBase异常:java.sql.SQLException: ERROR 1102 (XCL02): Cannot get all table regions
基础环境是用CM 安装的cdh5.4.7,phoenix使用的版本是phoenix-4.5.2-HBase-1.0-bin. 出现异常信息:java.sql.SQLException: ERROR 1 ...
- [待解决]报错:JSON parse error: Unexpected character
{"code":"9999","message":"JSON parse error: Unexpected character ...
- 【洛谷】P1229快速幂
题目链接:https://www.luogu.org/problemnew/show/P1226 题意:求b^p % m之后的结果 题解:快速幂模板 代码: #include<iostream& ...
- opencv2.4.9+vs2012安装配置
需要下载并安装vs2012 http://pan.baidu.com/s/1qXP76CO 第一次启动会提示要求输入激活序列号,请输入:YKCW6-BPFPF-BT8C9-7DCTH-QXG ...
- 【胡策篇】题解 (UOJ 192 + CF938G + SPOJ DIVCNT2)
和泉纱雾与烟花大会 题目来源: UOJ 192 最强跳蚤 (只改了数据范围) 官方题解: 在这里哦~(说的很详细了 我都没啥好说的了) 题目大意: 求树上各边权乘积是完全平方数的路径数量. 这种从\( ...
- python 爬取豆瓣电影短评并wordcloud生成词云图
最近学到数据可视化到了词云图,正好学到爬虫,各种爬网站 [实验名称] 爬取豆瓣电影<千与千寻>的评论并生成词云 1. 利用爬虫获得电影评论的文本数据 2. 处理文本数据生成词云图 第一步, ...
- 七牛云-C#SDK-上传-前期准备
1.创建一个asp.net core MVC 程序(这里随便) 这是一个空的程序 2.创建UploadController 3.添加引用 Install-Package Newtonsoft.Json ...
- leetcood学习笔记-168-excel表列名称
题目描述: 方法一:asiic码 class Solution: def convertToTitle(self, n: int) -> str: if (n-1)//26 == 0: retu ...
- leetcood学习笔记-203-移除链表元素
题目描述: 方法:#在改pre链表时 head中的值也改变 class Solution(object): def removeElements(self, head, val): "&qu ...